





Google May Use Direct Answers to Fill Knowledge Graph Information Gaps
Published: April 29, 2015
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

How does Google fill Knowledge Graph information gaps? How is it updated?
One method has involved user input such as people adding to sources of knowledge bases that get used to adding to knowledge graph information, such as Wikipedia, Google Local Business profiles, WikiData, and formerly Google’s Freebase (which has closed down).
A Google patent application published on March 10, 2014, tells us that another approach to filling knowledge graph information gaps involves a process that identifies when some information is missing from a collection of data such as Google’s knowledge graph, and it may generate a question to submit to a question answering service based upon that missing data and a type of entity involved in the missing information, and it may use the response from the question answering service to update the collection of data or the Knowledge Graph. I’ve written about a Google patent that describes how it may generate Direct Questions and Answers to those in the post, Direct Answers – Natural Language Search Results for Intent Queries
Related Content:
How Google Generates Queries to Update its Knowledge Graph
The patent application involving filling in gaps in information with Direct questions is:
Questions answering to populate knowledge base
Publication number WO2014150214 A2
Publication type Application
Application number PCT/US2014/022598
Publication date Sep 25, 2014
Filing date Mar 10, 2014
Priority date Mar 15, 2013
Inventors: Rahul Gupta, Shaohua Sun, John Blitzer, Dekang Lin, Evgenly Gabrilovich
Applicant: Google Inc.
Abstract
Methods and systems are provided for a question answering. In some implementations, a data element to be updated is identified in a knowledge graph and a query is generated based at least in part on the data element. The query is provided to a query processing engine. Information is received from the query processing engine in response to the query. The knowledge graph is updated based at least in part on the received information.
The patent provides a lot of information about the process involved, and I’ve provided details about the process involved, which is included in the patent as developed and described by the inventors listed above.
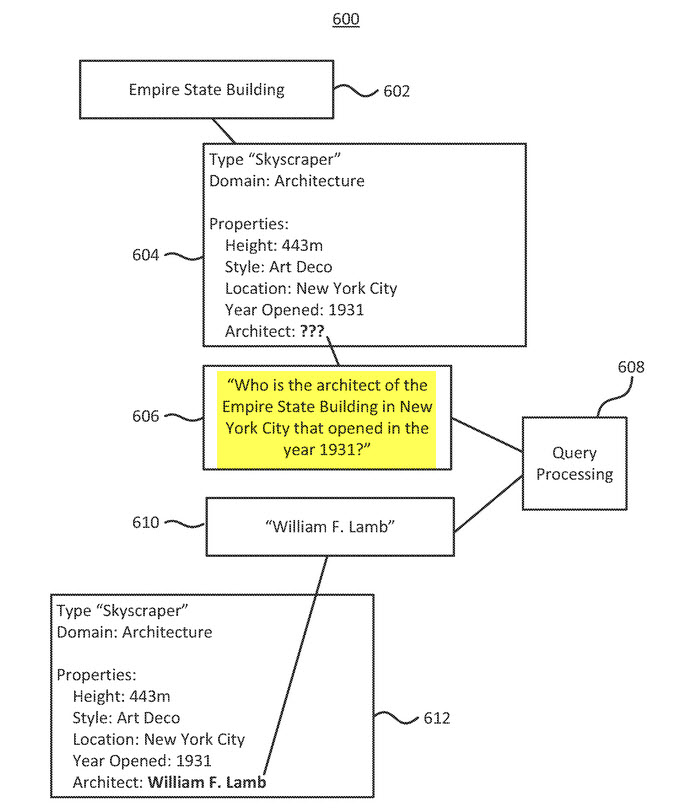
The process described in the patent is “a computer-implemented method,” which starts with (1) identifying an entity reference in a knowledge graph, (2) Understanding the entity type of that entity reference, (3) identifying a missing data element that may be associated with the entity reference, (4) generating a query based on the missing data element (like in the screenshot above from the patent) and the type of the entity reference, with (5) The query is provided to a query processing engine, and (6) A response to the query is returned from a query processing engine in response to the query, and (7) The knowledge graph is updated the knowledge graph based upon the information received.
Some particular features described in the patent filing include:
Identifying a missing data element — can mean comparing properties associated with the entity referenced to a schema table that may be associated with the type of entity it is. (For example, the “Empire State Building” is a Skyscraper, with an attribute of “height” which should be present for all skyscrapers.)
Generating a natural language query – to ask about the missing information, and that query can be expanded to disambiguate the entity involved from other entities that might be confused with that entity (For Example, missing information related to the State of Georgia should be asked about in a natural language query that distinguishes the State of Georgia, from the Eastern European County of Georgia)
Query Processing Step – This process involving finding missing information for a knowledge graph entry involves looking the information up using a query record from the search engine.
Take Aways
The patent is very rich in terms of information about how information involving Entities and properties related to those and the connections between them are stored in the knowledge graph. It also describes how different schemas may be identified about different entity types related to them from a knowledge of the kinds of information that might be stored about them and the relationships between them and other entities.
The patent shares at least one inventor (Evgenly Gabrilovich) with an author of Google’s paper from the last year on the Google Vault, which I wrote about in Good Bye Knowledge Graph, Hello Google Knowledge Vault? Given that part of the focus of the Google Vault was to help clean up missing information from Google’s Knowledge Graph, that’s not surprising.
This patent doesn’t provide too much in the way of describing how “natural language queries” are written to pursue answers about missing knowledge graph information, a patent I wrote about previously that does give out more details was Natural Language Search Results for Intent Queries. I wrote a four-part post that provided a look into the process described in that patent beginning with the post Direct Answers – Natural Language Search Results for Intent Queries
To a degree, this is my second bite at this patent; I posted a blog post about it last November at SEO by the Sea, under the title How Google Might Fill in Missing and Incorrect Data in its Knowledge Graph I was inspired to revisit the topic after seeing many more recent posts about direct answers recently. After trying to understand the NLP approach and How Google might be using it, I’m not convinced that I like it any better than the more data-driven approach I considered in the SEO by the Sea post.