Table of Contents
Entity Recognition is Becoming More Important at Google
Google replaced its head of search, Amit Singhal this week, with someone who came to Google when the company acquired Metaweb. The person who founded Metaweb, John Giannandrea, has been a vice-president at Google, in charge of Google’s AI efforts, and will be taking over as head of search at Google.
Related Content:
Metaweb is the company that ended up bringing the knowledge graph to Google and filling Google search results with knowledge panels related to entities that show up in those search results.
We were first made aware of entities by Google back in 2012, in their video “Introducing the Knowledge Graph”:
The home to entities on Google is in The Knowledge Graph, and Wikipedia tells us what a knowledge graph is:
The Knowledge Graph is a knowledge base used by Google to enhance its search engine’s search results with semantic-search information gathered from a wide variety of sources. Knowledge Graph display was added to Google’s search engine in 2012, starting in the United States, having been announced on May 16, 2012. It provides structured and detailed information about the topic in addition to a list of links to other sites. The goal is that users would be able to use this information to resolve their queries without having to navigate to other sites and assemble the information themselves. The summary provided in the knowledge graph is often used as a spoken answer in Google Now searches.
Google displays information about Entities from its knowledge graph in knowledge panels it displays to the right side of search results. If Google can identify that a specific entity is associated in some manner with a query that we as a searcher type into a search box, it will tell us more about that entity.
Entities in Knowledge Panels
That knowledge panel might include information about different aspects of that entity, from sources such as Wikipedia, Freebase, and other knowledge bases. Google might also tell us about other entities that people sometimes search for in addition to the entity we searched for.
For example, here is a knowledge panel result in Google for Nikoli Tesla:
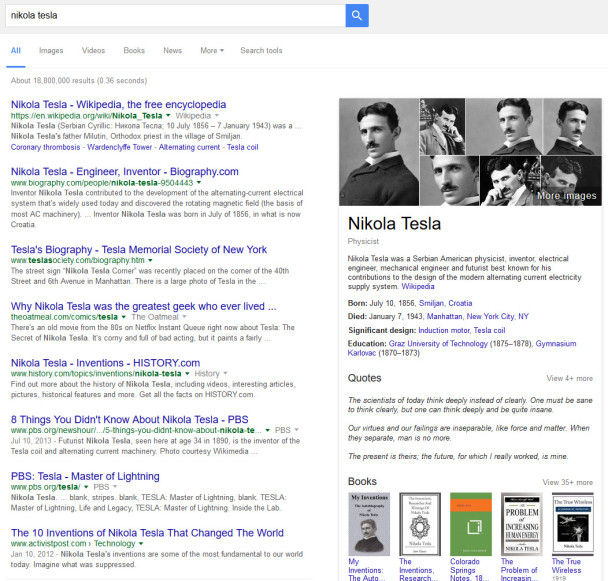
Google works to provide information to us about the many different entities that may appear in queries and searches. Google may associate names of entities with those entities when showing us knowledge panels for them.
When they are asked about an entity in queries, Google may try to engage in entity recognition to give us that information. For example, when Google is asked, “who is the CEO of Alphabet?”, it tells us “Larry Page” and provides information about him (in this case, from Wikipedia).
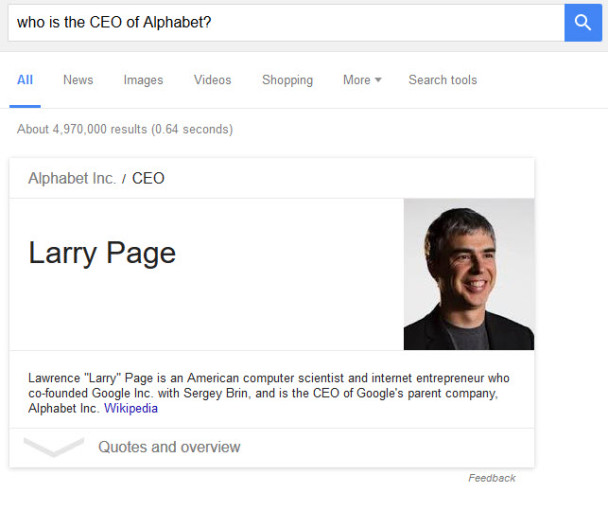
Entity Recognition to Answer Queries at Google
A Google patent was granted this Tuesday that focuses upon entity recognition and predicting entities when portions of sentences might refer to those entities. The knowledge bases that make up Google’s knowledge graph are filled with sentences about entities, which are likely a source of many answers to questions about them.
The patent provides some examples of how it might use entity recognition to entities that have been referenced in complete sentences, by gathering information about those entities and then using that information from those sentences to identify an entity asked about. Here’s an example from the patent:
The entity identification system obtains complete sentences that each include entity text that references the first entity. An example complete sentence may be, “In 1890, the President of the United States was Benjamin Harrison.” In the context of this example sentence, the entity text, “President of the United States” references the person, “Benjamin Harrison.” For each complete sentence, the entity identification system emulates typing the sentence and providing portions of the sentence to an entity identification model. The entity identification model determines a predicted entity for each portion of a sentence that it receives as input.
The patent builds upon this example by telling us how that information from a complete sentence might be used for entity recognition:
The entity identification system may continue to input portions of the complete sentence, updating the entity identification model for each portion based on the accuracy of the prediction. For example, the entity identification model may receive, “In 1890, the President of the Un,” as input. While this input may still refer to multiple entities, e.g., Benjamin Harrison, the President of the United States in 1890, or William Ellison Boggs, the President of the University of Georgia in 1890, the entity identification model may correctly predict Benjamin Harrison for this portion of the complete sentence. In this situation, the entity identification model may be updated, for example, by increasing confidence and/or likelihood that Benjamin Harrison will be identified for a sentence that begins “In 1890, the President of the Un.”
The entity recognition patent is:
Entity identification model training
Invented by: Maxim Gubin, Sangsoo Sung, Krishna Bharat, and Kenneth W. Dauber
Assigned to: Google
US Patent 9,251,141
Granted February 2, 2016
Filed: May 12, 2014
Abstract:
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for training an entity identification model. In one aspect, a method includes obtaining a plurality of complete sentences that each include entity text that references the first entity; for each complete sentence in the plurality of complete sentences: providing a first portion of the complete sentence as input to an entity identification model that determines a predicted entity for the first portion of the complete sentence, the first portion is less than all of the complete sentence; comparing the predicted entity to the first entity, and updating the entity identification model based on the comparison of the predicted entity to the first entity.
Takeaways
Search Engines like Google and Bing are transforming from providing information to searchers from an index of pages on the Web to providing information from an index of data they find on the Web. This means answering questions to searchers directly and being information resources that are focusing upon indexing information. Information about entities can be found in sources like Google’s knowledge graph, which can be used as a training source to build entity recognition models, as described in this patent.
The patent provides several examples of how it might use complete sentence information to build models that can help with the search engine recognizing specific entities. One of these includes the sentence “The tallest building in the world is the Burj Khalifa”, and how that information changes when you are talking about the world in 1931 when the tallest building in the world was the Empire State Building. The patent tells us that the models to recognize entities it builds might use partial sentences, returning information about the tallest person in the world and the tallest mountain in the world. Reading this whole patent is recommended for more details on how models helping to recognize entities might be built from sources like Google’s Knowledge Graph.
I thought it was interesting that one of the inventors listed on this patent was Krishna Bharat, who has done a lot of work behind Google News -another place we see entities spring up regularly. If Google is learning entity recognition, and how to answer questions about entities, it might be doing that in part by learning from the News about what they are up to.
We heard this past summer, about Google’s Deep Mind and their efforts to read CNN and The Daily Mail as training sources to learn about the world. They should be able to find and extract entities from those sources and perform entity recognition in queries to match up information about those entities for searchers.
And, with John Giannandrea, former founder of Metaweb, taking over as head of search at Google, we may see more knowledge graph information entering search results in the future and more information about entities filling those results. The future of Google may involve lots of entities.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: