Table of Contents

A searcher looking for answers to meet informational or situation needs of theirs may enter a query into a search engine. That query may often be about one entity, and it may be different for different types of entities. A search engine may analyze queries submitted to it, and process them to understand what the most frequently requested types of information might be for particular entities.
Related Content:
Returning Commonly Requested Information about Entities
Then, when a searcher looks for information about that particular entity, the most commonly requested information about the entity can be provided to them in response to that query. The most commonly requested facts for that particular entity and other similar entities can be provided by the search engine, when it looks at Entity attributes to find answers.
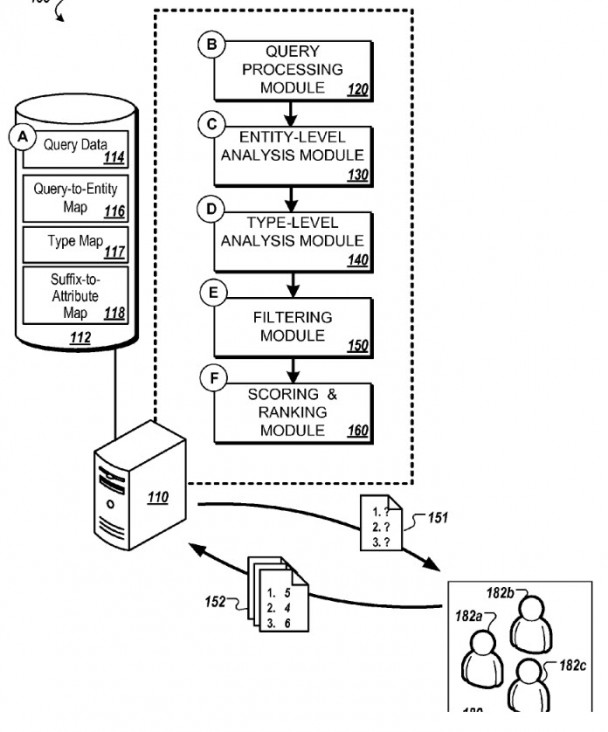
A drawing from the patent of the query analysis stage.
A Google patent describes how it might respond to queries about entities in a manner such as this. The patent provides several details about the process involved, which I’ve written about in this post. The inventors of the patent are listed below.
The steps involved can include:
1) Identifying information within queries in query data, and determining within each of those:
- (i) an entity-descriptive portion that refers to an entity and
- (ii) a suffix;
2) Determining a count of the number of times the one or more queries were submitted;
3) Estimating, based on the count, an entity-level count of query submissions that include the particular suffix and are considered to refer to a first entity;
4) Determining that the entity is a particular type of entity;
5) Determining a type-level count of the query submissions that include the first suffix and are estimated to refer to entities of the particular type of entity; and
6) Assigning a score to the particular suffix based on the entity-level count and the type-level count.
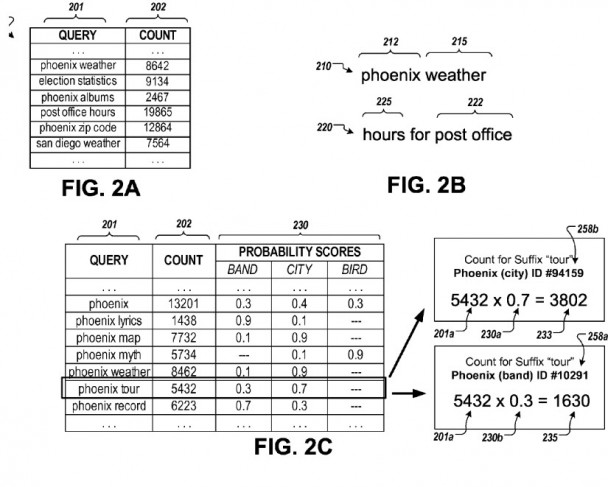
Google identifies suffixes that go with queries of different types.
So, we can see that when people perform queries about Phoenix, the City, they often ask for the Zip Code, weather information, and the Time Zone it is in. When People ask about Phoenix, the band, they usually ask about Albums, Lyrics, and Tours. These suffixes provide a hint of entity attributes people are looking for when searching about a specific entity of a certain type.
The patent tells us that some other steps may be involved in this process that can include:
1) Obtaining scores for one or more other suffixes that occur in query submissions estimated to refer to an entity of the particular entity type; and
2) Ranking the particular suffix and the other suffixes based on their respective scores.
3) Selecting suffixes in a highest-ranking portion of the ranked suffixes;
4) Mapping each of the selected suffixes to a factual attribute of the entity; and
5) Designating the factual entity attributes as frequently requested facts about the entity.
6) When receiving a query submission, determining that the query refers to a specific entity satisfies a threshold;
7) If it does meet that threshold, then this process might access data that point out entity attributes that have been designated as frequently requested facts about that entity, and provide information about the entity for each of those facts in response to the query.
8) Providing information about the entity for each of the entity attributes includes providing a search results page that presents the information about the entity for each of the factual attributes with search results responsive to the query submission.
So, following those steps might result in a wide range of information being returned in response to a query that might be for something such as “Phoenix events” as seen in the image from the patent below:
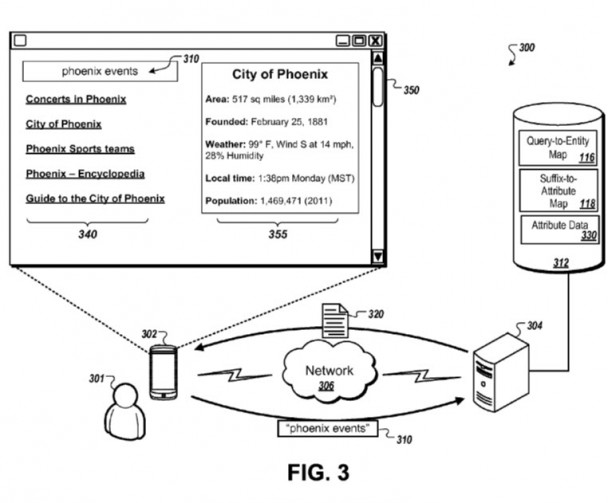
Suffixes for queries are mapped to different attributes about them, That can return information about those to searchers.
The patent also discusses how it might use input from Human Raters, to determine if certain suffixes might be associated with objective facts about an entity.
The human raters might estimate a probability that a query refers to a specific entity, and determine whether or not the request for information is likely something that people are requesting.
Advantages of This Approach
The patent tells us that there are several advantages to using the process described within the patent, which can include:
1) Query data can be used to identify information commonly requested by searchers.
2) Information about a particular entity can be combined with information about other entities of the same type (requests for information about one city may be similar to requests for information about other cities).
3) Human Rater input can be used to identify the probabilities that certain query components represent requests for factual information.
4) Information can be designated as commonly requested information for a particular entity.
5) When replying to a query about a particular entity, the designated information designated as commonly requested can be provided, even if the searcher does not specifically request that information.
The patent is:
Identifying and ranking attributes of entities
Inventors: Benjamin J. Mann, Randolph G. Brown. John R. Provine, Vinicius J. Fortuna, Andrew W. Hogue
Assigned to: Google
US Patent 9,047,278
Granted June 2, 2015
Filed: November 9, 2012
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for query analysis.
Queries are identified in query data, and an entity-descriptive portion and a suffix are determined in each query.
Query counts are determined for several times that the respective queries occur in the query data. Based on the query counts, an entity-level count is estimated, which represents many query submissions that include the particular suffix and are considered to refer to a first entity. The entity is determined to be a particular type of entity.
A type-level count is determined, which represents many query submissions that include the first suffix and are estimated to refer to entities of the particular type of entity.
A score is assigned to the particular suffix based on the entity-level count and the type-level count.
‘
Entity Attributes Take-Aways
If I perform a search for something such as “Phoenix Events” at Google, I do receive a result that responds well to that query, with a carousel that shows off events happening in Phoenix presently:
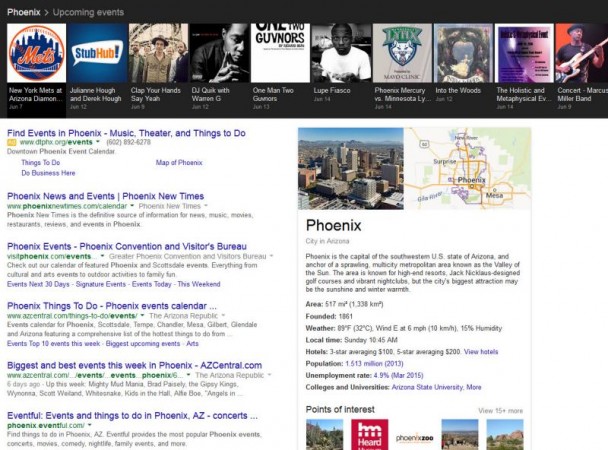
A Carousel of Events in Phoenix from Google.
Even though that may be useful, that isn’t what is being described in this patent, which is aimed at showing entity attributes information about specific entities that people tend to be inquiring about frequently.
At Google’s Recent Developer’s Conference, I/O 2015, Google revealed that they had over 1 Billion Entities indexed, which is a tremendous amount of work. Chances are that Google will leverage that knowledge in ways that will help it find information that people are looking for if Google can recognize an entity within a query, and the query is related to entity attributes that searchers may be interested in.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: