Table of Contents
Featured Snippets that Answer Questions
Google shows several different types of featured snippets in search results. One type uses answer boxes providing answers to express or implied questions in queries. Those answer boxes sometimes show only facts as answers, and sometimes they offer extended textual answer passages in response to a query. I’ve written several posts recently about answer passages that Google shows. This is another about how Google identifies pages with the question from the query and answer passages that respond to questions.
Related Content:
The Google patents about scoring answer passages that I have written about in the past cover different aspects of how Google might score and decide which answer passages to show in response to an answer-seeking query. It’s worth understanding the different aspects as they are set out in those patents.
Does Google Use Schema to Write Answer Passages for Featured Snippets? is about the patent Candidate Answer Passages. This is a look at what answer passages are, how they are scored, and whether they are taken from structured or unstructured data.
Featured Snippet Answer Scores Ranking Signals is about the patent Scoring candidate answer passages. This post is a recent update to a patent about how answer passages are scored. The updated claims in the patent emphasize that both query dependent and query independent signals are used to score answer passages. This updated version of this patent was granted on September 22, 2020.
Adjusting Featured Snippet Answers by Context is about the patent Context scoring adjustments for answer passages. This patent tells us about how answer scores for answer passages might be adjusted based on the context of where they are located on a page – it goes beyond what is contained in the text of an answer to what the page title and headings on the page tell us about the context of an answer.
There is another patent specifically about answer passages which I thought was worth working through and seeing what it had to add to these other patents about answer passages. It was granted in July of 2018. It tells us how it might find questions from the query on pages and textual answers to answer passages.
What are Answer Passages?
This section of the patent description is repeated in some of the other patents on answer passages.
The patent tells us that some searchers are often looking to answer a specific question instead of a list of URLs to pages about a query. Examples from the patent are:
- What the weather is in a particular location
- A current quote for a stock
- The capital of a state
- Etc.
Google replies to some queries by showing a one box result that answers a query. For example, we’ve seen one box results: videos and one box results that were map results. So, a one-box result that is an answer to a question isn’t unusual.
The patent tells us that some answers are ideally explanatory answers, which they tell us are also referred to as “long answers” or “answer passages.” So, for the question query [why is the sky blue], an answer explaining how waves could influence the color of the sky can be helpful.
And they tell us that some answer passages are selected from resources that include text, such as paragraphs, which are relevant to the question and the answer. Sections of the text could be scored, and the section with the best score is selected as an answer.
Weighted Answer Terms for Scoring Answer Passages
The summary of this scoring answer passages patent gives us a breakdown of the process behind it.
The process from this patent involve:
- Accessing data describing a set of resources
- Identifying question phrases in those resources
- For each identified question phrase in a resource, selecting in the resource a section of text subsequent to the question phrase as an answer
- The answer having a number of terms
- Grouping question phrases into groups of question phrases
- For each group, generating from the terms of the answers for each question phrase in the group
- Answer terms and for each answer term
- An answer term weight
- Storing answer terms and answer term weights together with one or more queries
Advantages of Following the Process in this patent:
- Answers can be checked for likely accuracy without prior knowledge of the answer
- A potentially large number of answer text sections for corresponding question phrases can be analyzed, and the contribution of particular answer text passage for answers that are likely to be the most accurate is increased
- The pre-processing of answer text is used to generate weighted term vectors before query time. The use of the weighted term vector at query time provides a lightweight but highly accurate scoring estimate of the accuracy of an answer passage
- This improves the technology of answer generation
- The generation of the term vector facilitates the ability to harness a multitude of available relevant answers, including those excluded from the top-ranked resources for a query, by which the relevance of a candidate answer can be judged
- Long answers that are more likely to satisfy the informational need of users are more likely to surface
This scoring answer passages patent can be found at:
Weighted answer terms for scoring answer passages
Inventors: Yehuda Arie Koren and Lev Finkelstein
Assignee: Google LLC
US Patent: 10,019,513
Granted: July 10, 2018
Filed: August 12, 2015
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, generate answer terms for scoring answer passages. In one aspect, a method includes accessing resource data describing a set of resources, identifying question phrases in the resources, for each identified question phrase in a resource, selecting in the resource a section of text after the question phrase as an answer, the answer having a plurality of terms, grouping the question phrases into groups of question phrases, and for each group: generating, from the terms of the answers for each question phrase in the group, answer terms and for each answer term, an answer term weight, and storing the answer terms and answer term weights in association with one or more queries.
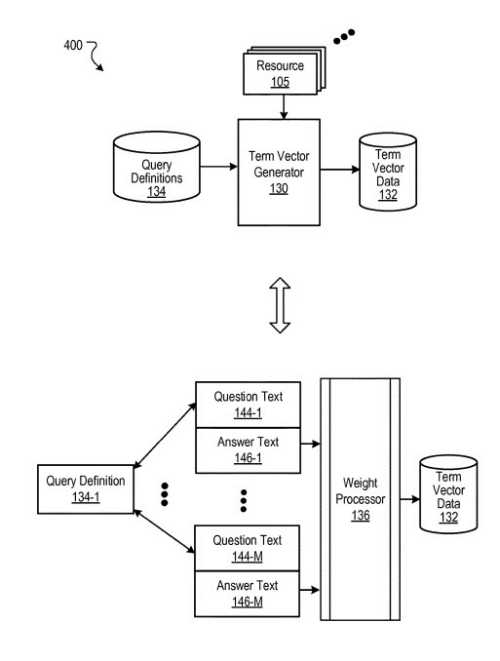
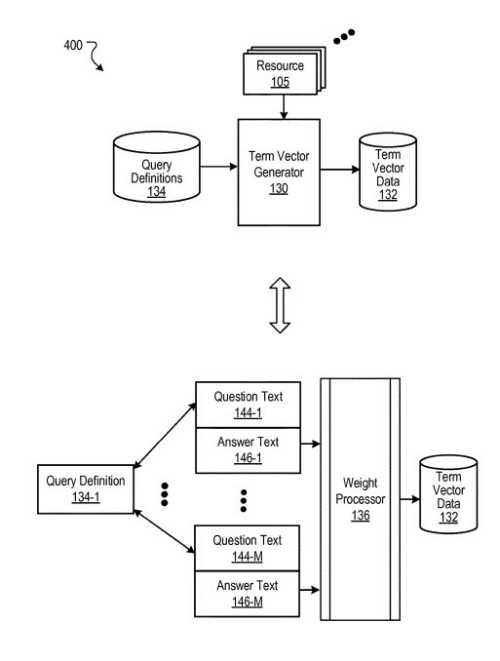
Query Definitions
A term vector generator creates answer terms, and for each answer term, a term weight, and associates those answer terms and term weights with a query definition.
In the example description that follows, the answer terms and term weights are stored in a vector format.
Any appropriate data structure may be used to store the answer terms and term weights.
A query definition may be:
- A single query
- A set of queries that are grouped together as similar queries
- A set of terms that can be expanded for query matching to queries
To create the answer terms and weights for a query definition, the term vector generator accesses resource data describing a set of resources.
Resource data could be a web index, for example.
A term vector generator identifies question phrases in a page, and for each of the identified question phrases, selects a section of text on a page after the question phrase as an answer.
The question phrases are then grouped into separate groups.
The grouping of the question phrases may be done in several ways.
They could be grouped according to a clustering algorithm by which question phrases that are similar to each other are grouped into a cluster.
Or, question phrases matching a query definition may be grouped.
Then, for each group of question phrases, the term vector generator generates, from the terms of the answers, answer terms, and for each answer term, an answer term weight.
The term vector generator then stores the answer terms and answer term weights in association with a query definition as a term vector.
Each query definition may have one corresponding term vector.
When a question query from a user device is received at query time, an answer passage generator receives the query data identifying resources determined to be responsive to the query.
The resources are ordered according to a ranking.
For each resource in a top-ranked subset of the resources, the answer passage generator generates candidate answer passages from the resources.
Each candidate answer passage is eligible to be provided as an answer passage with search results that identify the resources determined to be responsive to the query but separate and distinct from the search results (e.g., as in an “answer box.”)
After the answer passages are generated, an answer passage scorer scores each passage.
Multiple scoring components can be computed, one of which includes an answer term vector score.
To compute the term vector score, the answer passage scorer determines a query definition that matches the received query and selects the answer term vector associated with the query definition.
Using the answer term vector, the answer passage scorer scores each candidate answer passage based on the candidate answer passage, the answer terms, and the term weights of the answer term vector.
The answer passage scorer then selects an answer passage from the candidate answer passages based, in part, on the scoring of the candidate answer passages based on the selected answer term vector.
The selected candidate answer passage is then provided with the search results.
Weighted Answer Terms
Answer terms for many questions are collected from resources and weighted to generate weighted answer terms.
A term vector generator may generate answer term vector data used to evaluate answer passages.
The term vector data is generated before query time (e.g., by a back-end process that generates the term vector data used by the search system during query processing.)
The term vector generator may also be a system operating completely independent of the search system and generates the data for use by the search system.
Evaluation of answer passages using the term vector data by search system is first described to provide a contextual example of how the term vector data may be used in a search operation.
Then, the term vector data generation, which typically occurs before query time, is described.
Search Processing
The Web connects publisher websites, user devices, and a search engine.
It may include many publisher websites and user devices.
Publisher websites include one or more resources associated with a domain and hosted by servers in one or more locations.
Websites are often collections of web pages formatted in HTML and containing text, images, multimedia content, and programming elements, such as scripts.
A resource is any data that a publisher website over the web can provide with a resource address (e.g., a uniform resource locator (URL)).
Resources may be:
- HTML pages
- Electronic documents
- Image files
- Video files
- Audio files
- Feed sources
The resources may include embedded information (e.g., meta information and hyperlinks, and/or embedded instructions, e.g., client-side scripts.)
A user device is an electronic device capable of requesting and receiving resources over the network.
Example user devices include:
- Personal computers
- Mobile communication devices
- Other devices that can send and receive data over the network
A user device typically includes a user application (e.g., a web browser) to facilitate the sending and receiving data over the network.
The web browser can enable users to display and interact with text, images, videos, music, and other information typically located on a web page on a website on the web or a local area network.
To facilitate the searching of these resources, the search engine crawls the publisher websites and indexes the resources provided by the publisher websites.
The index data are stored in a resource index.
The user devices submit search queries to the search engine.
Search queries are submitted in the form of a search request that includes the search request and, optionally, a unique identifier that identifies the user device that submits the request.
The unique identifier can be:
- Data from a cookie stored at the user device
- A user account identifier if the user maintains an account with the search engine
- Some other identifier that identifies the user device or the user using the user device
In response to a search request, the search engine uses the index to identify resources relevant to queries.
The search engine identifies those resources in search results and returns the search results to the user devices in the search results page resource.
A search result is data generated by the search engine identifying a resource or providing information that satisfies a particular search query.
A search result for a resource can include:
- A web page title
- A snippet of text extracted from the web page
- A resource locator for the resource (e.g., the URL of a web page.)
Search results are ranked based on scores related to resources identified by the search results, such as information retrieval (“IR”) scores, and also a separate ranking of each resource relative to other resources (e.g., an authority score, such as PageRank).
According to that order, the search results are ordered according to those scores and provided to a searcher’s device.
The user devices receive the search results pages and render the pages for presentation to users.
In response to the searcher selecting a search result at their device, the device requests the resource identified by the resource locator included in the selected search result.
The website publisher hosting the resource receives a request for the resource from the user’s device and provides the resource to the requesting device.
The queries that are submitted from user devices are stored in query logs.
Selection data for those queries and web pages referenced by the search results and selected by users are also stored in selection logs.
The query logs and the selection logs define search history data that includes data from previous search requests associated with unique identifiers.
The selection logs represent actions that are taken in response to search results provided by the search engine.
Examples of such actions included in those selection logs include clicks on search results.
The query logs and selection logs may be used to map queries submitted by user devices to resources identified in search results and the actions taken by users when presented with the search results in response to the queries.
Data can be associated with the identifiers from the search requests so that a search history for each identifier can be accessed.
Selection logs and query logs can be used by the search engine to determine:
- The respective sequences of queries submitted by the user devices
- The actions taken in response to the queries
- How often the queries have been submitted
Personal Data
This patent tells us that when systems discussed here collect personal information about searchers or may make use of personal information, the searchers may be provided with a way to control whether programs or features collect information about them, their social network, social actions, or activities, profession, or current location), or to control whether and/or how to receive content from the content server that may be more relevant to the user.
Data may be treated so that personally identifiable information is removed.
A searcher’s identity may be treated so that no personally identifiable information can be determined for that searcher, or a user’s geographic location may be generalized where location information is obtained (such as to a city, ZIP code, or state level) so that a particular location of a user cannot be determined.
Thus, the searcher may control how information is collected about the searcher and used by a content server.
Question Queries And Answer Passages
Some queries are in the form of a question or the form of an implicit question.
The query [a distance of the earth to the moon] is in the form of an implicit question, “What is the distance of the earth from the moon?”
A question may also be specific, as in the query [How far away is the moon].
This patent tells us of a query question processor that determines if a query is a query question that can trigger responsive answers.
This query question processor can use several different algorithms to decide whether a query is a question.
Those algorithms could include:
- Language models
- Machine learned processes
- Knowledge graphs
- Grammars
- Combinations of those to determine question queries and answers.
This search system may choose to select candidate answer passages in addition to or instead of answer facts.
For the query [how far away is the moon], an answer fact is 238,900 miles, which is the average distance of the Earth from the moon.
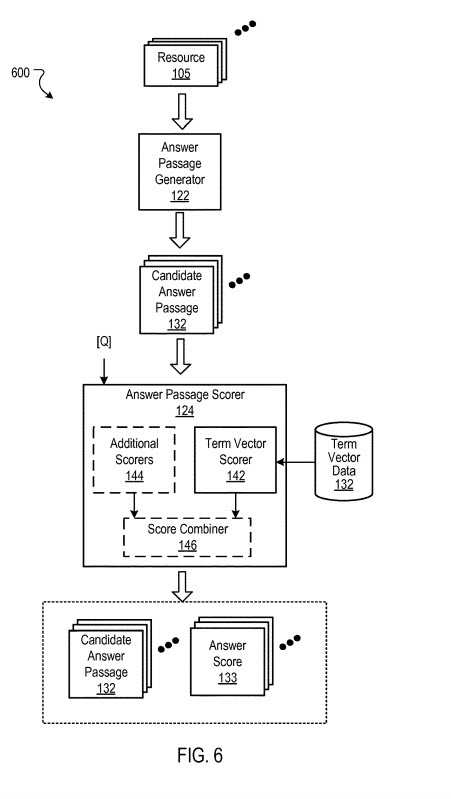
The search system may use an answer passage generator that generates candidate answer passages and an answer passage scorer that scores the candidate answer passages to decide which answer passage to show searchers.
Based on answer scores, one passage is selected and provided in response to the query.
Candidate answer passages are generated from resources identified as being responsive to the query.
The answer passage generator can use several passage selection processes to generate candidate answer passages.
The answer passage generator may use the top N ranked resources to generate and score the answer passages.
Choosing Answer Passages to Answer Question Queries
An example search results resource where an answer passage is provided with an answer to a question query.
The query [How far away is the moon] has been asked.
The query question processor identifies the query as a question query and also identifies the answer “289,900 Miles (364,400 km).”
In connection with the query question processor, the search system provides an answer box in response to the determination that the query is a question query and that an answer is identified.
The answer box includes the answer.
Additionally, the answer box includes an answer passage generated and selected by the answer passage generator and the answer passage scorer.
The answer passage is one of many answer passages processed by the answer passage generator and the answer passage scorer.
Additional information, such as search results, can also be provided on the search results page.
The search results are separate and distinct from the answer passage.
The web page resources are, for example, one of the top-ranked resources responsive to the query [How far away is the moon], and an answer passage generator can generate multiple candidate answer passages from the content of the resource.
The resource includes multiple headings. The Headings have respective corresponding text sections that are subordinate (the headings contain content that appears under them, and they head.)
Those text sections are subordinate to (come after) a heading when the heading structure is such that the text section directly “descends” from the heading.
The patent tells us that a text section does not need to be adjacent to the heading to which it is subordinate; for example, a heading may be linked in a resource that causes the browser to scroll to another portion of the resource so that the viewport is focused on the text section (like a named anchor that links to a section lower down on a page.)
In a document object model, a text section is subordinate to a heading when it is subordinate body text to the heading.

For example, concerning the patent drawing above about the distance from the earth to the moon, the following candidate answer passages may be among many generated by the answer passage generator from the resource:
- (1) It takes about 27 days (27 days, 7 hours, 43 minutes, and 11.6 seconds) for the Moon to orbit the Earth at its orbital distance
- (2) The moon’s distance from Earth varies because the moon travels in a slightly elliptical orbit. Thus, the moon’s distance from the Earth varies from 225,700 miles to 252,000 miles
- (3) Thus, the moon’s distance from the Earth varies from 225,700 miles to 252,000 miles
The answer passage scorer scores the answer passages: the answer passage with the highest score is selected and provided with the search results.
We are told that several scoring signals can be used, including query dependents scores, query independents scores, etc.
Each of the scoring components can be combined into a final answer score for candidate answer passage selection.
This would be an answer term score.
An answer term score is computed for each candidate answer passage.
To compute answer scores for candidate answer passages, the answer passage scorer compares an answer term vector associated with a received query to each candidate answer passage.
The answer term vectors for queries are stored in the term vector data.
Generating Term Vectors for Scoring Answer Passages
Parts of the term vector process as shown in a flowchart from the patent:
A process flowchart showing how term vectors are used to identify answer passages:
This answer term vector process is typically done independent of query time, e.g., in the pre-processing of search data used for scoring answer passages.
The process is done for multiple query definitions.
A “query definition” is data that, at query time, is used to match a received query to a term vector.
A query definition may be
- a single query in query log
- a set of queries that are determined to be similar queries
- a set of terms that can be used parse to a set of queries
An example of a query definition is [distance earth moon far elliptical apogee perigee].
In resources in a set of resources, the term vector generator identifies question phrases that match the query definition.
For example, the term vector generator may process sections of text from each resource to identify sections that include an interrogative term, which is a term that introduces or signals a question.
Such interrogative terms includes
- “How”
- “When”
- “Why”
- “Where”
- Question marks
- Etc.
Or language models can be used to determine if a section of text is a question phrase.
Other ways of detecting a question phrase in a section of text may also be used.
Sometimes, the analysis of question phrases in a resource may be limited to headers from the resource.
The use of markup tags may identify header text.
For example, only the text of headers may be evaluated for question phrases, and the headers are identified as question phrases.
Otherwise, all text in a resource may be evaluated.
When a question phrase is detected, the term vector generator determines whether the question phrase matches the query definition.
A match determination can be made in many ways and may depend on what type of query definition is used.
If the query definition is a single query, stop words may be removed from both the question phrase and the query, and the similarity of the two-term sets may be evaluated.
If that similarity meets a threshold, a match may be determined.
When multiple queries are used for a query definition, then the process above can be repeated for each query in the query definition. Thus, a match determined for any one query results in a match to the query definition.
When a set of terms is used for the query definition, stop words may be removed from the question phrase, and the similarity of the two-term sets may be evaluated.
If the similarity meets a threshold, a match is determined.
Using the drawing about the distance from the earth to the moon, for the query definition of [distance earth moon far elliptical apogee perigee], only the header, with the text “How far away is the Moon from the Earth?], results in a match to the query definition.
For each of the identified question phrases, the term vector generator selects in the resource a section of text immediately after the question phrase as an answer.
The term vector generator can use several text selection rules to choose the answer text.
In the case of structured HTML data, an entire paragraph immediately after a header can be selected.
For the example of the drawing about the distance from the earth to the moon, the entire paragraph is selected as the answer text.
In other circumstances, up to N sentences are selected, or until the end of the resource or formatting, a break occurs.
The value of N can be any number, such as 1, 3, or 5.
Other text selection processes can also be used.
This kind of comparison of question text with a query definition and selection of answer text can be repeated repeatedly.
So, there may be multiple matching question phrases identified for any given query definition, as depicted by question text sections.
Likewise, there may be multiple answers selected, as depicted by answer text sections.
Some of the instances of question text may match each other exactly, as in the case of material reproduced on more than one site.
The instances do not need to be unique, and each matching phrase is used to select the answer text.
Multiple instances of the same text may be indicative of the quality of the text.
When two question phrases are an exact match to each other, the answer text from both is used only if the answer text from each is not an exact match to each other.
Otherwise, only one instance of the answer text is used.
The term vector generator creates an answer term vector from the terms of the answers, including the answer terms and, for each answer term, an answer term weight.
Several appropriate weighting processes can be used.
For each term, the answer term weight may be based on the number of times the answer term occurs in the answer text for all selected answers.
Or, the answer term weight may be based on the number of answers the answer term occurs in.
The weight of each term may also be based on term specific parameters, such as:
- Inverse document frequency
- Term frequency
- The like
The occurrence weight contribution for a term in a particular answer may be scaled in proportion to the similarity of the query definition to the question phrase to which the answer’s text is immediate subsequent.
For example, assume a first answer follows a question phrase with a similarity score of 0.97 to a query definition, and a second answer follows a question phrase with a similarity score of 0.82 to the query definition.
Both answers include one occurrence of the term “distance.”
The contribution for the first answer for the term maybe 0.97, and the contribution for the second answer maybe 0.82. Other scaling and adjustments may also be used.
Sometimes, the term weights may be normalized. For example, term weights for stop words may be set to null values, or stop words may be omitted from the term vector.
The term vector generator stores the answer term vector in association with the query definition.
Each query definition may have an associated term vector, which is stored in the term vector data.
A resource may contribute an answer to more than one query definition.
For example, a resource would also be used to generate answer text for query definitions that match the queries [How long is the moon’s orbit], which would result in answer text, and [age of the moon], which would result in answer text, etc.
And Sometimes, question phrases may be grouped independent of any query definition.
Or question phrases may be grouped by their similarity to each other (e.g., using a clustering algorithm.)
Then, for each group, the term vector generator creates an answer term vector.
In particular, from the terms of the answers for each question phrase in the group, the term vector generator finds answer terms, and for each answer term, an answer term weight from the answers that correspond to the question phrases.
The answer terms and answer term weights are then in association with one or more queries.
For example, a query that most closely matches the terms of a particular cluster of question phrases may be associated with the answer term vector generated for that cluster.
Scoring Candidate Answer Passages
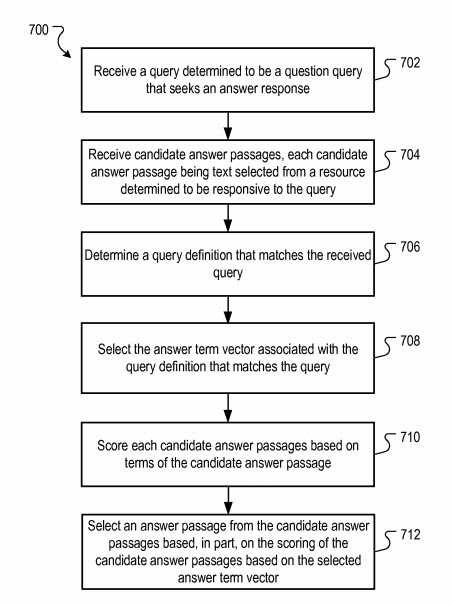
Scoring of candidate answer passages using answer term vectors.
The flowchart is an example process to score candidate answer passages using answer term vectors.
This process is happening at query time (e.g., in response to receiving a query from a searcher.)
The term vector scorer receives a query that has been determined to be a question query seeking an answer response.
The term vector scorer may receive the query Q (e.g., [How far away is the moon]), processed by the search system, and a searcher provided that.
The term vector scorer receives candidate answer passages, each of those candidate answer passages being text selected from a resource determined to be responsive to the query.
For example, a term vector scorer may receive candidate answer passages created by the answer passage generator.
Those passages may have been generated from the top N resources identified in response to the query.
The term vector scorer decides on a query definition that matches the received query.
For example, if the query definition is a query or a set of queries, then the received query is used to look up a matching query in a query definition in the term vector data.
Or, if the query definition specifies multiple matching queries by a set of parsing terms that can be used to parse a received query, then a query definition with the highest parse score is selected.
The term vector scorer selects the answer term vector associated with the query definition that matches the query.
Each query definition has a corresponding term vector. First, the term vector of the matching query definition is selected.
The term vector scorer scores each of the candidate answer passages based on the candidate answer passage.
A variety of scoring processes can be used.
One example scoring technique may calculate, for each term, the number of occurrences of a term in a passage and multiplies the number by the term weight.
For example, assume the term “moon” occurs two times in a candidate answer passage, the term value for “moon” for that candidate answer passage is 0.75.
Also, assume the same term occurs three times in a different candidate answer passage.
The scoring contribution of the “moon” for the first passage is 1.5 (2.times.0.75), and the scoring contribution for the second passage is 2.25 (3.times.0.75).
The contributing term values for each passage are then combined (e.g., summed) to determine a term vector score.
Other scoring calculations based on weights and occurrences can also be used.
If additional scoring techniques are used, additional scores and the term vector scores are combined in a score combiner to form a final answer score.
Alternatively, the term vector score may be used as the answer score.
The answer passage scorer may select an answer passage from the candidate answer passages based, in part, on the scoring of the candidate answer passages based on the selected answer term vector.
The candidate answer passage with the highest answer score is selected and provided with the search results.
What This Patent Adds To What We Know About Featured Snippet Scoring
Based on a Query, a query definition might be created to use to identify query questions on pages that might be found in search results for that query.
Google may look for headings that include query questions and find answers that are headed by those questions.
It may then score those answer passages.
One of the other patents focused on scoring answer passages based on query dependent and query independent signals.
Another patent adjusted rankings while scoring answer passages based on context signals using the headers that a question might contain.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: