Table of Contents
Machine Learning at Google
This Google patent is about training a machine learning model to rank documents in response to search queries.
Online search engines such as Google rank documents in response to search queries to present search results filled with documents that are responsive to a search query.
Search engines usually show search results in an order defined by a ranking.
Related Content:
Search engines rank documents using various factors with various ranking techniques.
A search engine may rank documents based on a ranking machine learning model that receives features of an input document and, possibly, the received search query and will then generate a ranking score for the input document.
This patent describes training a ranking machine learning model.
Using Machine Learning to train a ranking model
The patent from today was granted on April 29, 2021. It focuses on receiving training data for a ranking machine learning model to rank documents in response to search queries.
The training data includes training examples. Each training example includes data identifying:
- Search query
- Result documents from a result list for the search query
- Result documents selected by a searcher from the result list of result documents
The patent is about receiving position data for each of the training examples in the training data.
That position data identifies the position of the selected result document in the SERPs for the search query in the training example.
Determining, for each training example position data and the selection bias value representing in which that result will impact the selection of the result document
Determining a respective importance value for each training example from the selection bias value for the training example, the importance value defining how important the training example is in training the ranking machine learning model.
Also, the patented process may include the following features in combination:
- Receiving experiment data identifying many experiment search queries which each fill a respective position in an experiment result list of experiment result documents for the experiment search query of an experiment result document selected by a searcher, where the positions of experiment result documents in the experiment result lists were randomly permuted before being presented to searchers
- Determining for each position, a respective count of selections of experiment result documents at the position by searchers in response to the number of experiment search queries in the experiment data; and determining, for each of the plurality of positions, a respective position bias value for the position based on the respective count of selections for the position
- Assigning the respective position bias value corresponding to the position of the selected result document in the result list of result documents for the training example to be the selection bias value for the training example
Wherein the experiment search queries in the number of experiment search queries each belong to a respective query class of a plurality of query classes, the method includes, for each of the plurality of query classes:
- Determining, for each of the numbers of positions, a count of selections of experiment result documents at the position by searchers responding to experiment search queries belonging to the query class in the experiment data
- Determining, for each of the plurality of positions, a respective class-specific position bias value for the position based on the respective count of selections for the position
- Obtaining data identifying a query class to which the search query for the training example belongs
- Assigning the class-specific position bias value for the query class to which the search query belongs
- Corresponding to the position of the selected result document for the training example in the result list of result documents to be the selection bias value for the training example
- Obtaining a respective feature vector for each experiment search query, generating training data for training a classifier that receives a respective feature vector for an input search query and outputs a respective query-specific position bias value for each of a plurality of positions for the input search query, and training the classifier on the training data
- Obtaining a feature vector for the search query in the training example
- Processing the feature vector using the trained classifier to generate a respective query-specific position bias value for each of the plurality of positions for the search query in the training example
- Assigning the query-specific position bias value corresponding to the position of the selected result document for the training example in the result list of result documents for the search query to be the selection bias value for the training example
- Labeling the experiment search query as a positive example for the position in the experiment result list of result documents for the experiment search query of the experiment search result that the searcher selected, and labeling the experiment search query as a negative example for other positions of the plurality of positions
- Training the ranking machine learning model on the training data using the respective importance values for the plurality of training examples in the training data
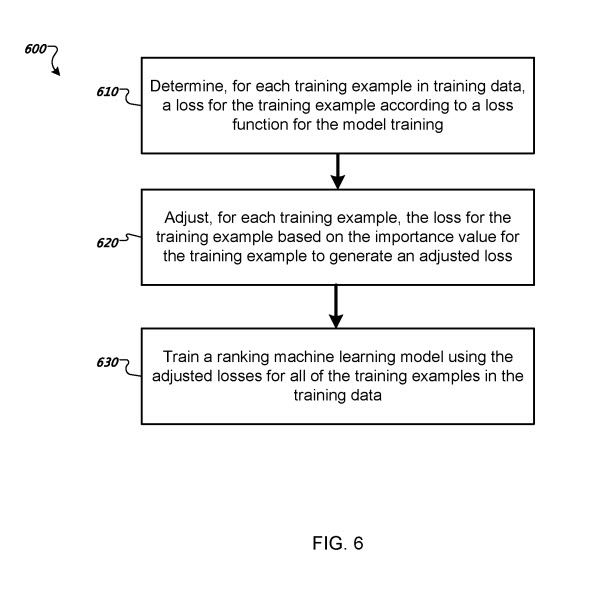
- Determining, for each training example of the plurality of training examples in the training data, a respective loss for the training example
- Adjusting, for each training example of the plurality of training examples in the training data, the loss for the training example based on the importance value for the training example to generate an adjusted loss
- Training the machine learning model using the adjusted losses for the plurality of training examples in the training data
The method includes training the machine learning model by minimizing a sum of the adjusted losses for the training data’s plurality.
Advantages of Following this Machine Learning Ranking Model
Conventional click-through data models can estimate the relevance for individual query-document pairs in the context of web search.
Those conventional click-through data models usually require many clicks for each pair of individual query and result documents. This makes click-through data models difficult to apply where click data is highly sparse due to personalized corpora and information needs, e.g., personal search.
Compared to the conventional click-through data models, a system that uses selection bias for various result list positions when training a ranking model can more effectively leverage sparse click data while reducing or eliminating the effects of selection bias on the ranking scores generated by the trained model.
This means that the trained model can provide accurate ranking scores even when click data is very sparse, which means that search results better satisfy the informational needs of searchers.
This patent can be found at:
Training a Ranking Model
Patent Number: US20210125108
Inventors Donald Arthur Metzler, Jr., Xuanhui Wang, Marc Alexander Najork, and Michael Bendersky
Applicants Google LLC
Granted Date: April 29, 2021
Filed Date October 24, 2016
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for training a ranking machine learning model. In one aspect, a method includes the actions of receiving training data for a ranking machine learning model, the training data including training examples, and each training example including data identifying: a search query, result in documents from a result list for the search query, and a result document that was selected by a searcher from the result list, receiving position data for each training example in the training data, the position data identifying a respective position of the selected result document in the result list for the search query in the training example; determining, for each training example in the training data, a respective selection bias value; and determining a respective importance value for each training example from the selection bias value for the training example, the importance value.
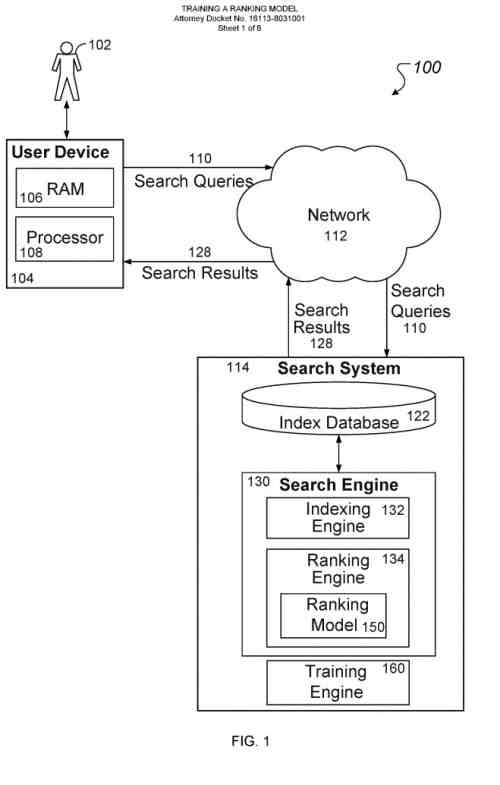
An example machine learning search system
A searcher can interact with the search system through a searcher device.
The searcher device may be a computer coupled to the search system through a data communication network, e.g., local area network (LAN) or wide area network (WAN), e.g., the Internet, or a combination of networks.
In some cases, the search system can be implemented on the searcher device if a searcher installs an application that performs searches on the searcher device.
The searcher device will generally include a memory, e.g., a random access memory (RAM), for storing instructions and data and a processor for executing stored instructions. The memory can include both read-only and writable memory.
Generally, the search system can be configured to search a specific collection of documents that are associated with the searcher of the searcher device.
The term “document” will be used broadly to include any machine-readable and machine-storable work product.
Documents may include:
- A file
- A combination of files
- One or more files with embedded links to other files
- A news group posting
- A blog
- A business listing
- An electronic version of printed text
- A web advertisement
- Etc.
The collection of documents that the search system is configured to search may be e-mailed in an e-mail account of the searcher, mobile application data associated with an account of the searcher, e.g., preferences of mobile applications or usage history of mobile applications, files associated with the searcher in a cloud document storage account, e.g., files uploaded by the searcher or files shared with the searcher by other searchers, or a different searcher-specific collection of documents.
A searcher can submit search queries to the search system using the searcher device. When the searcher submits a search query, the search query is transmitted through the network to the search system.
When the search system receives the search query, a search engine within the search system identifies documents in the collection of documents that satisfy the search query and responds to the query by generating search results that each identify a respective document that satisfies the search and transmitted through/the network to the searcher device for presentation to the searcher, i.e., in a form that can be presented to the searcher.
The search engine may include an indexing engine and a ranking engine. The indexing engine indexes documents in the collections of documents and adds the indexed documents to an index database. The ranking engine generates respective scores for documents in the index database that satisfy the search query and rank the documents based on their respective scores.
Generally, search results are displayed to the searcher; a result list is ordered according to the ranking scores generated by the ranking engine for the documents identified by the search results 128. For exaThus, fore, a search result identifying a document with a higher score can be presented in a higher position in the result list than a search result identifying a document with a relatively lower score.
The ranking engine generates ranking scores for documents using a ranking machine learning model.
The ranking machine learning model is a machine learning model trained to receive features or other data characterizing an input document and, optionally, data characterizing the search query and to generate a ranking score for the input document.
The ranking machine learning model can use a variety of machine learning models.
The ranking machine learning model can be a deep machine learning model, e.g., a neural network, that includes multiple layers of non-linear operations.
Or the ranking machine learning model can be a shallow machine learning model, e.g., a generalized linear model.
Depending on how the ranking machine learning model has been trained, the ranking score may predict the relevance of the input document to the search query or may take into account both the relevance of the input document and the query-independent quality of the input document.
In some implementations, the ranking engine modifies the ranking scores generated by the ranking machine learning model based on other factors and rank documents using the modified ranking scores.
To train the ranking machine learning model so that the model can be used in ranking documents in response to received search queries, the search system also includes a training engine.
The training engine trains the ranking machine learning model on training data that includes multiple training examples.
Each training example identifies
- (i) a search query
- (ii) result documents from the result list for the search query
- (iii) a result document that was selected by a searcher from the result list of result documents for the search query
As described in this patent, a selection of a result document in response to a search query is selecting a search result identifying the result document from a result list of search results presented in response to the submission of a query by a searcher. The SERPs are the documents that are identified by the search results in the result list.
To improve the quality of ranking scores from the ranking machine learning model once trained, the training engine trains in a manner that accounts for the result list of the search result that the searcher selected.
The training engine determines a respective importance value for each training example based on the position in the result list of the search result that the searcher selected in response to the search query in the training example.
By training the machine learning model this way, the training engine reduces or eliminates the impact of position bias on ranking scores generated by the ranking machine learning model once the model has been trained.
Determining a respective importance value for each training example in training data
The system receives position data, which identifies a respective position in the result list for the search query that the searcher selected in response to the search query, i.e., the search result that the searcher selected from the result list generated in response to the search query.
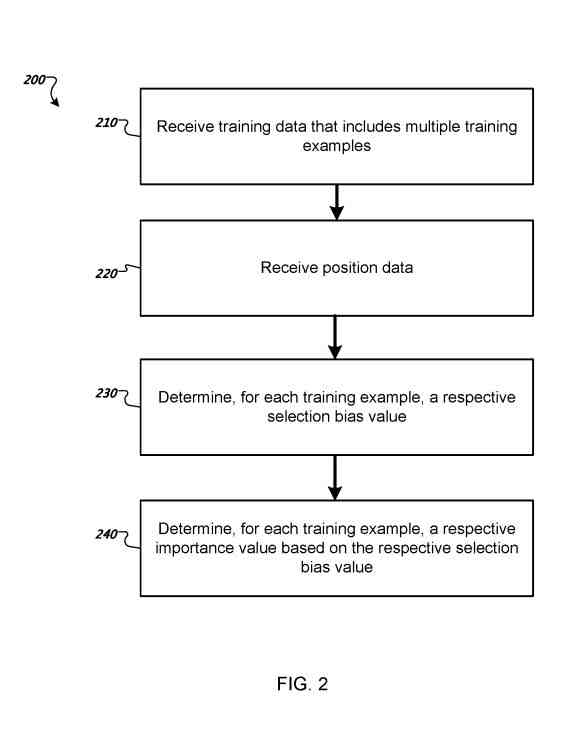
The system determines a respective selection bias value, which represents a degree to which the position of the selected result document in the result list for the search query in the training example impacted the selection of the result document.
The selection bias value can be determined in many ways.
The system determines, for each training example in the training data, a respective importance value.
The importance value for a given training example defines how important the training example is in training the ranking machine learning model.
The respective importance value for each training example in the training data can be determined based on the respective selection bias value for the training example.
For example, the importance value for a particular training example can be the inverse of the selection bias value for the training example or, more generally, be inversely proportional to the selection bias value for the training example.
Once the system determines the respective importance values for the training data’s training data, the system trains the ranking machine learning model on the training data using the importance values.
Determining a respective selection bias value for each training example in training data
The system receives experiment data identifying experiment search queries. For each experiment search query, a respective position in an experiment result list of experiment result documents for the experiment search query of an experiment results in document that a searcher selected.
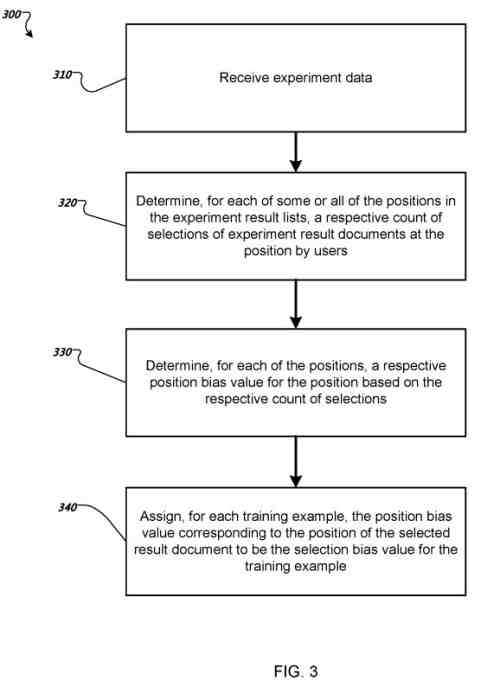
The experiment result documents’ positions result lists were randomly permuted before the experiment result lists were presented to searchers.
Thus, the experiment result document that the searcher selected from a given result list was equally likely to be assigned to any of the experiment results list positions.
For each of the positions in the experiment result lists, the system determines a respective count of selections of experiment result documents at the position by searchers in response to the experiment search queries in the experimental data.
For example, the system can determine a respective count of selections for the top N positions in experiment result lists, where N is an integer greater than 1, e.g., four, five, or ten, or for each position in the experiment result lists.
For example, where the system receives experiment data including 10 experiment result lists if searchers selected the first position for 7 of the experiment result lists, a second position for 2 of the experiment result lists. Thus, the third position for 1 of the experiment result lists, the count of selections for the first position can be 7, the count of selections for the second position can be 2, and the count of selections for the third position can be 1.
For each of the positions, the system determines a respective position bias value for the position based on the respective count of selections for the position.
The position bias value represents a degree to which the selected experiment result document in the experiment result list for the experiment search query in the experiment data impacted the selection of the experiment result document.
In some implementations, each position’s respective position bias value can be proportional to a respective count of selections for the position. In some implementations, a respective position bias value for each position can be computed by dividing the count of selections at the position by selecting selections at any position of the positions in the experiment result lists.
For each training example in the training data, the system assigns the position bias value corresponding to the position of the selected result document in the result list of result documents for the training example to be the selection bias value for the training example.
For example, where the system determines a position bias value b 1 for a first position using the count of selections of experiment result documents at the first position if the first position is the position of a result document that the searcher selected in the result list for the training example in the training data, the system determines that the position bias value 1 is the selection bias value for the training example.
Determining a respective selection bias value for each training example in training data
In this example, each experiment search query in experiment search queries has been classified as belonging to a respective query class of a predetermined set of query classes. Then, the system performs the process for each class in the predetermined set of query classes.
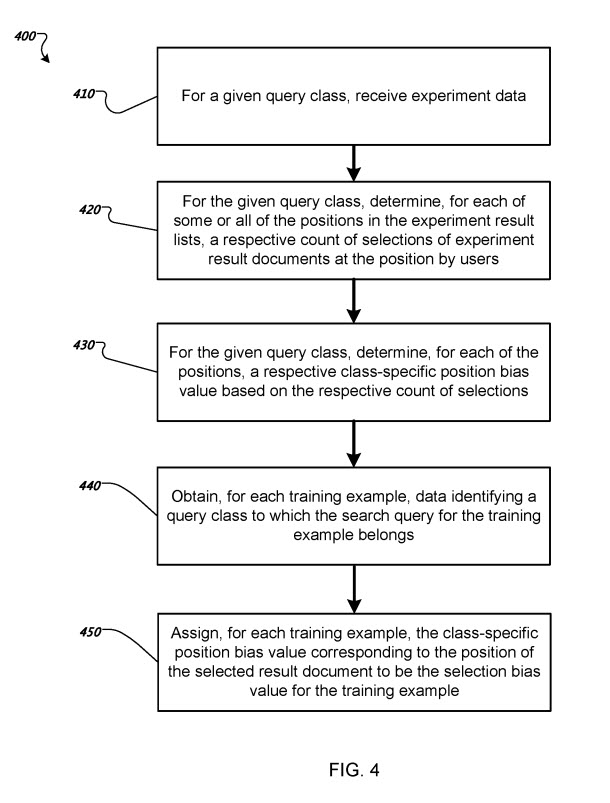
For a given query class, the system receives experiment data identifying experiment search queries that were classified as belonging to the given query class and, for each of these experiment search queries, a respective position in an experiment result list of result documents for the experiment search query of an experiment result document that a searcher selected.
For the given query class, the system determines, for each of some or all of the positions in the experiment result lists, a respective count of selections of experiment result documents at the position by searchers in response to the experiment search queries belonging to the query class in the experiment data. Thus, for example, the system can determine a respective count of selections for the top N positions in the experiment result lists.
For the given query class, the system determines a respective class-specific position bias value for the position based on the respective count of selections for the position for each of the positions. In some implementations, each position’s respective position bias value can be proportional to a respective count of selections for the position.
For each training example in the training data, the system obtains data identifying a query class to which the search query for the training example belongs.
The system assigns, for each training example in the training data, the class-specific position bias value for the query class to which the search query belongs and corresponding to the position of the selected result document in the result list of result documents for the training example to be the selection bias value for the training example.
For example, where a search query Q belongs to a query class t and the system determines a class-specific position bias value b i t for a first position using the count of selections of experiment result documents at the first position, if the first position is the position of a result document that the searcher selected in the result list for the training example in the training data, the system determines that the class-specific position bias value b 1 t is the selection bias value for the training example.
An example process for determining a respective selection bias value for each training example in training data
The system receives experiment data identifying experiment search queries. For each experiment search query, a respective position in an experiment result list of result documents for the experiment search query of an experiment result document that a searcher selected.
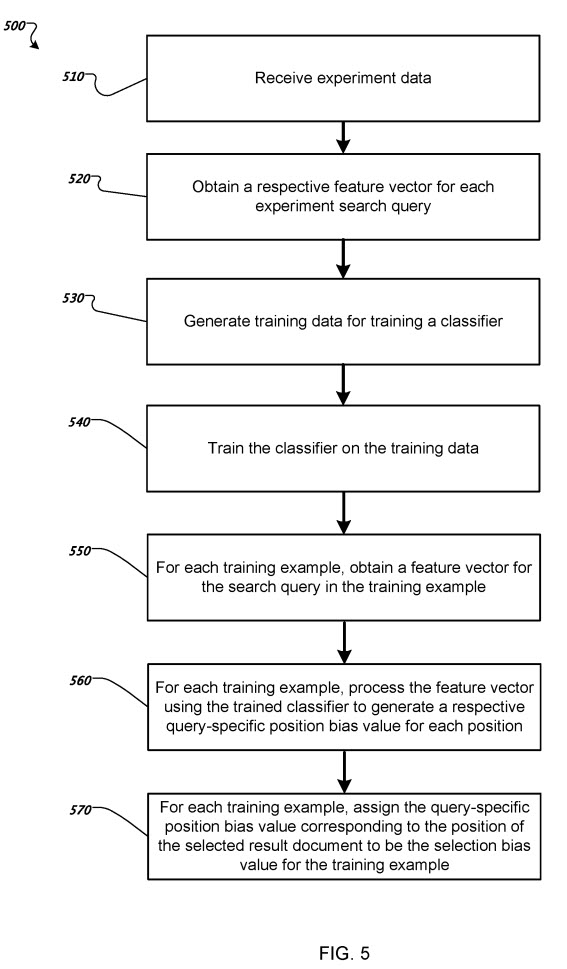
The system obtains a respective feature vector for each experiment search query of the experiment search queries. The feature vectors can be query-specific or searcher-specific. For example, the query features may include the number of words in the query, the class of the query, or the preferred language of the searcher.
The system generates training data for training a classifier. The classifier is trained to receive a respective feature vector for an input search query and output a respective query-specific position bias value for each of the input search query positions.
The training data can include positive examples of experiment search queries and negative examples of experiment search queries. For example, the system can label an experiment search query as a positive example for the experiment result list of result documents for the experiment search query of the experiment search result that the searcher selected. The system can label the experiment search query as a negative example for non-selected positions of the positions in the experiment result list of result documents.
The system trains the classifier on the training data. Training the classifier can be a machine learning process that learns respective weights to apply to each input feature vector. In particular, a classifier is trained using a conventional iterative machine learning training process that determines trained weights for each result list position. Based on initial weights assigned to each result list position, the iterative process attempts to find optimal weights. For example, the query-specific position bias value b i Q for a given position i for a given search query Q can be given using the following formula:
β i denotes the trained weights for position i, and v(Q) denotes a feature vector for the search query Q.
The classifier may be a logistic regression model. Other suitable classifiers can be used in other implementations, including naïve Bayes, decision trees, maximum entropy, neural networks, or support vector machine-based classifiers.
For each training example in the training data, the system obtains a feature vector for the search query in the training example.
For each training example in the training data, the system processes the feature vector using the trained classifier to generate a respective query-specific position bias value for each of the positions for the search query in the training example. First, the trained classifier receives the feature vector as input. Then, it outputs a respective query-specific position bias value for each position in the result list for the search query in the training example.
For each training example in the training data, the system assigns the query-specific position bias value corresponding to the position of the selected result document for the training example in the result list of result documents for the search query to be the selection bias value for the training example.
For example, where the system determines a query-specific position bias value b 1 Q for a first position using the trained classifier if the first position is the position of a result document that the searcher selected in the result list for the training example in the training data, the system determines that the query-specific position bias value b 1 Q is the selection bias value for the training example.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: