Table of Contents
<
Google May use entity extractions, entity classes, entity properties, and Association Scores from Pages to Build Knowledge Graphs
When Google introduced the Knowledge Graph in 2012, it told us that it was going to start focusing upon things and not strings, and indexing real-world objects. That process is maturing, and we have a chance to watch Google learn how to start crawling the Web to mine data and engage in entity extractions, instead of mining web information such as pages and links. As I wrote recently on Twitter about this:
In web crawling, a node is a page, and an edge is a link between pages; in data crawling, a node is an entity, and an edge is a relationship between entities. It's an evolution in thinking about the web.
— Bill Slawski ⚓ 🇺🇦 (@bill_slawski) February 10, 2019
A recently granted Google patent tells us about how the search engine may perform entity extractions from web pages and store information about them. This goes beyond using knowledge bases as sources of information about entities and moves on to find more than what may be available in such sources by looking at textual passages on web pages. This likely means that we will see knowledge results from more sources than we have in the past, such as Wikipedia. The problem that this patent solves in this early line from the patent:
Conventional knowledge bases, but can fail to provide up-to-date or reliable information about entities and other information desired by users.
We’ve seen Google extract entities from tables and colon-delimited lists at places such as Wikipedia and IMDB. What if they could find that information on Web pages, and extract entities from those pages, and collect properties and attributes about those entities as they crawled web pages. There may be ways to gauge confidence levels of information about those entities and their correctness as well.
Related Content:
As shown in these images from the patent, Google calculates association scores between entities and connected attributes (more about association scores below.)
I’ve written about something similar in the post: How Google’s Knowledge Graph Updates Itself by Answering Questions. The focus of that post was how Google might update existing knowledge graphs, rather than finding information about entities on web pages, and recognizing them, how they may join with other classes of entities. Relying upon knowledge bases instead of treating the Web as a large database seems like a partial step. If it is possible to perform entity extractions in an intelligent and useful way, depending upon a human moderated encyclopedia on the Web wouldn’t be necessary. In a few places in the past, Google had said that they prefer web-scalable approaches to organize information on the web (like when they discontinued the Google Directory, which was from a source that was by people.)
This recent patent discloses a different approach that helps Google to perform entity extractions and other information about those entities, from sources added to the Web instead of adding to a knowledge base on the Web, including new Web pages and news sources.
The patent has a summary section in its description where it tells us about the process it protects. It summarizes those in a few words like this:
The disclosed embodiments may provide systems and methods for determining classes and attributes of new entities, as well as association scores reflecting degrees of relatedness and levels of confidence in the determined relationships. The disclosed embodiments may determine these classes, attributes, and related scores based on surrounding lexical contexts in which the new entities appear and known entities proximate to each new entity. Aspects of the disclosed embodiments also provide systems and methods for dynamically updating and storing determined relationships in real-time or near real-time.
It expands upon those in a little more detail by giving us a step-by-step look at a process which it refers to as “Identifying Entity Candidates.”
Identifying Entity Candidates for Entity Extractions
- An entity candidate is in a document accessible over a network.
- The detected entity candidate is a new entity based on one or more entity models stored in a database.
- A known entity is next to the new entity and the known entity is in the one or more entity models.
- A context next to the new entity and the known entity has a lexical relationship to the known entity.
- A second entity class associated with the known entity and a context class is also associated with the context.
- A first entity class connects with the new entity based on the second entity class and the context class.
- A first entry in the database depends on at least one of the entity models, the entry reflecting the association between the first entity class and the new entity.
The patent these entity Candidates are in is this one about entity extractions and storing information about those entities:
Computerized systems and methods for extracting and storing information regarding entities
Inventors: Christopher Semturs, Lode Vandevenne, Danila Sinopalnikov, Alexander Lyashuk, Sebastian Steiger, Henrik Grimm, Nathanael Martin Scharli and David Lecomte
Assignee: GOOGLE LLC
US Patent: 10,198,491
Granted: February 5, 2019
Filed: July 6, 2015
Abstract
Computer-implemented systems and methods are provided for extracting and storing information regarding entities from documents, such as webpages. In one implementation, a system is provided that detects an entity candidate in a document and determines that the detected candidate is a new entity. The system also detects a known entity proximate to the known entity based on the one or more entity models. The system also detects a context proximate to the new and known entities having a lexical relationship to the known entity. The system also determines a second entity class associated with the known entity and a context class associated with the context. The system also generates a first entity class based on the second entity class and the context class. The system also generates an entry in the one or more entity models reflecting an association between the new and the first entities.
Entity Extractions – Entities, Entity Classes, Entity Instances and Entity Attributes
One of the first steps in the process involved in this patent involves recognizing entities. The patent provides some information about what entities are, and gives us several examples:
In certain aspects, an entity may reflect a person (e.g., George Washington), place (e.g., San Francisco, Wyoming, a particular street or intersection, etc.), or thing (e.g., star, car, politician, doctor, device, stadium, person, book). By way of further example, an entity may reflect a piece of literature, an organization (e.g., New York Yankees), a political body or party, a business, a sovereign or governmental body (e.g., the United States, NATO, the FDA, etc.), a date (e.g., Jul. 4, 1776), a number (e.g., 60, 3.14159, e), a letter, a state, a quality, an idea, a concept, or any combination thereof.
On top of those definitions of an entity, we are also told about entity classes and subclasses, and how entities may fit into different classes and subclasses. This is important because the search engine will try to fit entities into different classes as it learns about them.
So what is an entity class or subclass?
The patent describes those in-depth:
In some aspects, an entity may be associated with an entity class. An entity class may represent a categorization, type, or classification of a group or notional model of entities. For purposes of illustration, for example, entity classes may include “person,” “galaxy,” “baseball player,” “tree,” “road,” “politician,” etc. An entity class may be associated with one or more subclasses. In some aspects, a subclass may reflect a class of entities subsumed in a larger class (e.g., a “superclass”). In the illustrative class list above, for example, the classes “baseball player” and “politician” may be subclasses of the class “person,” because all baseball players and politicians are human beings. In other embodiments, subclasses may represent classes of entities that are almost entirely, but not completely, part of a larger superclass. Such an arrangement may arise in situations containing outliers or fictional entities. For example, the class “politician” may be a subclass of the class “person,” even though some fictitious entities are nonhuman politicians (e.g., “Mas Amedda”). The disclosed embodiments provide ways of handling and managing these kinds of relationships, as further described below. Both classes and subclass may represent entity classes and may constitute entities themselves.
A data instance is an example of a specific entity that fits into a class or a subclass. Thomas Jefferson is an instance of a “US President,” and “Mike Trout” is a specific instance of a “professional Baseball Player.”
The patent works on gathering information about entities, and it collects information about entities that it refers to as “Entity Attributes.” As is in this drawing from the patent:
These can include properties of entities and also relationships between entity classes. The patent provides a deep look into what an attribute may be as well:
Entities may be associated with one or more entity attributes and/or object attributes. An entity attribute may reflect a property, trait, characteristic, quality, or element of an entity class in some aspects. In some aspects, every or substantially every instance of an entity class will share a common set of entity attributes. For example, the entity “person” may be associated with entity attributes “birthdate,” “place of birth,” “parents,” “gender,” or, in general, “has attribute,” among others. In another example, an entity “professional sports team” may be associated with entity attributes such as “location,” “annual revenue,” “roster,” as so on. In other embodiments, an entity attribute may describe how an entity relates to another entity. For example, entity attributes may describe relationships between entity classes such as “is a,” “is a subclass of,” or “is a superclass of,” or “contains.” For instance, the class “star” may be associated with an entity attribute “is a subclass of” with entity class “celestial object.”
When it comes to entity extractions, we end up seeing key-value pairs used to tell us more about specific entities:
In certain aspects, an object attribute may reflect a relationship between an entity class instance with a particular attribute value. For example, the entity “George Washington” may be associated with an object attribute “has birthdate” with a value “Feb. 22, 1732.” In some embodiments, the value of an object attribute may itself reflect an entity. For instance, in the example above, the date “Feb. 22, 1732” may reflect an entity.
This approach to collecting information about entities includes attributes that may be common in subclasses that those exist within:
In some embodiments, entities and subclasses inherit the attributes from the superclasses from which they derive. For example, the class “U.S. President” may inherit the attribute “birthdate” from a “person” superclass. Moreover, in certain embodiments, superclasses may not necessarily inherit the attributes of their subclasses. By way of example, the class “person” may not necessarily inherit the attribute “stolen bases” from the subclass “professional baseball player,” or the attribute “assumed office date” from the subclass “U.S. President.”
Context databases and Entity Extractions
I recognized “Contexts” from some of the schemas that I have seen in the past. There’s one that is a pending Schema vocabulary, using the term “Knows about,” where you could use it to describe a person acting in a specific profession as having experience of a certain type. These context terms are similar because they help provide more information about entities that give you information about them. The passage about context databases from the patent does describe them well:
In some embodiments, context database may store, relate, manage, and/or provide information associated with one or more contexts. A context may reflect a lexical construction or representation of one or more words (e.g., a word, phrase, clause, sentence, paragraph, etc.) imparting meaning to one or more words (e.g., an entity) in its proximity. In certain embodiments, a context is in an n-gram. An n-gram may reflect a sequence of n words, where n is a positive integer. For example, a context may include 1-grams such as “is,” “was,” or “concurreBesidestion, exemplary contexts may include 3-grams such as, for instance, “was born on,” “is married to,” “stole second base,” or “wrote a dissent.” Contexts (and n-grams) may also include gaps of any length, such as the 2-gram “from . . . until . . . .” As described herein, an n-gram may represent any such sequence, and two n-grams need not represent the name number of words. For example, “scored a goal” and “in the final minute” may both constitute n-grams, despite containing a different number of words.
Learning about entities and contexts is a matter of learning a meaningful vocabulary because doing so can be helpful when it comes to learning about how the process behind this patent works, and how Google may engage in data mining to extract information about entities, their attributes, and properties, and the contexts we see them in. Contexts are more complex than just a short n-gram that helps provide context to an entity. This next section of the patent tells us about context classes and context entities:
In certain embodiments, a context may indicate the potential presence of one or more entities. The one or more potential entities specified by a context may be herein referred to as “context classes” or “context entities.” However, these designations are for illustrative purposes only as they are not intended to be limiting. Context classes may reflect a set of classes typically arising in connection with (e.g., having a lexical relationship with) the context. In some aspects, “context classes” may reflect specific entity classes. By way of example, the context “is married to” may be associated with a context class of entity “person,” because the context “is married to” usually has a lexical relationship to human beings (e.g., has a lexical relationship to instances of the “person” class). In this example, for instance, the sentence “Jack is married to Jill” indicates that both “Jack” and “Jill” are of class “person,” due to, at least in part, the context class(es) of the context “is married to.” In another example, the context “has a pet” may be associated with context classes such as “animal,” “cat, “dog,” “domesticated animal,” and the like. Moreover, in this alternative example, the context “has a pet” may signal the presence of entity classes that are not coextensive, because two instances of the same class typically do not share a lexical relationship (e.g., a pet-master attribute relationship). The interpretation and generation of context classes are explained in further detail below.
Association Scores involving Entity Extractions
The patent goes into more detail about context classes and context entities, and those are worth looking at in more detail. But a section of the patent that seemed worth learning about involved something it refers to the calculation of association scores during entity extractions:
In some aspects, entity database and/or context database may also store information relating to one or more association scores. An association score may reflect a likelihood or degree of confidence that an attribute, attribute value, relationship, class hierarchy, designated context class, or other such association is valid, correct, and/or legitimate. For example, in some embodiments, an association score may reflect a degree of relatedness between two entities or a context and an entity. Association scores may be determined via any process consistent with the disclosed embodiments. For example, as explained in greater detail below, a computing system (e.g., server) may determine association scores using factors and weights such as the reliability of the sources from which the association score is generated, the frequency or number of co-occurrences between two entities in content (e.g., as a function of total occurrences, the total number of documents containing one or both entities, etc.), the attributes of the entities themselves (e.g., whether an entity is a subclass of another), the recency of discovered relationships (e.g., by giving more weight to more recent or older associations), whether an attribute has a known propensity to fluctuate (e.g., periodically or sporadically), the relative number of instances between entity classes, the popularity of the entities as a pair, the average, median, statistical, and/or weighted proximity between two entities in analyzed documents, and/or any other process disclosed herein. In some aspects, the system may itself generate one or more association scores. In certain aspects, the system may preload one or more association scores based on pre-generated data structures (e.g., stored in databases 140 and/or 150).
Interestingly, things such as the reliability of sources may play a role in the association scores assigned to a relationship between an entity or a context and an entity. The next section looks at what they call “the ratio of co-occurrences between a context and an entity.”:
In one embodiment, for instance, a computing system (e.g., server) may generate an association score between a context and an entity by determining the ratio of co-occurrences between the context and the entity (e.g., the specific entity, an instance of the entity class, etc.) to all occurrences of that context and/or entity across network documents. One illustrative expression, for instance, may take the form A=P(E, C)/P(C), where A is an example association value between the entity and the context, P(C) is the probability of finding the context in a section of text (e.g., a document, one or more webpages, a corpus, etc.), and P(E, C) is the probability of finding both the context entity co-occur in the section. In this example, the association score may reflect the conditional probability of finding an entity E when the context C appears. Another illustrative expression for an association score may take the form of A=N(E, C)/(N(E)+N(C)-N(E, C)), where N(E) is the number of instances the entity appears in a section (e.g., a corpus), N(C) is the number of instances the context appears in the section, and N(E, C) is the number of instances of both entity E and context C appear together in the section. Similar expressions may be used to generate association scores between two entities.
This example of specific entity classes and contexts makes it clear how association scores may help understand how such scores could be useful:
By way of example, the server may determine that the context “receives a pass from” co-occurs with instances of the entity classes “basketball player” and “person” 35 and 97 percent of the time the context appears in all analyzed documents, respectively. The system may determine these frequencies of co-occurrence by using, at least in part, entity and context models to determine relationships between entities (e.g., to determine “LeBron James” is an instance of class “basketball player”). In this example, the server may determine that the association scores relating the context “receives a pass from” to “basketball player” and “person” are respectively 0.35 and 0.97.
Note that these co-occurrences are from over a corpus of documents, instead of one.
We have some other examples of other factors that may play into the calculation of association scores:
Association scores may account for other considerations by incorporating one or more weights for each occurrence of an entity or context. In some aspects, the computing system may apply weights to account for factors such as temporal weights (e.g., to weigh recent documents or occurrences more heavily), reliability weights (e.g., to weigh more reliable sources more heavily), popularity weights (e.g., to weigh more popular sources more heavily), proximity weights (e.g., to weigh entities/contexts occurring in closer proximity to one another more heavily) and any other type of weight consistent with the disclosed embodiments. In certain aspects, a weight may reflect the relative importance of a particular document or individual occurrence compared to others (e.g., the weights for all occurrences sum to 1.0), the importance of a document or occurrence on an absolute scale (e.g., each weight reflects an independent rating), or any other measure indicating the relatedness between two entities or contexts (e.g., the proximity between a context and an entity).
What may a low association score mean?
Thus, in some embodiments, a low association score may indicate that a data source on which a relationship is based is generally untrustworthy or unreliable. In other embodiments, a low association score may indicate that co-occurrences of the subject pair do not occur in recent documents. In still other embodiments, a low association score may indicate that the co-occurrences between the pair are rare (e.g., few “politicians” are “professional basketball players”). In yet other embodiments, the association score may reflect a combination of many such factors. In some aspects, a system (e.g., server or a computing system in connection with databases) may update and modify association scores over time (e.g., based on new documents, contexts, and attributes).
Association scores give us an idea of likelihoods:
An association score may take the form of a numerical number (e.g., 0.0 to 1.0, 0 to 100, etc.), a qualitative scale (e.g., unlikely, likely, very likely), a color-coded scale, and/or any other measure or rating scheme capable of specifying levels of degree. For example, in one embodiment, an entity database may store an association score of 0.84, reflecting that the likelihood that entity “Bryce Harper” is associated with an attribute “birthdate” having a value “Oct. 16, 1992.” This may indicate, for example, that the system considers Bryce Harper’s birthdate to be Oct. 16, 1992, with 84% accuracy. Also, “Bryce Harper” may be associated with an entity class “person” via attribute or relationship “is a” with an association score of 1.0, indicating a certainty that Bryce Harper is a person. In another example, the context “scored a goal” may be associated with context classes “soccer player,” “hockey player,” and “person” with association scores of 0.64, 0.49, and 0.98, respectively. These exemplary values may indicate, for instance, that it is more likely that the context pertains to soccer players over hockey players, and likelier still that the sentence pertains to one or more persons generally over soccer players in particular. As indicated above, the one or more entity databases (e.g., entity database) and context databases (e.g., context database), server, and/or client device may store, generate, determine, archive, and index entities, attributes, contexts, context classes, association scores, and any other information in any form consistent with the disclosed embodiments.
Knowledge Graphs with Association Scores During Entity Extractions
The patent describes an example Knowledge graph with association scores included with each edge that connects entities to attributes or values:
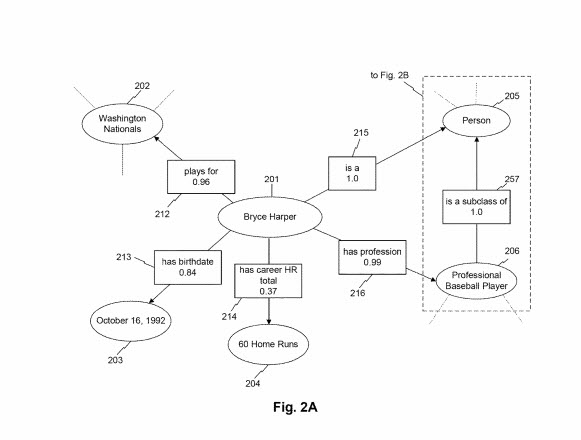
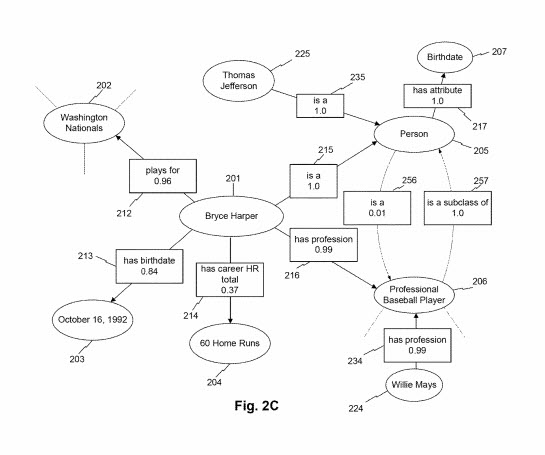
In some aspects, the knowledge graph may comprise a plurality of nodes, each node reflecting an entity. The knowledge graph may also include one or more edges reflecting attributes describing relationships between the entities and the values of particular attributes. In certain embodiments, the knowledge graph may also include an association score for each edge (e.g., each attribute or associated value) contained therein, although such association scores are not required. In the illustrative knowledge graph depicted in FIG. 2A, for instance, the entity node “Bryce Harper,” reflecting a particular entity, is connected to another entity, “Washington Nationals,” via object attribute “plays for” with an association score of 0.96. These values and relationships may indicate, for example, that Bryce Harper is a player for the Washington Nationals and that the system associates this attribute with a degree of confidence of 0.96. The entity “Washington Nationals” itself may be associated with other entities not shown, indicated by the hashed lines emanating from the node. Other entities are depicted in FIGS. 2A-2C and 3 can similarly be associated with other nodes and attributes not shown, and the depiction of certain relationships and values therein is merely illustrative.
The association scores can provide a sense of confidence in the correctness of a fact related to an entity. Another set of examples related to Bryce Harper:
FIG. 2A also depicts associating the node “Bryce Harper” with date entity node “Oct. 16, 1992” and value entity node “60 Home Runs” via attributes “has a birthday” and “has career HR total,” respectively. These attributes have respective association scores of 0.84 and 0.37, indicating that the system is more confident in the value associated with attribute relationship “has birthdate” than the value associated with “has career HR total.” The difference in these association scores may arise, for instance, due to the reliability of the sources used to generate such relationships, the frequency of co-occurrences between the entities, the fact that one of the values of the attributes (node 204) is changing over time, and/or other factors, consistent with the disclosed embodiments.
Image a huge knowledge graph covering many different types, each with many properties or attributes associated with them, and association scores providing confidence levels between the entities and classes and subclasses. The patent shows us that this would be likely:
An entity node may also be associated with entity classes and subclasses, connected via attributes describing the nature of the relationship between an entity and an entity class. For example, FIG. 2A depicts connections between node “Bryce Harper” and the entity classes “person” and “professional baseball player” via respective edges “is a” and “has a profession.” These attributes have association scores of 1.0 and 0.99, respectively. The illustrative attributes and association scores indicate that the system considers Bryce Harper to be a person whose profession is a professional baseball player with certainty or near certainty.
We also learn from low association scores about entity classes and other entity classes:
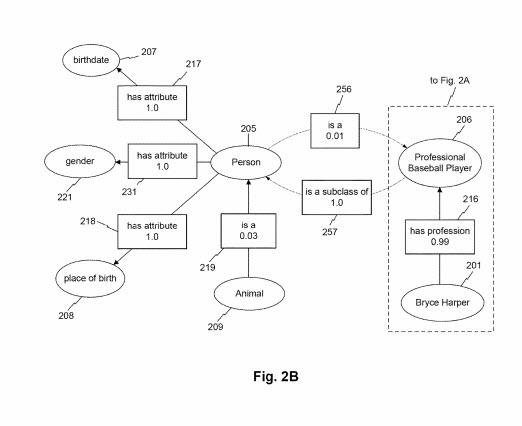
As depicted in FIG. 2B, an entity class may also be associated with other entity classes through entity attributes. For example, the class “animal” may be associated with the class “person” via the attribute “is a.” In this example, the association score corresponding to the attribute is 0.03. This may indicate, for example, that instances of the “animal” class 209 are rare instances of the “person” class (e.g., due to the prevalence of nonhuman animals such as other mammals, insects, birds, fish, etc.). While not depicted in FIG. 2B, the class “person” may be associated with a reciprocal attribute “is a” or “is a subclass of,” etc., in connection with the “animal” node. Such an attribute may be associated with a higher association score (e.g., 0.94), indicating that the class “person” is a subclass of “animal.” For example, FIG. 2B depicts the class “professional baseball player” associating with the class “person” with the entity attribute “is a subclass of” with association score 1.0. In contrast, the class node “person” may be associated with the node “professional baseball player” via the attribute “is a” with an association score of 0.01. This lower association score may reflect, for example, the strong prevalence of entities of class “person” that are not of class “professional baseball player” (e.g., most people are not professional baseball players). FIG. 2B further depicts how the professional baseball player class node may associate with entity node “Bryce Harper” via the attribute “has a profession,” as discussed in connection with FIG. 2A.
Associations between entity types and context classes in a context graph may tell us specific information about those entity types and contexts:
In some embodiments, the entity classes included in the context graph may represent context classes associated with a particular context (e.g., context). In such embodiments, an association score linking contexts to their context classes (and any included subclasses, etc.), may reflect a degree of validity or relatedness between the context class and the context (e.g., edge) and/or the degree of relatedness between entity classes themselves (e.g., edge). In some aspects, the association score may thus reflect a likelihood that context signals the presence of the associated context class or an instance of that context class. For example, as shown in FIG. 2D, the context node “receive(s) a pass from” may be associated with five context classes. In this example, the context “receive(s) a pass from” is associated with context classes “person,” “baseball player,” “basketball player,” “hockey player,” and “soccer player” Each of these associations may include a corresponding association score, such as scores. These association scores are illustrated with the accompanying phrase “takes class” to indicate a likelihood or probability that the context indicates the presence of a particular class or class instance.
For example, because it may be rare for a member of class “baseball player” to “receive(s) a pass from” (context) another player, the association score associated with this context class is 0.02, as shown in the line item. As explained above, this value may be generated from the frequency of co-occurrences between the context and an instance of the “baseball player” class over network sources, the reliability of those sources, etc. In contrast, the association scores between context and the remaining entity classes are relatively higher. For example, the association scores for the context classes “hockey player,” “soccer player,” and “person” are 0.47, 0.62, and 0.97, respectively. These values may indicate that, in a vacuum, the context is more likely to refer to a soccer player than a hockey player, but it most likely to refer to an entity of the class “person” (e.g., as opposed to a court, agency, or organization, etc.).
As the search engine visits pages on the Web, and Performs entity extractions, and learns about entities, entity classes, and specific instances of those classes, and the contexts in which they appear, and calculates association scores, it may continue to crawl pages and add to the entity information it knows about as it engages in entity extraction and storing information about entities.
The patent tells us about entity extractions being an ongoing process:
Systems and methods consistent with some embodiments may identify entities from documents, assign entity classes to them, and associate them with properties. The assigned classes and attributes may be based, at least in part, on the context in which the new entity appears, the entity classes of entities proximate to the new entity, relationships between entity classes, association scores, and other factors. Once assigned, these classes and attributes may be updated in real-time as the system traverses additional documents and materials. The disclosed embodiments may then permit access to these entity and context models via search engines, improving the accuracy, efficiency, and relevance of search engines and/or searching routines.
Parsing Documents for Entity Extractions and Storing Information About Entities
The process behind the search engines going through pages and finding entities and learning more about them:
When the process finishes searching for new entity candidates, the system may determine whether any new entity candidates have been identified (step 410). If not, the process may end or otherwise continue to conduct processes consistent with the disclosed embodiments (step 412). If the system has found one or more new entity candidates, the process may determine whether the new entity candidate is a new entity using processes consistent with those disclosed herein. If so, the process may include determining one or more entity classes and/or attributes of the new entity (step 414). This procedure may take the form of any process consistent with the disclosed embodiments (see, e.g., the embodiment described in connection with FIG. 6). This step may also include generating or determining one or more association scores corresponding to the identified classes and attributes in some embodiments. For example, the system may determine that a new entity “John Doe” is likely an instance of a class “professor,” (which may be in turn a subclass of the classes “teacher” or “person,” etc.,) and has a birthdate “Sep. 28, 1972.” Further, the process may include generating association scores representing the degree of certainty the system associates with these relationships.
As the search engine collects this information about entities it finds, it may store that information as data in a knowledge graph “with nodes and edges reflecting the new entity, its classes, attributes, and corresponding association scores, etc.”
The Entity Extractions and Entity Information Storage Process
The patent does describe how it might take prose text on pages. It does this to look for entities, context, classes, properties, and attributes and calculate association scores. It stores these in a knowledge graph where the entities and facts about them are the edges. The contexts between those are the edges.
This is what a knowledge graph is.
The patent stressed that it would try to update the knowledge graph dynamically, and in real or near real-time. That would be the ideal benefit of the entity extractions process described in this patent. This would be entity-first indexing of the Web.
Last Updated September 21, 2019
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: