Table of Contents
Introducing Google’s RankBrain
A Google patent granted in August looks at how google might replace terms within queries, and I have some examples of how it rewrites some queries below. It’s part of my investigation into Google’s newly announced RankBrain Deep Learning method.
The RankBrain method was described in the Bloomberg news article published today, Google Turning Its Lucrative Web Search Over to AI Machines. That article tells us the names of two of the five people who began exploring the use of Artificial Intelligence to rank web pages, and tells us that it’s a very popular approach at Google these days. The article tells us:
The rollout of RankBrain represents a yearlong effort by a team that started with about five Google engineers, including search specialist Yonghui Wu, and deep-learning expert Thomas Strohmann.
According to the article, RankBrain is supposedly the third most important signal in how Google ranks pages in search results at Google. Looking at patents that may involve people in this project rewriting queries seemed like a good starting point to me. I found one patent that had Thomas Strohmann, listed as one of the inventors, and it reminded me of the rewriting approach from Google’s Hummingbird update. The Bloomberg News article tells us:
RankBrain uses artificial intelligence to embed vast amounts of written language into mathematical entities — called vectors — that the computer can understand.
If RankBrain sees a word or phrase it isn’t familiar with, the machine can guess as to what words or phrases might have a similar meaning and filter the result accordingly, making it more effective at handling never-before-seen search queries.
A Google patent granted this August has an interesting process where it describes something like that in a little different way:
The process from the patent includes:
- Collecting query term substitution data for one or more query terms that occur in a received query;
- Collecting query term substitution data for one or more query terms that occur in subsequent queries that include the concept;
- “Includes the concept” means it is adjacent to the one or more query terms in the subsequent queries;
- Collecting query term substitution data for one or more query terms in a context of the concept;
- Determining a substitution rule in a context of the concept based on the collected query term substitution data.
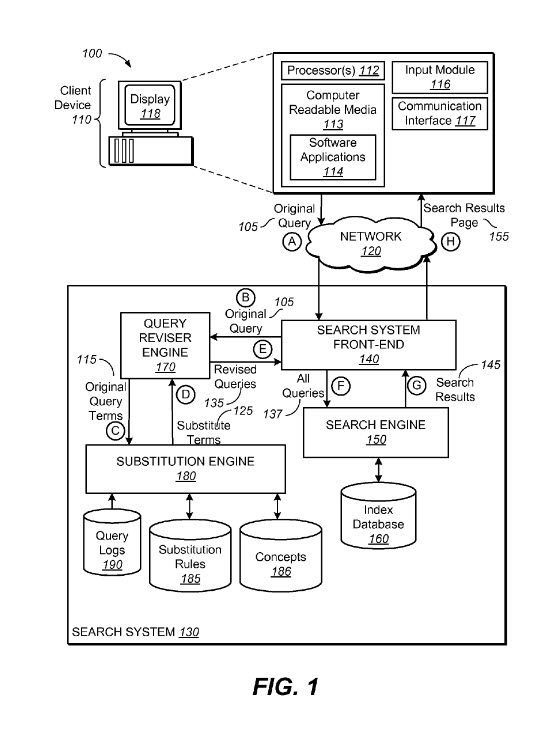
The Substitute Engine that helps rewrite queries
Related Content:
Advantages of the Process in the Patent
(1) To identify a context in a query, the search system traditionally can track only one or two words around a query term due to computation complexity. But, a concept can include more than two words and this approach enables more complex queries to be re-written.
(2) A substitute term rule in a specific context identified by a concept can be determined empirically from user interactions with search result data. By extending the formation of a context beyond two words, the search system can determine substitution rules directed to more specific contexts and potentially improve search results.
The patent is:
Using concepts as contexts for query term substitutions
US 9104750 B1
Application number: US 13/650,322
Publication date: Aug 11, 2015
Filing date: Oct 12, 2012
Inventors: Kedar Dhamdhere, Thomas Strohmann, P. Pandurang Nayak, Robert Spalek
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for collecting query term substitution data based on one or more identified concepts.
According to one implementation, a method includes receiving a query that includes at least three sequential query terms; determining that the sequential query terms represent a concept; and in response to determining that the sequential query terms represent a concept, collecting query term substitution data for one or more query terms that occur in queries that include the concept.
Similar Behavior in the Past
I’ve written three posts that seem to be related to this one in the past, and they are:
- The Google Hummingbird Patent?
- How Google May Substitute Query Terms With Co-Occurrence
- How Google May Rewrite Your Search Terms
Substitute Terms in Query Rewriting
When someone performs a query at Google, the results that are returned can be unique, and include additional results within them than they may have had in the past. This type of revision can be done by adding to the original query additional terms that are substitute terms of terms that show up first in the original query.
If you want to learn this process, I do recommend that you go through the patent carefully, but I wanted to provide three examples from the patent that illustrate the process behind it. For each of these three, I have the original query, and then a rewritten one, and a passage from the patent that explains part of the transformation from the original query to the query with Substitute terms in them.
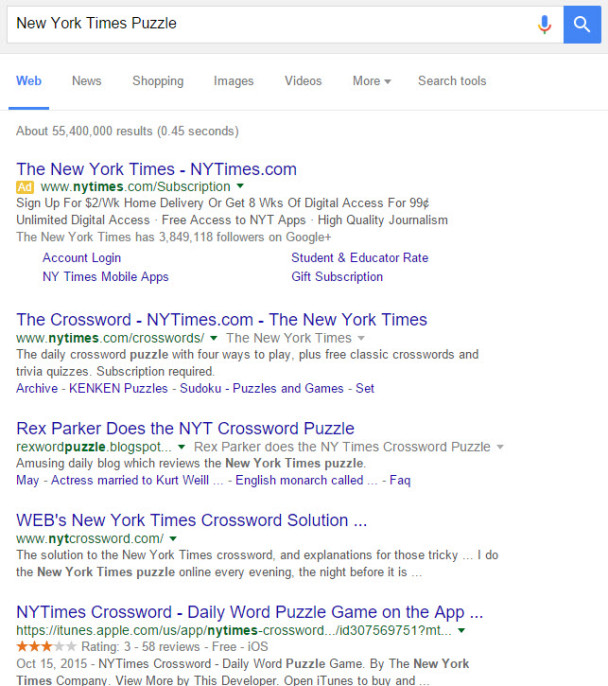
New York Times Puzzle Example
1 – Original query = “New York Times Puzzle”
2. Revised query = “Puzzle?Crossword (New York Times)”
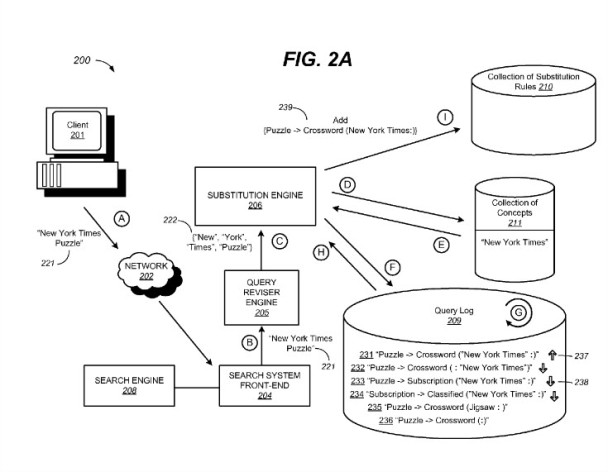
During state (I), the substitution engine analyzes the aggregated query term substitution data, and determines whether one or more substitution rules may be generated from the analysis. For one example, the substitution engine may determine from the query term substitution data that the term “Crossword” is frequently a substitute term for the term “Puzzle” in the context of the concept “New York Times,” as indicated by a positive indication. In some implementations, the indication may be a quantitative score assigned to the query term substitution data in the query log, and the quantitative score can be analyzed by one or more criteria in the substitution engine’s evaluation of a potential substitute term. For another example, the substitution engine may determine from the query term substitution data that the term “Subscription” is not frequently a substitute term for the term “Puzzle” in the context of the concept “New York Times,” as indicated by a negative indication. Here, the substitution engine determines that the term “Crossword” is frequently a substitute term for the term “Puzzle” in the context of “New York Times”, and sends an indication to the collection of substitution rules to add the substitution rule “Puzzle?Crossword (New York Times :)” to the collection. For subsequent user queries that contain original query terms “New York Times Puzzles”, the substitution engine may then apply the substitution rule “Puzzle?Crossword (New York Times)” and communicate with the query reviser engine to include the substitute term “Crossword” in the revised query.
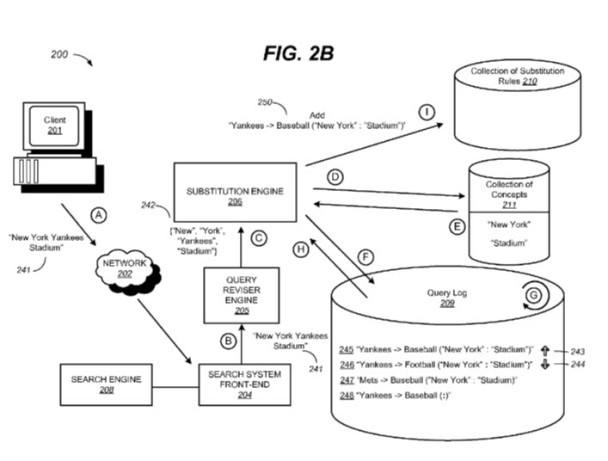
New York Yankees Stadium Example
1. Original query = “New York Yankees Stadium”
2. Revised query = “Yankees?Baseball (“New York”: “Stadium”)”
The patent shows us some of the substitutions that the search engine might attempt to apply, and here’s one of the stages of that analysis:
Here, the substitution engine determines that the term “Baseball” is frequently a substitute term for the term “Yankees” in the context of combined concepts “New York” and “Stadium”, and sends an indication to the collection of substitution rules to add the substitution rule “Yankees?Baseball (“New York”: “Stadium”)” to the collection. For subsequent user queries that contain original query terms “New York Yankees Stadium”, the substitution engine may then apply the substitution rule “Yankees?Baseball (“New York”: “Stadium”)” and communicate with the query reviser engine to include the substitute term “Baseball” in the revised query.
‘New York Yankees Stadium’ Query
Social Security Tax Rate Example
1. Original query = “Social Security Tax Rate”
2. Revised query = “Rate?Calculation (“Social Security” “Tax”)”
During state (I), the substitution engine analyzes the aggregated query term substitution data, and determines whether one or more substitution rules may be generated from the analysis. For one example, the substitution engine may determine from the query term substitution data that the term “Calculation” is frequently a substitute term for the term “Rate” in the context of the concepts “Social Security” and “Tax” as indicated by a positive indication. In some implementations, the indication may be a quantitative score assigned to the query term substitution data in the query log, and the quantitative score can be analyzed by one or more criteria in the substitution engine’s evaluation of a potential substitute term. For another example, the substitution engine may determine from the query term substitution data that the term “Benefit” is not frequently a substitute term for the term “Rate” in the context of the concepts “Social Security” and “Tax,” as indicated by a negative indication. Here, the substitution engine determines that the term “Calculation” is frequently a substitute term for the term “Rate” in the context of combined concepts “Social Security” and “Tax”, and sends an indication to the collection of substitution rules to add the substitution rule “Rate?Calculation (“Social Security” “Tax”)” to the collection. For subsequent user queries that contain original query terms “Social Security Tax Rate”, the substitution engine may then apply the substitution rule “Rate?Calculation (“Social Security” “Tax”)” and communicate with the query reviser engine to include the substitute term “Calculation” in the revised query.
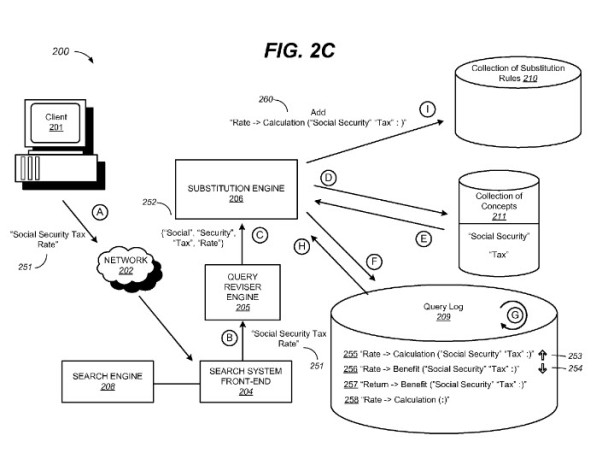
“Social Security Tax Rate” Query
Take-Aways
The substitute data may be taken from text seen in the Web or query log files. The examples point out:
“the term “Baseball” is frequently a substitute term for the term “Yankees” in the context of combined concepts “New York” and “Stadium”.
“substitution engine may determine from the query term substitution data that the term “Calculation” is frequently a substitute term for the term “Rate” in the context of the concepts “Social Security” and “Tax” as indicated by a positive indication.”
“the term “Crossword” is frequently a substitute term for the term “Puzzle” in the context of “New York Times”, and sends an indication to the collection of substitution rules to add the substitution rule “Puzzle?Crossword.”
Google is learning how words work like these examples show, and when words can be used for each other in certain contexts, which could potentially deliver better search results. According to the interview that the Bloomberg News reporters got their information from, “RankBrain impacts the 15% of Google’s queries a day that its systems have never seen before.”
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: