Table of Contents
Updated 9/12/2019 The news is that Google has updated its news algorithm to focus more on originality as is being reported at places like the New York Times: Google Says a Change in Its Algorithm Will Highlight ‘Original Reporting’
In anticipation of this post, I ran a poll on Twitter…
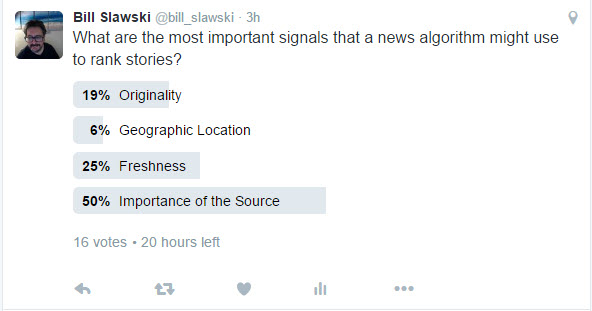
I was curious if anyone would chose Originality.
If I were to ask you last week, how much of a role does originality play in the ranking of news articles shown by Google in their news section, and you had answered that it wasn’t as important as other signals, you may have been right. But, that may have changed since then.
Related Content:
Every once in a while, the way Google does something changes. And one way to tell is in the Claims sections of patents that are being updated by the Search Giant. I saw a good opportunity to share a changing patent in action as an important patent involving Google News was updated this week.
This Tuesday, a continuation version of a Google Patent was granted at the USPTO, and a review of changes in the claims section of the patent shows off how the new patent operates as opposed to the old one.
The new patent is:
Methods and apparatus for ranking documents
Inventors: Krishna Bharat, Jeffrey A. Dean, Michael Curtiss, Amitabh Singhal, and Michael Schmitt
Assigned to: Google
US Patent 9,477,714
Granted: October 25, 2016
Filed: September 17, 2014
Abstract:
Methods and apparatus are described for scoring documents in response, in part, to parameters related to the document, source, and/or cluster score. Methods and apparatus are also described for scoring a cluster in response, in part, to parameters related to documents within the cluster and/or sources corresponding to the documents within the cluster. In one embodiment, the invention may detect at least one document within the cluster; analyze a parameter corresponding to the document; and compute a cluster score based, in part, on the parameter, wherein the cluster score corresponds with at least one document within the cluster.
You may recognize some of the inventors listed for this patent. They were the inventors on the earlier versions of the patent. Krishna Bharat is known as the inventor of Google News. Jeffrey Dean is the head of the Google Brain team. Amit Singhal was the head of Search at Google for a long period until retiring recently. The body of the patent is the same as the last version of the patent, but the claims have changed. That was the first place I went to look to see what was new in this patent.
To see what changed, I need to find an older version of the patent and the second version, originally filed in 2011, is at:
Methods and apparatus for ranking documents
Inventors: Krishna Bharat, Jeff Dean, Michael Curtiss, Amitabh Singhal, Michael Schmitt
Assignee: Google
US Patent 8,843,479
Granted: September 23, 2014
Filed: November 18, 2011
If you click through and look, You may notice that the abstract for this version of the patent is the same as that of the newest version. Most of the rest of the patent hasn’t changed either. The first version of this patent was filed in 2003. However, the claims in all three versions of the patent have changed over that period, and that is the point of filing a continuation patent, to update the process protected by the patent
I’m going to reproduce here sections from each of these first claims starting with the newest, and then other versions before that (2011 and 2003). These are unique statements in each initial claim, and I am pointing them out because I was surprised to see a shift in focus from Keyword matching to Geography to Originality as important signals. I guess it shouldn’t be surprising that the Algorithms behind Google News have become more complicated over time.
First Claim from 2014 Version – Focusing upon Originality
1. …the method comprising: analyzing, by the one or more server devices, a measure of the originality of the document, the measure of originality based upon a similarity of text of the document to one or more other documents …determining, by the one or more server devices, a score for the document based on analyzing the measure of originality, analyzing the freshness of the document, and analyzing the recency of coverage…
First Claim from 2011 Version – Focusing upon Geography
1. …the method comprising: …determining that content of the document includes information that is associated with a geographic region, and determining whether the source is associated with a geographic region that matches the geographic region associated with the information included in the content of the document, the measure of importance of the source being determined based on determining whether the source is associated with a geographic region that matches the geographic region associated with the information included in the content of the document, the measure of importance of the source exceeding measure of importance of one or more different sources that publish documents when: the source is associated with a geographic region that matches the geographic region associated with the information included in the content of the document, and the one or more different sources are associated with a geographic region that does not match the geographic region associated with the information included in the content of the document…
First Claim from 2003 Version – Focusing upon a Keyword
1. …the method comprising: receiving… at least one keyword; selecting… a document in response to receiving the query…
If you read through the claims for these patents, they do mention other signals that play a role in how News articles might be ranked that include such things as the importance of the news source or the quality of that news source, the freshness of the content, and the recency of the article (such as when was it published)
How Originality as a Ranking Signal May be Measured?
I dug into the claims from the newest patent to see if it provided more details on how originality might be measured, and it did have a claim that told us more:
13. A system comprising: one or more server devices to: identify a document; analyze a measure of the originality of the document, the measure of originality based upon a similarity of text of the document to one or more other documents…
So, the originality of a document appears to be based upon a look at how similar the text of the document might be to other documents on the same subject, it appears. The patent doesn’t tell us more than that, but there are potentially some ways to do this that might be helpful. For instance, in another news related patent from Google that was updated like this one, and co-invented by Krishna Bharat showed some changes that would produce more original documents, such as:
How many “entities” – that is, proper nouns, or people, places and things – are mentioned in an article compared to similar articles within the same “cluster” of related articles.
So one type of comparison that might be done in ranking news stories to see which are more original might be to see how many different people or places they might mention when comparing articles on the same topics. That seems to be a considerable change from the oldest patent, which mostly appears to be concerned about whether or not stories contain a keyword that a searcher looked for or the last version which gave the location of story importance. Looking at the uniqueness and the complexity of a story seems like an improvement, an evolution of search-related to how news stories are ranked by Google.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: