Table of Contents
Does Google look at User Click-Through Rates and User Behavior to Influence Search Rankings?
Google Spokespeople have told us Google does not include user click-through rates when ranking pages in search rankings – they are too noisy, and for other reasons. A new patent from Google describes how user click-through rates and other user behavior information might influence rankings in search results. This new patent is not the first protecting a Google process from other search engines who might consider that process. After the first few patents about searchers interacting with search results, and how that information might be used to influence search rankings, it becomes curious that such information would continue to appear in Google Patents, and it invites looking closer at things such as User Click-Through Rates. Especially when the approaches involved have become more detailed.
Related Content:
This patent has been updated three times using continuation patents. Continuation patents are ways to update the claims from a patent to reflect changes in the processes behind a patent. The patent tells us that search rankings may be based upon the length of time that a searcher might spend viewing a page from search results and that documents may later be ranked higher based upon being viewed for longer periods:
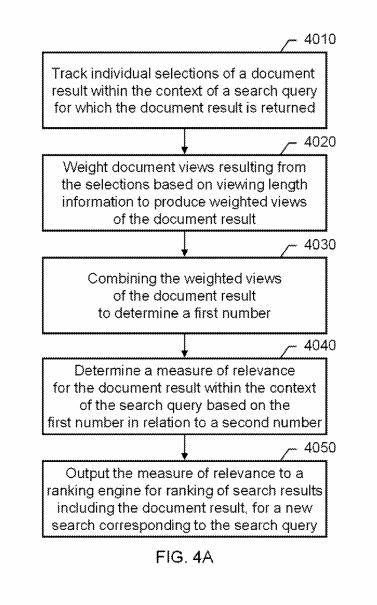
One aspect of the subject matter described in this specification can be embodied in a computer-implemented method that includes determining a measure of relevance for a document result within a context of a search query for which the document result is returned, the determining being based on the first number concerning a second number, the first number corresponding to longer views of the document result, and the second number corresponding to at least shorter views of the document result; and outputting the measure of relevance to a ranking engine for ranking of search results, including the document result, for a new search corresponding to the search query. The first number can include a number of the longer views of the document result, the second number can include a total number of views of the document result, and the determining can include dividing the number of longer views by the total number of views.
The method can further include tracking individual selections of the document result within the context of the search query for which the document result is returned; weighting document views resulting from the selections based on viewing length information to produce weighted views of the document result; and combining the weighted views of the document result to determine the first number. The second number can include a total number of views of the document result, the determining can include dividing the first number by the second number, and the measure of relevance can be independent of relevance for other document results returned in response to the search query.
This is a little more complicated than just looking at the viewing time for documents. The patent also suggests that the categories of the search query those documents are found for can also play a role in the impact of viewing time and User Click-Through Rates as well:
The weighting can include weighting the document views based on the viewing length information in conjunction with a viewing length differentiator. The viewing length differentiator can include a factor governed by a determined category of the search query, and the weighting can include weighting the document views based on the determined category of the search query. The viewing length differentiator can include a factor governed by a determined type of a user generating the individual selections, and the weighting can include weighting the document views based on the determined type of the user.
The advantages we are told that following the process described in this user click-through rates patent can bring:
- A ranking sub-system can include a rank modifier engine that uses implicit user feedback to cause re-ranking of search results to improve the final ranking presented to a user of an information retrieval system.
- User selections of search results (click data) can be tracked and transformed into a click fraction that can be used to re-rank future search results.
- Data can be collected on a per-query basis, and for a given query, user preferences for document results can be determined.
- Moreover, a measure of relevance (e.g., an LC|C click fraction) can be determined from implicit user feedback, where the measure of relevance can be independent of relevance for other document results returned in response to the search query, and the measure of relevance can reduce the effects of presentation bias (in the search results shown to a user), which might otherwise bleed into the implicit feedback.
This newest version of this user click-through rates patent can be found at:
Modifying search result ranking based on implicit user feedback
Inventors: Hyung-Jin Kim, Simon Tong, Noam M. Shazeer, and Michelangelo Diligenti
Assignee: Google LLC
US Patent: 10,229,166
Granted: March 12, 2019
Filed: October 25, 2017
Abstract
The present disclosure includes systems and techniques relating to ranking search results of a search query. In general, the subject matter described in this specification can be embodied in a computer-implemented method that includes determining a measure of relevance for a document result within a context of a search query for which the document result is returned, the determining being based on the first number about a second number, the first number corresponding to longer views of the document result, and the second number corresponding to at least shorter views of the document result; and outputting the measure of relevance to a ranking engine for ranking of search results, including the document result, for a new search corresponding to the search query. The subject matter described in this specification can also be embodied in various corresponding computer program products, apparatus, and systems.
The claims from this patent give us an idea of how Google might track how searchers interact with search results and the data that comes from those interactions. Claims from a patent are what prosecutors from the USPTO look at to decide whether to grant a patent or not. These claims tell us about a “result selection log”, and what kind of information may be kept in that log, and how it might be measured. I’ve included the first 5 claims from the patent, because they are all related to each other, and they provide some insights into what a search engine is looking at when we are performing searches on it:
What is claimed is:
1. A system comprising: one or more computers and one or more storage devices on which are stored instructions that are operable, when executed by the one or more computers, to cause the one or more computers to perform operations comprising: maintaining, in a result selection log, data regarding users’ interactions with search results from an Internet search engine for multiple users, each log entry in the result selection log for an actual interaction being specific to one interaction and including data identifying a respective user, a query submitted by the user, one or more search results presented by the search engine in response to the query, a document selected by the user from among the search results, an ordinal position in a presentation order of the search results of the search result selected by the user, a time the user spent on the document, a language employed by the user, and a country where the user is likely located, wherein the log entries include entries identifying multiple users, multiple documents, multiple languages, and multiple countries; determining from the log entries in the result selection log (i) weighted-click fractions for each of multiple query-document pairs, (ii) weighted-click fractions for each of multiple query-document-language pairs, and (iii) weighted-click fractions for each of multiple query-document-language-country pairs, wherein each weighted-click fraction is based on a sum of a weighted number of documents selected by the user, and each weight is based on how much time the user spent on the document; and modifying an information retrieval score in the Internet search engine for a specific document by applying one of the weighted-click fractions or a transform of the one of the weighted-click fractions to the information retrieval score for the specific document.
2. The system of claim 1, wherein the time the user spent on the document is measured as how much time passed between an initial click through to the document result until the user comes back to the search results presented by the search engine and selects another document result.
3. The system of claim 1, wherein the log data also includes for each of multiple presentations of search results by the search engine: whether a document result was presented to the respective user but was not selected, respective positions of one or more selections in a search results presentation user interface, information retrieval scores of selected documents, information retrieval scores of all documents shown before a selected document, and titles and snippets shown to a user before the user selected a document.
4. The system of claim 1, wherein the operations further comprise: assigning lower weights to click fractions based on users who almost always select the highest-ranked result lower weights than click fractions based on users who more often select results lower in the ranking first in the weighted-click fractions.
5. The system of claim 1, wherein the operations further comprise: classifying individual selections of document results into two or more viewing time categories and assigning weights to the individual selections based on the classifying, the viewing time categories including a category for a short click and a category for a long click.
This patent also puts some twists on what is referred to in it as “traditional techniques for ranking.” It talks about ranking being based on a combination of an Information Retrieval Score, and an authority Score using PageRank, but it builds upon PageRank, by looking at links to linking pages from other relevant documents:
The search engine can include a ranking engine to rank the documents related to the user query. The ranking of the documents can be performed using traditional techniques for determining an information retrieval (IR) score for indexed documents because of a given query. The relevance of a particular document concerning a particular search term or to other provided information may be determined by any appropriate technique. For example, the general level of back-links to a document that contains matches for a search term may be used to infer a document’s relevance. In particular, if a document is linked to (e.g., is the target of a hyperlink) by many other relevant documents (e.g., documents that also contain matches for the search terms), it can be inferred that the target document is particularly relevant. This inference can be made because the authors of the pointing documents presumably point, for the most part, to other documents that are relevant to their audience.
If the pointing documents are in turn the targets of links from other relevant documents, they can be considered more relevant, and the first document can be considered particularly relevant because it is the target of relevant (or even highly relevant) documents. Such a technique may be the determinant of a document’s relevance or one of multiple determinants. The technique is exemplified in the GOOGLE.RTM. PageRank system, which treats a link from one web page to another as an indication of quality for the latter page, so that the page with the most such quality indicators wins. Appropriate techniques can also be taken to identify and eliminate attempts to cast false votes to artificially drive up the relevance of a page.
The patent also introduces a rank modifier engine, which looks at other ways of measuring relevance as well.
To further improve such traditional document ranking techniques, the ranking engine can receive an additional signal from a rank modifier engine to assist in determining an appropriate ranking for the documents. The rank modifier engine provides one or more measures of relevance for the documents, which can be used by the ranking engine to improve the search results’ ranking provided to the user. The rank modifier engine can perform one or more of the operations described further below to generate the one or more measures of relevance.
The search engine can forward the final, ranked result list within a server-side search results signal through the network. Exiting the network, a client-side search results signal can be received by the client device where the results can be stored within the RAM and/or used by the processor to display the results on an output device for the user.
Features that a scoring engine might rank results upon
- Content-based features that link a query to document results
- query-independent features that generally indicate the quality of documents results
- A tracking component can be used to record information regarding individual user selections of the results presented in the ranking. For example, the tracking component can be embedded JavaScript code included in a web page ranking that identifies user selections (clicks) of individual document results and also identifies when the user returns to the results page, thus indicating the amount of time the user spent viewing the selected document result.
Tracking User Click-Through Rates
Tracking user click-through rates means looking at a lot of information such as log entries that indicate, for each user selection:
- The query (Q)
- The document (D)
- The time (T) on the document
- The language (L) employed by the user
- The country (C) where the user is likely located (e.g., based on the server used to access the IR system)
- Negative information, such as the fact that a document result was presented to a user, but was not clicked
- Position(s) of click(s) in the user interface
- IR scores of clicked results
- IR scores of all results shown before click
- The titles and snippets shown to the user before the click
- The user’s cookie
- cookie ag
- IP (Internet Protocol) address
- User agent of the browser, etc.
- Similar Information for entire sessions of searchers, potentially recording such information for every click that occurs both before and after a current click
All of this user information from Result Selection Logs might be used to later improve results for other searchers
This patent also described searchers permitting information about clicks to be tracked even post-click on specific queries. The items listed above could be tracked, as well as visits to other document sets and search results, including the time between documents. The time spent on specific documents might be categorized as being longer views or shorter views, with the longer views being a general indication of quality for a click through the search result.
What might different Viewing Times on a Page stand for?
The user click-through rates patent provides specific details on what different viewing lengths might mean:
For example, a short click can be considered indicative of a poor page and thus given a low weight (e.g., -0.1 per click), a medium click can be considered indicative of a potentially good page and thus given a slightly higher weight (e.g., 0.5 per click), a long click can be considered indicative of a good page and thus given a much higher weight (e.g., 1.0 per click), and the last click (where the user doesn’t return to the main page) can be considered as likely indicative of a good page and thus given a fairly high weight (e.g., 0.9). Note that the click weighting can also be adjusted based on previous click information.
Rather than just look at lengths of time alone, additional information involving user click-through rates might be considered as well:
The various time frames used to classify short, medium and long clicks, and the weights to apply can be determined for a given search engine by comparing historical data from user selection logs with human-generated explicit feedback on the quality of search results for various given queries, and the weighting process can be tuned accordingly.
How Bad Data Might be Safeguarded against
We’ve heard spokespeople from Google tell us that user click-through rates aren’t used for rankings, and this patent tells us how user feedback information can be more safely used:
Note that safeguards against spammers (users who generate fraudulent clicks in an attempt to boost certain search results) can be taken to help ensure that the user selection data is meaningful, even when very little data is available for a given (rare) query. These safeguards can include employing a user model that describes how a user should behave over time, and if a user doesn’t conform to this model, their click data can be disregarded. The safeguards can be designed to accomplish two main objectives: (1) ensure democracy in the votes (e.g., one single vote per cookie and/or IP for a given query-URL pair), and (2) entirely remove the information coming from cookies or IP addresses that do not look natural in their browsing behavior (e.g., abnormal distribution of click positions, click durations, clicks_per_minute/hour/day, etc.). Suspicious clicks can be removed, and the click signals for queries that appear to be spammed need not be used (e.g., queries for which the clicks feature distribution of user agents, cookie ages, etc. that do not look normal).
Relevance Determined from Length of Views
We are told that the number of times visitors might look at results could be an indication of how relevant they find a page. The phrase “presentation bias” is used to describe how this might work
Presentation bias includes various aspects of presentation, such as an attractive title or snippet provided with the document result, and where the document result appears in the presented ranking (position). Note that users tend to click results with good snippets, or that are higher in the ranking, regardless of the real relevance of the document to the query as compared with the other results. By assessing the quality of a given document result for a given query, irrespective of the other document results for the given query, this measure of relevance can be relatively immune to presentation bias.
The query used may indicate an informational need that may not require a lot of time, and that may be reflected in the amount of time someone might spend upon a page. The patent provides some examples involving navigational and informational queries:
Thus, in the discontinuous weighting case (and the continuous weighting case), the threshold(s) (or formula) for what constitutes a good click can be evaluated on the query and user-specific bases. For example, the query categories can include “navigational” and “informational”, where a navigational query is one for which a specific target page or site is likely desired (e.g., a query such as “BMW”), and an informational query is one for which many possible pages are equally useful (e.g., a query such as “George Washington’s Birthday”). Note that such categories may also be broken down into sub-categories as well, such as informational-quick and informational-slow: a person may only need a small amount of time on a page to gather the information they seek when the query is “George Washington’s Birthday”, but that same user may need a good deal more time to assess a result when the query is “Hilbert transform tutorial”.
This patent also tells us about how things like Dwell Time might be considered when it comes to user behavior, as well:
The query categories can be identified by analyzing the IR scores or the historical implicit feedback provided by the click fractions. For example, significant skew in either of these (meaning only one or a few documents are highly favored over others) can indicate a query is navigational. In contrast, more dispersed click patterns for a query can indicate the query is informational. In general, a certain category of a query can be identified (e.g., navigational), a set of such queries can be located and pulled from the historical click data, and regression analysis can be performed to identify one or more features that are indicative of that query type (e.g., mean staytime for navigational queries versus other query categories; the term “staytime” refers to time spent viewing a document result, also known as document dwell time).
Different User Types and Patterns and Clicks
This patent also goes beyond just looking at user click-through rates to view how information about different users can be identified based upon how quickly they click, and what they click upon. I suspect that what we are being told here is just a couple of examples and that more observations have been found that may indicate other helpful ways of interpreting such clicks:
User types can also be determined by analyzing click patterns. For example, computer-savvy users often click faster than less experienced users, and thus users can be assigned different weighting functions based on their click behavior. These different weighting functions can even be fully user-specific (a user group with one member). For example, the average click duration and/or click frequency for each user can be determined, and the threshold(s) for each user can be adjusted accordingly. Users can also be clustered into groups (e.g., using a K means clustering algorithm) based on various click behavior patterns.
Moreover, the weighting can be adjusted based on the determined type of the user both in terms of how click duration is translated into good clicks versus not-so-good clicks, and in terms of how much weight to give to the good clicks from a particular user group versus another user group. Some user’s implicit feedback may be more valuable than other users due to the details of a user’s review process. For example, a user that almost always clicks on the highest-ranked result can have his good clicks assigned lower weights than a user who more often clicks results lower in the ranking first (since the second user is likely more discriminating in his assessment of what constitutes a good result). Also, a user can be classified based on his or her query stream. Users that issue many queries on (or related to) a given topic T (e.g., queries related to the law) can be presumed to have a high degree of expertise concerning the given topic T, and their click data can be weighted accordingly for other queries by them on (or related to) the given topic T.
User Click-Through Rates Patents by Hyung-Jin Kim
One of the inventors on the patent I am writing about today is Hyung-Jin Kim. I’ve come across his name before.
An interesting Blog Post from A.J. Kohn about a patent co-invented by him is worth spending time looking at too. It is Is Click-Through Rate a Ranking Signal?.
Another post that is about a patent from the same inventor is one I wrote called Using Query User Data to Classify Queries. Hyung-Jin Kim isn’t the only Google Search Engineer who writes about user click-through rates.
I’ve also seen a few patents from Navneet Panda (yes the one the Google Panda Update is named after) who has written about the possibility of Google learning from user click-through rates and user behavior, which may influence search rankings
I also wrote the post The Long Click and the Quality of Search Success covering a patent which looked at the length of time someone might spend on a page as an indication of the quality of that page. It seems that the long click is a metric that people from Google have been paying a lot of attention to, which is closely related to user click-through rates.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: