Table of Contents
Sometimes Some Words May Be Offensive or Non-Offensive Based on How They Are Used
In some parts of the World, the word “Shag” describes an activity that some people might find offensive. I grew up in a home where we didn’t use that meaning of that word and had shag carpeting in many rooms. It wasn’t until I watched an Austin Powers movie (Austin Powers: The Spy Who Shagged Me) that I became aware of another meaning for that word.
Related Content:
A patent from Google is about how offensive content might be identified and software used to redact (or obfuscate) potentially offensive words before such content is served to end users of that software. Some software will delete all instances of an offensive term if that term is found in a “pre-defined list of offensive terms.” If a term that is sometimes considered offensive is found in a context where it is seen as non-offensive it may not be redacted.
Where Offensive Content Might Be Redacted?
The description of the patent covers a lot of ground, while not summarizing the processes behind it in a helpful way. As you go through it you see it covering social media posts, transcripts of videos, text messages, Chat, Web pages, user-generated content on commercial websites.
There is no mention that a page that contains offensive content might be considered lower quality content than other pages on the Web, but there is the option that kind of content could be obfuscated in Google’s Index, or possibly in places where Google may have some control over the publication of content (like the departed Google+ or Youtube possibly), or when possibly indexing content from forum threads or user comments in blogs.
Another place where there might be questions about content and whether it is offensive maybe when a site owner quotes others or includes user-generated content on their pages.
An example from the patent drawings involving the word “bloody” in content, and how it might be redacted in at least one instance:
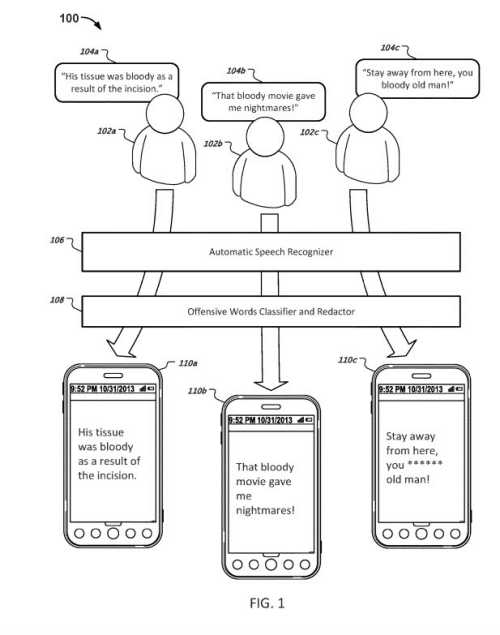
Why Classify Offensive Content?
Some content may not be welcomed by visitors to the Web or readers of youtube comments or transcripts or in social media.
Some words that have multiple meanings that could be offensive to some people from some places, and inoffensive in other contexts, like when a customer of a carpet store adds a review saying how much he loves the shag carpeting he purchased from the store. Obsfucating that review might confuse some potential customers because in that context it is in no way offensive.
Training a Classifier to Identify Offensive Content
The techniques behind the patent are to train a classifier to tell when a term that potentially may be offensive is being used in an offensive or a non-offensive way.
This can be done to possibly redact the potentially offensive content, without removing it if it is not being used offensively.
The patent tells us that:
The classifier can be trained to analyze one or more signals (e.g., features) from the content of the text sample as a whole to determine whether the term is being used in a profane, derogatory, or otherwise offensive manner in the text sample.
We are also told that a classifier may look beyond content-based information to use context when determining whether a text sample contains a degree of offensiveness.
The patent tells us that the word “shag may be offensive in some contexts by not in others:
For example, the word “shag” may be offensive in certain contexts, but not in others:
Thus, “I hope we can shag tonight” may be offensive, whereas “This great wool shag has a beautiful pattern” likely is not.
The context of the word “shag” from the content from each of those text samples may be used to determine that the first sample is offensive and that the second sample is non-offensive.
Also, Google could look at external context information, such as if the samples were from a customer at a rug retailer, which shows that it is referring to a type of carpet.
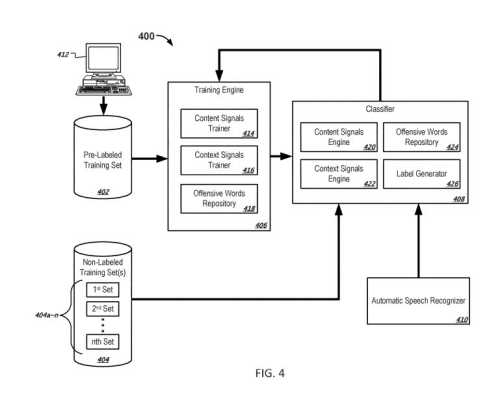
Machine Learning to Train an Offensive Language Classifier
In addition to looking at the content of text samples or contextual information about the textual samples, Google may use machine learning techniques to identify offensive content:
This document further describes that the classifier can be trained using semi-supervised machine learning techniques.
The first set of training samples that include a potentially offensive term can be manually labeled as being either offensive or non-offensive.
The first set of samples can be used to initially train the offensive words classifier.
We are told that a classifier might then be “repeatedly re-trained in multiple training iterations to improve the accuracy of the classifier.”
We are told more about this machine learning approach, and how it can move from using humans to label training data to labeling its training data.
It may also develop a “label confidence score” which indicates “confidence that the label correctly indicates whether the particular potentially offensive term is used offensively in the first text sample.”
This approach can also use information about n-grams to help identify offensive content.
We are also told about a bag of words approach that might look at a “distribution of terms in the text sample.”
The patent goes into describing text samples as utterances from transcripts, which show the range of content covered in the patent, and that it is intended not only include looking at text samples on pages in different applications and web pages, but also in transcripts of videos.
Here is a quick overview of the offensive content classification process described in the patent:
- Obtaining a number of text samples
- Identifying, from among the plurality of text samples, the first set of text samples that each includes a particular potentially offensive term
- Obtaining labels for the first set of text samples that indicate whether the particular potentially offensive term is used offensively in respective ones of the text samples in the first set of text samples
- Training, based at least on the first set of text samples and the labels for the first set of text samples, a classifier that is configured to use one or more signals associated with a text sample to generate a label that indicates whether a potentially offensive term in the text sample is used offensively in the text samples
- Providing, to the classifier, a first text sample that includes the particular potentially offensive term
- Obtaining, from the classifier, a label that indicates whether the particular potentially offensive term is used offensively in the first text sample
The Advantages of Following the Offensive Language Classification Process
A classifier labeling text samples that have one or more potentially offensive terms can be trained using what is a relatively small number of pre-labeled text samples.
Not all of the text samples needed in the training set (used to teach the algorithm behind the machine learning) need to be manually labeled.
The output from the trained classifier can be used to select and redact offensive terms from text samples on the Web.
If terms that are potentially offensive terms that are not offensive in the context of a particular text sample may not be redacted.
That means that the classifier may prevent non-offensive terms from being redacted unnecessarily.
And on the plus side, the classifier determines a likelihood that a particular term in a text sample is or is not used offensively in the text sample based on the content of the text sample as a whole rather than considering the term in isolation.
This patent can be found at:
Classification of offensive words
Inventors: Mark Edward Epstein, Pedro J. Moreno Mengibar
Assignee: Google LLC
US Patent: 10,635,750
Granted: April 28, 2020
Filed: April 17, 2018
Abstract
A computer-implemented method can include identifying a first set of text samples that include a particular potentially offensive term. Labels can be obtained for the first set of text samples that indicate whether the particular potentially offensive term is used offensively. A classifier can be trained based at least on the first set of text samples and the labels, the classifier is configured to use one or more signals associated with a text sample to generate a label that indicates whether a potentially offensive term in the text sample is used offensively in the text sample. The method can further include providing, to the classifier, a first text sample that includes the particular potentially offensive term, and in response, obtaining, from the classifier, a label that indicates whether the particular potentially offensive term is used offensively in the first text sample.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: