Table of Contents
Looking at Trust Metrics at Google
Trust! What role might it have in ranking pages at Google? It’s used in a few different ways by search engines, and by Google specifically. A patent about trust and ranking was just updated at Google, which makes it a good time to look at the Trust Metrics that have been developed at Google.
I thought of sharing some trust metrics that Google may be using or has used in the past, before discussing changes to the patent that I mention.
Related Content:
One Mention of Trust that comes quickly to mind is what is in The Google Quality Rater’s Guidelines, which points out Expertise-Trustworthiness, and Authority as three things they want raters to look for when reviewing sites. We are told there:
7.2.1 Lowest E-A-T
One of the most important criteria of PQ rating is E-A-T. Expertise of the creator of the MC, and authoritativeness or
trustworthiness of the page or website, is extremely important for a page to achieve its purpose well.
If the E-A-T of a page is low enough, users cannot or should not use the MC of the page. This is especially true of YMYL
topics. If the page is highly inexpert, unauthoritative, or untrustworthy, it fails to achieve its purpose.
Important: The Lowest rating should be used if the page is highly inexpert, unauthoritative, or untrustworthy.
Another trust metric that you may not be aware of being based on trust is a version of PageRank, described in a patent filed by Google, which tells us about ranking pages based upon how close or distant they might be to a set of trusted seed sites. The abstract of this patent tells us how rankings are computed under this approach:
During operation, the system receives a set of pages to be ranked, wherein the set of pages are interconnected with links. The system also receives a set of seed pages which include outgoing links to the set of pages. The system then assigns lengths to the links based on the properties of the links and properties of the pages attached to the links. The system next computes the shortest distances from the set of seed pages to each page in the set of pages based on the lengths of the links between the pages. Next, the system determines a ranking score for each page in the set of pages based on the computed shortest distances. The system then produces a ranking for the set of pages based on the ranking scores for the set of pages.
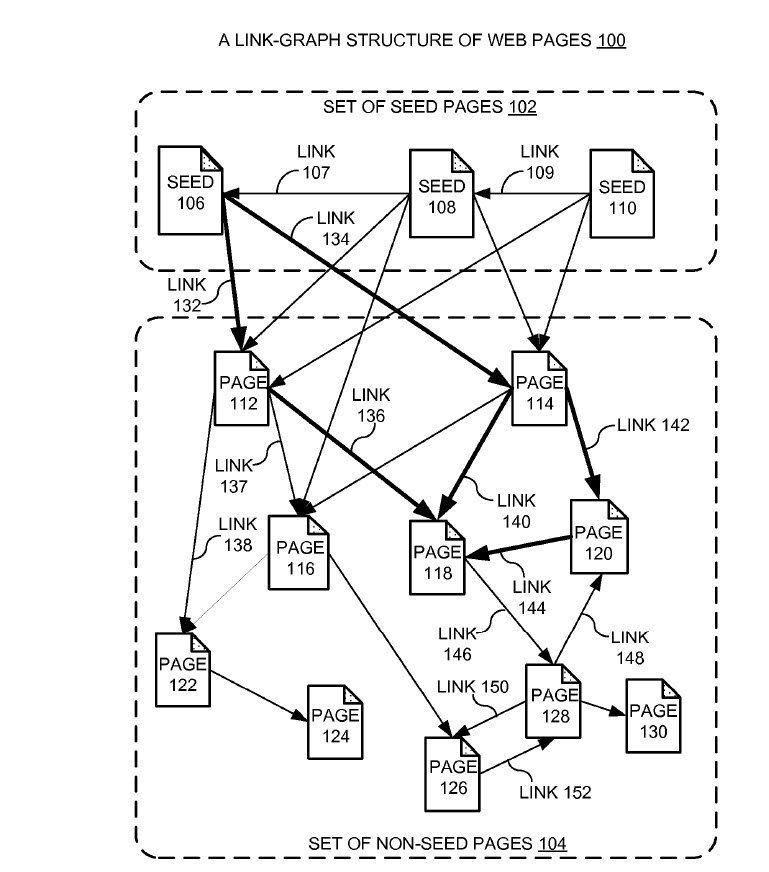
Possibly the most famous of Trust Metrics, and one often accidentally attributed to Google, or incorrectly cited as similar to what Google uses is from Google competitor Yahoo, who published a paper with Stanford about something they referred to as Trustrank. The TrustRank developed by Yahoo is completely unlike the Trust-based approach developed by Google. In addition to writing a paper about TrustRank, they also filed a patent (Link-based spam detection), which would prevent Google from legally using the same approach. The abstract from that patent:
A computer-implemented method of ranking search hits in a search result set. The computer-implemented method includes receiving a query from a user and generating a list of hits related to the query, where each of the hits has a relevance to the query, where the hits have one or more boosting linked documents pointing to the hits, and where the boosting linked documents affect the relevance of the hits to the query. The method associates a metric to each of at least a subset of the hits, the metric being representative of the number of boosting linked documents that point to each of at least a subset of the hits and which artificially inflate the relevance of the hits. The method then compares the metric, which is representative of the size of a spam farm pointing to the hit, with a threshold value, processes the list of hits to form a modified list based in part on the comparison, and transmits the modified list to the user.
Yahoo’s TrustRank is a way to identify Spam, and not necessarily to rank pages the way that the newer PageRank approach I mention above might do. The Yahoo Patent provides more detail:
TrustRank is a link analysis technique related to PageRank. TrustRank is a method for separating reputable, good pages on the Web from webspam. TrustRank is based on the presumption that good documents on the Web seldom link to spam. TrustRank involves two steps, one of seed selection and another of score propagation. The TrustRank of a document is a measure of the likelihood that the document is a reputable (i.e., a nonspam) document.
There are other ways that Google attempted to use people whom it trusted to act as experts when it comes to web pages, For instance, the Sidewiki project from Google. It isn’t a trust metric, but it was intended to let people annotate pages, and either adds to them, agree with them, or critique them.
The Sidewiki project has been shut down by Google. Even though it is no longer in use, it is interesting because of how it treats trust and expertise. As described in this Google Blog post: Help and learn from others as you browse the web: Google Sidewiki:
What if everyone, from a local expert to a renowned doctor, had an easy way of sharing their insights with you about any page on the web? What if you could add your insights for others who are passing through?
And Google also developed a trust metric that isn’t based upon links, but the accuracy and correctness of facts shouldn’t be surprising
A Google white paper came out in 2015, telling us about something called knowledge-based trust, which uses a set of 1,000 facts, and compares sites to see how many of those facts they got correct on their site. The paper was Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources. Xin Luna Dong, who is considered the inventor of the knowledge-based trust approach, came out with a presentation called Leaving No Valuable Data Behind: the Crazy Ideas and the Business. It explores knowledge-based trust and compares it to PageRank, which is captured in this slide from the presentation well:

An Earlier Version of Google’s TrustRank patent exists, which I wrote about in 2009 in the post Google Trust Rank Patent Granted. More about that one further down in this post.
Google Trustrank Using Google CSE
Under the trust-based CSE (custom search engine) patents, we are told about the problem that they are intended to solve:
An inherent problem in the design of search engines is that the relevance of search results to a particular user depends on factors that are highly dependent on the user’s intent in searching–that is why they are searching–as well as the user’s circumstances, the facts about the user’s information need. Thus, given the same query by two different users, a given set of search results can be relevant to one user and irrelevant to another, entirely because of the different intent and information needs. Most attempts at solving the problem of inferring a user’s intent typically depend on relatively weak indicators, such as static user preferences, or predefined methods of query reformulation that are nothing more than educated guesses about what the user is interested in based on the query terms. Approaches such as these cannot fully capture user intent because such intent is itself highly variable and dependent on numerous situational facts that cannot be extrapolated from typical query terms.
So, the value of a set of search results is dependent upon the intent of a searcher performing that search. How might these patents attempt to solve that issue? The solution may be in looking at sites that have been set up by experts in a topic that include annotations about why something might be linked to, which is described in the patent here:
In part because of the inability of contemporary search engines to consistently find information that satisfies the user’s information need, and not merely the user’s query terms, users frequently turn to websites that offer additional analysis or understanding of content available on the Internet. For discussion, these sites are called vertical knowledge sites. Some vertical knowledge websites, typically community sites for users of shared interests, allow users to link to content on the Internet and provide labels or tags describing the content. For example, a site may enable a user to link to the website of an automobile manufacturer, and post comment or description about a particular car being offered by the manufacturer; similarly, such a site could enable a user to link to a news report on the website of a news organization and post a comment about the report. These and other vertical knowledge sites may also host the analysis and comments of experts or others with knowledge, expertise, or a point of view in particular fields, who again can comment on content found on the Internet. For example, a website operated by a digital camera expert and devoted to digital cameras typically includes product reviews, guidance on how to purchase a digital camera, as well as links to camera manufacturer’s sites, new products announcements, technical articles, additional reviews, or other sources of content. To assist the user, the expert may include comments on the linked content, such as labeling a particular technical article as “expert level,” or a particular review as “negative professional review,” or a new product announcement as “new 10 MP digital SLR”. A user interested in a particular point of view, type of information, or the like then search within the domain of such a site for articles or links that have certain associated labels or comments. For example, a user could search the aforementioned digital camera site for all camera reviews labeled “digital SLR”.
So, the patent is telling us that it can use annotations from a custom search engine as if they were from experts on topics those search engines are about to gain a sense of trust (a trust metric or score) about those topics that might be annotated.
As I started reading this patent, I was wondering if the trust in the people making labels in custom search engines only applied to the results of the custom search engine, or if that trust was somehow applied to results from the general search engine also. The patent points out that issue by telling us:
The problem remains that when the user returns to a general search engine, outside of the vertical knowledge site, the user is unable to obtain search results that reflect the trustworthiness of the documents themselves or the trustworthiness of any commentary or opinions that may be associated with the search result documents. Thus, none of the additional reputation based information that is associated with users in the vertical knowledge site is available to the general search engine to provide more meaningful search results to other users.
The patent tells us that it might try to understand how much users (or searchers) trust the entities that applied labels annotating other pages, to determine how much trust rank to apply to results in the general search engine. The patent does describe some ways it might identify how much users might trust an entity that might label search results. Here’s one example:
As indicated above, the system can also use a web crawler to examine web pages to locate information indicating which user trusts a particular entity. While examining web pages, the web crawler can look for several relationships, including: (1) links from the user’s web page to web pages belonging to trusted entities; (2) a trust list that identifies entities that the user trusts; or (3) a vanity list which identifies users who trust the owner of the vanity page.
The TrustRank for a particular query (and label) might be aggregated over more than one custom search engine. The patent also tells us:
The trust ranks of the entities associated with the matching labels are aggregated to create an aggregated trust rank. Thus, in this example, the trust ranks of the three different experts would be aggregated into a single trust rank associated with the particular label “professional review” for the review document. This aggregation is performed for each label associated with the document.
In short, If you are an expert on a topic, you could set up a custom search engine on your site using Google’s Custom Search Engine Feature, and you can include sites other than just your own, and you can label the search results with refinement labels.
When you label pages from a particular site, you may be indicating to Google that you trust that site, and it may be boosted in search results based upon a Google TrustRank patent (Google may determine whether they do this based upon how much trust they believe that you may have as an entity that labels pages in a CSE, and whether or not they have aggregated annotations from multiple entities.
This newer version of the CSE Trust patent, just granted this week is a continuation patent, which means that the title and the description of both patents are the same, but the claims from each have been rewritten. It can be found at:
Search result ranking based on trust
Inventors: Ramanathan V. Guha
Assignee: Google LLC
US Patent: 10,268,641
Granted: April 23, 2019
Filed: July 29, 2014
Abstract
A search engine system provides search results that are ranked according to a measure of the trust associated with entities that have provided labels for the documents in the search results. A search engine receives a query and selects documents relevant to the query. The search engine also determines labels associated with selected documents and the trust ranks of the entities that provided the labels. The trust ranks are used to determine trust factors for the respective documents. The trust factors are used to adjust information retrieval scores of the documents. The search results are then ranked based on the adjusted information retrieval scores.
Claims from the TrustRank patent
The May 2006 filed version of this patent was also named Search result ranking based on trust
The version of the 1st claim from 2006 filed patent:
1. A method performed by a data processing apparatus, the method comprising: receiving a search query, the search query comprising a query term and a query label term, the query label term being a categorical identifier; identifying one or more resources in a search result set responsive to the search query, wherein each of the one or more resources has an associated matching label term that matches the query label term and an associated non-matching label term that does not match the query label term, each associated label term being the categorical identifier describing each resource and having been associated with the resource by a respective entity; determining, for each of the one or more resources: a trust rank of the entity that associated the associated matching label term with the resource, wherein the trust rank indicates whether a user trusts the associated matching label term of the resource, and increasing a relevance score of each resource that has the associated matching label term based on the respective trust rank, the relevance score indicating a degree of relevance between the respective resource and the query term; ranking each of the one or more resources in the search result set based on the respective relevance scores; annotating, with a name of the respective entity that associated the matching label term with each resource, indicia identifying each resource of the ranked search result set; and providing the indicia in a response to the search query.
This is the first claim from the newer version of the patent:
I claim:
1. A computer-implemented method comprising: providing, for display at a first computing device, a user interface associated with a particular entity, the user interface comprising (i) an interactive control configured to instruct a second computing device to assign a score in response to user interaction with the interactive control and (ii) an interface for the user to indicate topics for the particular entity, the interface indicating a plurality of topics corresponding to the interactive control; receiving data indicating (i) user interaction with the interactive control by a user and (ii) one or more topics selected by the user from among the plurality of topics corresponding to the interactive control; in response to receiving the data indicating (i) user interaction with the interactive control by the user and (ii) the one or more topics selected by the user from among the plurality of topics corresponding to the interactive control, sending, over a network, data that indicates the one or more topics that were selected by the user from among the plurality of topics corresponding to the interactive control, wherein the data causes the second computing device to assign a score for the user with respect to the particular entity for the one or more topics, the score indicating, to a search engine, a degree that content that is (i) associated with the particular entity and (ii) related to the one or more topics is relied on by the search engine to generate search results in response to queries from the user; in response to a query from the user, obtaining a set of search results for the query, the set of search results being ranked by the search engine based at least in part on the score for the user with respect to the particular entity for the one or more topics that were selected by the user from among the plurality of topics corresponding to the interactive control, wherein the set of search results comprises search results that each reference a document for which annotation text has been submitted by one or more entities, and wherein the search results are ranked based on the annotation text and scores for the user with respect to the one or more entities; and providing the set of search results ranked by the search engine based at least in part on the score for the user with respect to the particular entity for the one or more topics that were selected by the user from among the plurality of topics corresponding to the interactive control.
According to this new claim, it is pointing out search results that are being ranked based upon annotation text and the score of the user concerning the one or more entities (that may have annotated those results.)
I wanted to check to see if there were Google support pages that described the act of annotating sites for Custom Search Engines and found this page: Annotations: Defining Sites to Search
Take-Aways From the Google CSE Trustrank Patent
This may be a good reason to set up a custom search engine on a site and create annotation labels for results within it. In addition to doing that, there would be value in making it likely that people trusted your site with the CSE enough to do things like a link to you, or list your site as a trusted one.
Trust Metrics and Search
There are several ways that Google might attempt to find trustworthiness, and trusted relationships between searchers and site owners. We see examples in the Quality Rater Guidelines E-A-T descriptions. In the newer version of PageRank which may be ranking pages based upon their distance from a trusted seed set of sites. In a knowledge-based trust score, which may be more helpful in cases where correctness is of more value than popularity. Or based upon annotations made in Custom Search Engines at Google from people whom searchers may have shown some level of trust in.
Building trust in your website has more value than just how your site may rank in search results. If your site is one that people trust, they may refer people to your pages, link to your pages, and cite you as a reliable expert.
One step in building trust is to build a foundation upon which people can decide how much trust they might place in you and to then support that foundation with reasonable and knowledgeable content. It can take a lot of effort to build trust, and trust can evaporate quickly – but we do see that it is something that search engines and visitors to web pages value
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: