Table of Contents
Another Sign that Apple Search is On Its Way
Apple appears to be working towards developing a search engine. I have written a few posts about patents developed at Apple showing them getting into areas that Google is better known for.
A newer Apple patent shows that Apple has developed a way of re-ranking search results. This new patent tells us how it may rerank search results. Here are some more posts about search at Apple:
5/11/2015 – Here Comes Applebot: The Start of Apple Web Search?
5/16/2015 – Ranking Pages at An Apple Search Engine?
6/25/2016 – Might We Soon See Apple Augmented Reality?
9/10/2020 – Apple Search is Already Here
The new patent is about search technology and how Apple may rerank search results using a blended learning model on a client.
Searchers will often perform a query search to look up information on the Web or other data sources. A query search begins with a client receiving the query string, which goes to a search server. Next, the search server receives a query string and searches for a responsive search result that matches.
Related Content:
The search server then returns the results to the client. The client can search local data (such as on their own phone) using this query string. Each of the results will include a ranking score to blend and rerank search results. Search results with a higher ranking are higher than results with a lower ranking.
A challenge with these results is how to present the results. The search results can have a raw ranking, but they may not reflect a searcher’s preference.
After the client receives and presents the results, the searcher may engage with some of the results (e.g., click on a link for one of the results and spend time interacting with the website referenced by that link) and may also abandon some of these results.
Reranking Search Results at Apple
These engagement results can tell about the search results a searcher prefers or does not prefer.
Other data types can determine which results a searcher prefers, but this type of data is usually private to the device.
Within this patent, a device that can rerank search results on a client device.
The device may receive a crowd-sourced intra-domain model from a server. The intra-domain model is a search result re-ranking model generated based on many searchers interacting with several other devices.
The device further generates a re-ranking model from the crowd-sourced intra-domain model and a local model. The local model includes private data representing a device searcher’s interaction with that device, and the re-ranking model blends results and re-ranks search results.
This method Uses a Crowd-Sourced Intra-Domain Model
The method receives a crowd-sourced intra-domain model from a server. The intra-domain model is a search result re-ranking model generated based on at least device interactions of many searchers interacting with a few other devices. Besides, the method generates a re-ranking model from the crowd-sourced intra-domain model and a local model. The local model includes private data representing a device user’s interaction with that device, and the re-ranking model re-ranks several search results.
Besides, the set of raw features does not reveal private data about the client device user.
Many intra-domain models correspond to many search domains used to generate search results. A choice of the crowd-sourced intra-domain model follows at least a local associated with the client device. The re-ranking model is a neural network model, and the neural network model uses the raw features.
A method re-ranks search results by receiving a search query from a user. This creates search results over many search domains, where a searcher is ranked following a first ranking.
This approach generates a re-ranking model, which includes many intra-domain models is based on many searchers interacting with many other devices. Thus, each of the search domains corresponds to one of the numbers of intra-domain models.
This method re-ranks the search results using the re-ranking model and returns many search results using the second ranking.
Blending Inter Domain Results
Many intra-domain models correspond to many search domains used to generate the number of search results. These include many on-device and off-device search domains. Each of the on-device search domains is from text messages, emails, contacts, calendars, contacts, music, movies, photos, application states, and other installed applications. Each of the off-device search domains is from:
- Maps search domain
- Media store search domain
- Online encyclopedia search domain
- Sites search domain
The intra-domain model is from private information stored on the client device. Finally, the method re-ranks a domain subset of results from the search domains using the corresponding intra-domain model.
This method receives a search query from a searcher.
First, it generates search results over many search domains, where the search results follow a first ranking.
When Re-Ranking Becomes Part of the Process behind the Apple Search Engine
Next, the method generates a re-ranking model, which uses intra-domain models based on on-device interactions of searchers interacting with other devices. Each of the search domains corresponds to the intra-domain models.
The method further re-ranks the search results using the re-ranking model.
Finally, the method presents the number of search results using the second ranking.
The search domains include on-device search domains. Each of the search domains is from:
- Text messages
- Emails
- Contacts
- Calendar contacts
- Music
- Movies
- Photos
- Installed applications
The intra-domain model also looks at private information of the device that the searcher stored on the client device. The machine-readable method also re-ranks a domain subset from the results in the search domains using the corresponding intra-domain model.
The search domains can also include off-device search domains from the private information of the device that the searcher stored on the client device. It can also re-rank the search domains using the inter-domain model. The re-ranking model is a neural network model and can further include a policy model.
This Reranking Model is Crowd-Sourced
The method may also generate a crowd-sourced model from the raw features. The crowd-sourced model includes a crowd-sourced intra-domain model used to rerank search results of a search query for search domains, and a crowd-sourced model inter-domain used to rerank the number of search domains providing the search results of the search query. This method tells us that the crowd-sourced model goes to the client device when the client device requests the crowd-sourced model.
The client device request is opt-in by the client device to receive the crowd-sourced model. This client opt-in request can be an opt-in request to allow diagnostic data collection.
A method generates a crowd-sourced model used to rerank search results on a client device. First, this method receives raw features from devices, where the result features are data that indicates how users of the devices use these devices, and the raw features do not reveal private data about the user. Then, the method generates a crowd-sourced model from the raw features. The crowd-sourced model includes a crowd-sourced intra-domain model used to rerank search results of a search query for search domains, and a crowd-sourced model inter-domain used to rerank the number of search domains providing the search results of the search query.
The method further discloses that the crowd-sourced model goes to the client device to request the crowd-sourced model. The client device request is opt-in by the client device to receive the crowd-sourced model. This client opt-in request can be an opt-in request to allow diagnostic data collection.
A Device that Can Rerank Search Results
The device includes a processor and memory coupled to the processor through a bus. The device further uses a process executed from memory by the processor that causes it to receive a search query from a user and generate the search results over search domains. This further causes the processor to generate a reranking model, rerank search results using the reranking model, and present the second-ranking search results. Finally, the search results use the first ranking. The reranking model includes intra-domain models generated based on on-device interactions of users interacting with other devices. The search domains correspond to one of the numbers of intra-domain models.
This patent to rerank search results is at:
Re-ranking search results using blended learning models
Inventors: Hon Yuk Chan, John M. Hornkvist, Lun Cui, Vipul Ved Prakash, Anubhav Malhotra, Stanley N. Hung, and Julien Freudiger
Assignee: Apple Inc.
US Patent: 11,003,672
Granted: May 11, 2021
Filed: July 12, 2017
Abstract
A method and apparatus of a device that re-rank several search results are described.
In an exemplary embodiment, the device receives a search query from a searcher. Then, it generates the number of search results over many search domains, wherein the number of search results is ranked according to a first ranking.
The device additionally generates a re-ranking model. The re-ranking model includes several intra-domain models generated based on at least based on-device interactions of many users interacting with several other devices. Each of the numbers of search domains corresponds to one of the numbers of intra-domain models.
The device further re-ranks the number of search results using the re-ranking model and presents the number of search results using the second-ranking.
This approach can rerank search results from a search server. Moreover, many details provide a thorough explanation of the present patient-specific details.
Reference in the specification of “an embodiment” means that a particular feature, structure, or characteristic described is included in the invention.
The processes depicted are run by processing logic that uses hardware (e.g., circuitry, dedicated logic, etc.), software (from a general-purpose computer system or a dedicated machine), or a combination of both. Thus, The operations described can be in different orders.
Raw Features In Reranking Search Results
A method and apparatus of a device that can rerank search results received from a search server on the device are described. The device reranks search results received on the device using crowd-sourced models received from a model server. The model server generates the crowd-sourced models from raw features periodically received from many devices. The raw features are data indicating a use of the device, such as:
- Types of results a searcher engages with
- Types of results a searcher abandons
- Application usage history
- How a searcher interacts with installed applications on the device, such as contacts, calendar, email, music, and/or other installed applications
Each of the raw features collected from the different devices is anonymous. Thus, discovering raw features for the device will not lead to discovering personal data stored on that device or which device contributed to that raw feature.
With these raw features, the model server can generate two types of crowd-sourced domain models:
- An intra-domain model
- An inter-domain model
The intra-domain model can cause the device to rank search results within a search domain. There can be more than one intra-domain model for the different on-device search domains supported by the device. There can be a separate intra-domain model for each of the on-device search domains, or there can be one or more common intra-domain models for some or all of the on-device search domains.
The inter-domain model can have the device rank search domains. Each of the intra- and inter-domain models is machine-learning models (e.g., a neural network model). The model server generates the crowd-sourced intra- and inter-domain models and sends these models on the device.
Using On Device Sensitive Data to Rerank Search Results
The device may receive these models. But, instead of using these models to rank the results and/or domains, the device may combine each intra- and inter-domain model with on-device sensitive data to generate local (and personalized) intra- and inter-domain models.
The on-device sensitive data is private data collected about how the searcher uses the device. Still, this data remains resident on the device and is not sent to a server for collection (e.g., not sent to the model server as part of the raw feature collection, not sent to a search server as part of a search request, and/or other types of data collection scenarios).
The on-device sensitive data can include a user’s browser history, application states that include private data, and/or other types of private data.
The device uses the local intra-domain model to rerank search results from on-device search domains such as contacts, email, messages, calendar, application history, music, other media, and/or other types of on-device search domains).
The local inter-domain model is used by the device to rank the on-device search domains.
The device can use an inputted search query to search on-device search domain and/or off-device search domains (e.g., a search query sent to a search server). The device receives the on-device and/or off-device results and reranks the on-device results using the local intra-domain and inter-domain models.
The search server reranks the off-device search results using server-based intra-domain and inter-domain models, which do not include the personalization with the user’s sensitive data. Then, the device integrates the reranked on-device and off-device search results and applies one or more policies that can constrain the reranking, add further rerankings, and/or affect the search result rankings in other ways.
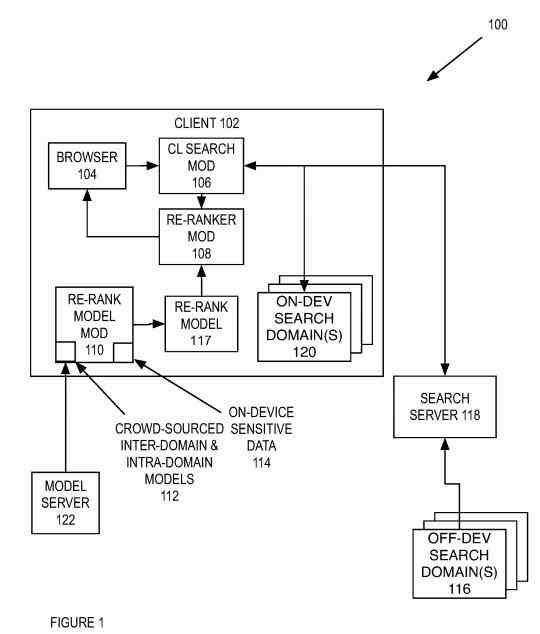
A System That Returns Search Results, Where the Client Can Rerank Search Results
The system includes a client, model server, and search server coupled with a network. The search server collects servers that receive search requests from clients and other devices and returns search results back. The client and servers can be a personal computer, laptop, server, mobile device (e.g., smartphone, laptop, personal digital assistant, music playing device, gaming device, etc.), r any device capable of requesting a search and displaying search results.
Besides, the client, model server, or search server can be a physical or virtual device. For example, the smartphone can be a cellular telephone that can perform many functions of a device.
The client includes a browser to input a query prefix by the searcher. The browser includes a search input field used by the searcher to input the search query. A web browser allows a searcher to search the web or other search domains and retrieve various objects. For example, the browser can allow a searcher to input a search query used to search on-device and/or off-device search domains. The browser includes a search input field, which the searcher uses to input a search request string.
The client sends this search to the server. The search server performs the search over search domains. First, the search server searches for relevant results across many searches off-device domains (e.g., maps, media, wiki, sites, others, or another search domain). Next, the device receives a set of results from the many off-device search domains and ranks these results based on scores generated from each search domain and cross-domain information. Finally, the search server determines the search results from these search domains and sends the search results back to the client.
The Search Process with Re-Ranking and Blending
The client can rerank search results.
First, the browser receives a search request and sends it to the client search module.
Then, the client search module sends the search request to the search server, searching over the search domains.
Finally, the search server determines and scores each search result, where the individual search results score ranks the search results.
Then, the search server sends back the search results, which include the search results scores. Finally, the client search module receives the search results and forwards these search results to the client reranking module.
The client can use the search query to search on-device search domains hosted on the client.
Then, the client searches the on-device search domains to match the search query. The on-device search domains are different data domains that can be indexed and stored on the device for purposes such as messages, email, contacts, calendar, music, movies, other media, installed applications, and/or other types on-device search domains.
The client can receive a set of on-device search results and/or off-device search results from the search server from these on-device search domains. With these sets of search results, the client can rerank these sets of search results using a reranking model.
The reranking model includes an on-device model for intra-domain reranking results within a search domain and an on-device model for inter-domain reranking search domains.
Finally, a policy model is a set of rules to enforce business or searcher interface decisions. The intra-domain and inter-domain models are from crowd-sourced models and on-device sensitive data.
Raw Features Showing How the Searching Device Has Been Used
A model server can receive raw features from many devices and generate a crowd-sourced intra-domain model and a crowd-sourced inter-domain model from these raw features. The raw features are data indicating the device has been used and how. The raw features can include:
- Length of the field in the result
- Query features (e.g., number of query terms and/or other types of query features)
- Query-result features (e.g., cosine similarity and/or other types of query features)
- User-result features (e.g., whether searcher has engaged the result, abandoned the result, distance of searcher, from the result (e.g., the result is a representation of an object in the world)
- Searcher feature (e.g., the device type of result, time of day when query run, and/or another type of searcher result), and other types of features of the query, result, user, or device used
Each of the raw features collected from the different devices is anonymous. Thus, discovering a raw feature for the device will not discover personal data stored on that device or contribute to that raw feature.
Those raw features can be collected, such as daily, weekly, or another time. Besides, the raw features can be collected, e.g., as the raw features are generated. Finally, the raw features are gathered if the searcher collects this data, such as an opt-in for collecting diagnostic data.
Selective subsets of the raw features are collected instead of having all the possible raw features collected at every instance. For example, the raw features could be collected at one time as a selected set of results from an engaged result set, and the raw features collected at a different time could be a set of abandoned results.
Other types of information collected for the raw features can be how a searcher interacts with applications installed on the device. For example, data could be collected on the frequency of times a searcher interacted with the contacts or mail application. Again, the data collected so that the private data of the searcher of this device is not discovered.
The on-device sensitive data is private data collected about how the searcher uses the device. Still, this data remains resident on the device and is not sent to a server for collection.
The on-device data can include a user’s browser history, application states that include private data, and/or other types of private data.
The rerank model module generates the local intra-domain and inter-domain models from the on-device sensitive data with the crowd-sourced intra-domain and crowd-sourced inter-domain models.
The model then generates the inter-domain model from the crowd-sourced inter-domain model and the on-device sensitive data. The reranking module uses the intra-domain and inter-domain models to rerank search results from the on-device search domains and/or off-device search domains.
The rerank model can include a policy model that includes a set of policy rules to rerank these results. The client receives the crowd-sourced intra-domain model and inter-domain model if the client opts in to receive these models. The client can opt-in by agreeing to allow the collection of diagnostic data or other opting.
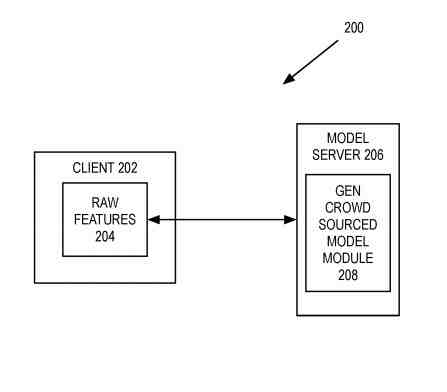
A system that receives raw features of a client and uses the raw features to generate crowd-sourced models
The client works with a model server. The client and model servers are the client and model server. The client includes raw features. The raw features are data that gives indications on how a searcher interacts with the client. The raw features can be from a periodic schedule or a dynamic schedule.
The model server includes a generate crowd-sourced model module that collects the raw features from the client and uses these raw features from this client and/or other devices to generate the crowd-sourced domain models. The generated crowd-sourced model module can generate an intra-domain model from the collected raw features.
The raw features from the model server taken from the client or other devices into collected features. Then, the model server preprocesses the collected features into new collected features set. Finally, the model server preprocesses the collected features set, transforming features, dropping features, create new features, normalizing features, and/or other feature preprocessing.
The model server uses the collected features as input to train the machine learning algorithm used to generate the crowd-sourced intra-domain model. The machine-learning algorithm is a neural network. The model server uses the’ feature set as the lower layer in the neural network. Also, intermediate layers are a compacted representation and a final layer of neural network neurons.
The final layer can include two neurons representing a likely to be engaged and likely not to be the engaged result. Thus, there can be more numbers and types of results for the final layer of neurons for the crowd-sourced intra-domain model.
The server uses the collected features as input for the crowd-sourced inter-domain model. Besides, the model server uses the collected feature set as an input for the neural network, where there is a set of intermediate layers and a final layer neural network neuron.
The final layer can include four neurons representing different domain results (such as bad result, fair result, good result, and excellent result). There can be more numbers and types of results for the final layer of neurons for the crowd-sourced inter-domain model.
The Client Can Use Several Different Crowd-Sourced Intra-Domain Models
First, there can be a crowd-sourced intra-domain model for each of the on-device-supported search domains.
Second, there can be a common crowd-sourced intra-domain model for search domains and different crowd-sourced intra-domain models for other search domains.
Third, there could be a common crowd-sourced intra-domain model for all the supported search domains.
Fourth, there can be a common crowd-sourced inter-domain model for the supported search domains.
Finally, there can be more than one crowd-sourced inter-domain model for the supported search domains.
There can be different intra-domain and intra-domain models based on geography and locale. With the generated inter-domain and/or intra-domain models, the model server can send these models to the client.
There Can Be Gradient Boosting Decision Tree (GBDT) Models For Both L2 and L3.
The model server can use a pairwise training aim during training to lessen accuracy errors.
Both L2 and L3 can be generated only using data that users sent via the (anonymous and without sharing the actual query) diagnostic data channel, without using any data from the generic feedback that contains the searcher query. Instead, the model server sends the server results from metadata with local result metadata in the anonymous feedback.
The model server can create artificial (fake) data to train and generate another model. This can boost certain types of results higher than other results.
For example, an application or mail result that is more recently used or sent could get a higher ranker even though it does not match text features compared to other results. Likewise, a mail sent by certain people designated as VIP can be higher than other emails with the same recency or text matching characteristics.
The boosting also work in combination. So, for example, a mail sent by a VIP that is also more recent will be ranked higher than a mail sent by a VIP but is less recent, assuming both have the same quality of match otherwise (text matching, etc.).
One way to use the boosting model is to combine the score from the first model (the one trained using organic data) and the second model (trained using fake data) in a function that combines the scores to yield the final score for ranking the results.
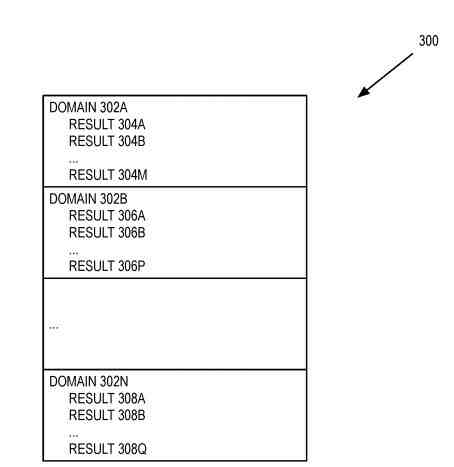
A Set of Search Results For a Search Query From Multiple Search Domains
Search domains group the search results. Each of the search domains can include zero or more results. For example, the search domain includes results where N, M, P, Q can be the same or different values.
The client can use the intra-domain model to rerank search results in one or more search domains. The client can use the intra-domain model to rerank the result ahead of the result. The client can use the inter-domain model to rerank the search domains. For example, by using the inter-domain model, the client may rank search results from the contact search domain ahead of search results from the news search domain.
Thus, using the inter-domain model, the client may rank domain (and corresponding results) ahead of the domain (and corresponding results). Then, the client can present the search results using these adjusted rankings (e.g., in a browser or another application that can perform a search).
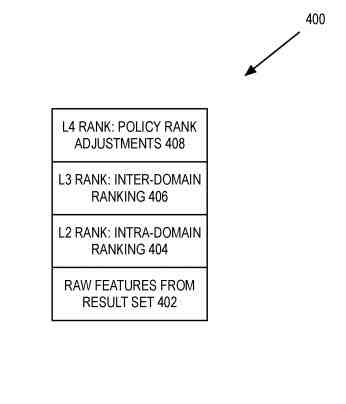
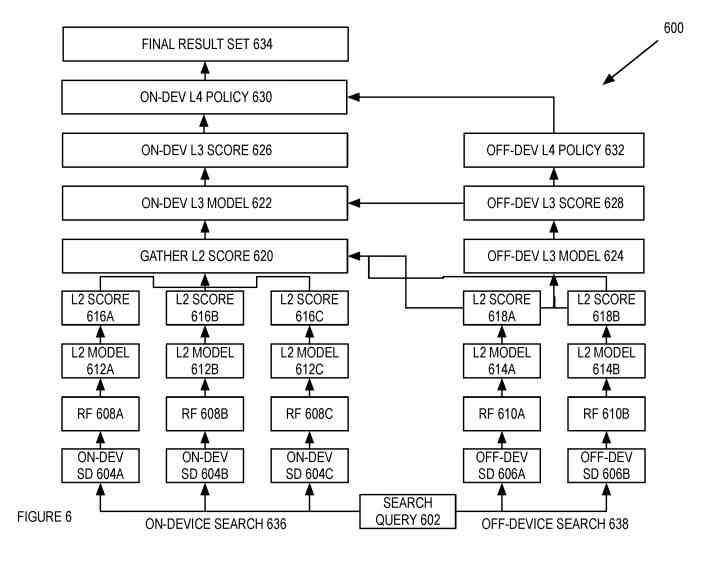
A Set of Layers Used to Rank the Set of Search Results
The set of layers can initially rank and rerank search results from on-device and/or off-device search domains.
The first layer is the raw features derived from the result set, the search query, and the device or context used in submitting the search query.
The raw features can be from the result set (such as a result score, cosine similarity and/or other types of query features, user-result features (such as whether the searcher has engaged the result, abandoned the result, the distance of searcher from the result (whether the result is a representation of an object in the world), or other types of result set features).
These features can be query features (such as many query terms or other types of query features).
Finally, the features can come from the device or context used in submitting the search query (such as how a searcher interacts with installed applications on the device like contacts, calendar, email, music, or other installed applications). For example, the layer above, L2, is a ranking of results using the client’s or server’s intra-domain models. The L2 rank results from the client using the intra-domain model to rerank the results for a particular domain.
In one embodiment, the L3 rank reranks domains using the inter-domain model.
A further ranking may be applied based on policy. This can be the L4 rank which uses policy to adjust the ranking of the domains and/or individual results. The L4 rank is a layer of policies to filter or threshold results based on the L3 score or regroup results based on searcher interface requirements.
The L4 rank policies can be different for the server-side rank in the client-side rank. For example, the L4 rank policies can be constraints on reordering server results, constraints on inserting results between server results, or advisory on placement.
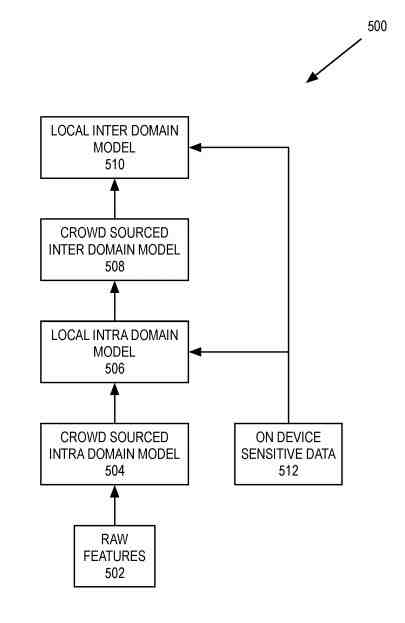
Local Domain Models Made from Crowd-Sourced Domain Models and On-Device Sensitive Data
The system uses raw features from the client or other devices used to create the crowd-sourced intra-domain model. But, the client may have recently booted up and has not shared raw features but can receive the crowd-sourced domain model(s) from a model server.
The searcher of a client may not have opted in but still can receive the crowd-sourced intra-domain model to rerank for the search result. The local intra-domain model is from the crowd-sourced intra-domain model and the on-device sensitive data. This model is a linear combination of the crowd-sourced intra-domain model and the on-device sensitive data.
The crowd-sourced intra-domain model and local intra-domain model is a neural network model or some other type of machine learning model.
The client receives a crowd-sourced inter-domain model generated from the collected raw features. The client generates a local inter-domain model from both the crowd-sourced inter-domain model and the on-device sensitive data.
The local inter-domain model is a linear combination of the crowd-sourced inter-domain model and the on-device sensitive data.
Local Domain Models Made from Crowd-Sourced Domain Models and On-Device Sensitive Data
The system uses raw features from the client or other devices used to create the crowd-sourced intra-domain model. But, the client may have recently booted up and has not shared raw features but can receive the crowd-sourced domain model(s) from a model server.
The searcher of a client may not have opted in but still can receive the crowd-sourced intra-domain model to rerank search results. The local intra-domain model is from the crowd-sourced intra-domain model and the on-device sensitive data. This model is a linear combination of the crowd-sourced intra-domain model and the on-device sensitive data.
The crowd-sourced intra-domain model and local intra-domain model is a neural network model or some other type of machine learning model.
The client receives a crowd-sourced inter-domain model generated from the collected raw features. The client generates a local inter-domain model from both the crowd-sourced inter-domain model and the on-device sensitive data.
The local inter-domain model is a linear combination of the crowd-sourced inter-domain model and the on-device sensitive data.
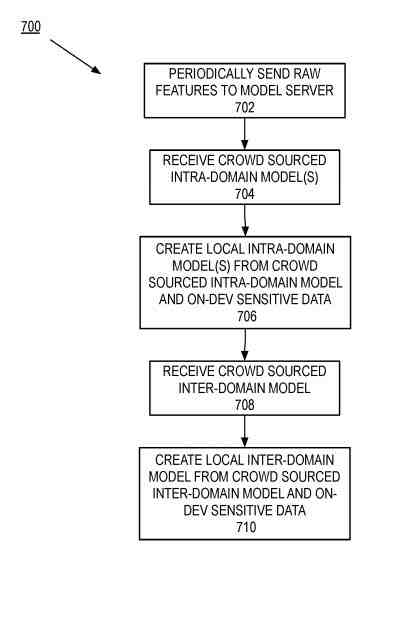
A Process to Generate Intra- and Inter-Domain Models
The process begins by sending raw features to the model server.
The raw features state an interaction between the searcher and the client device that collects the raw features.
The process receives the crowd-sourced intra-domain model(s).
The crowd-sourced intra-domain model(s) is the machine learning model generated by a model server using collected raw features from the client and/or other devices. The process creates the local intra-domain model(s) from the crowd-sourced intra-domain model(s) and on-device sensitive features.
The process creates the local intra-domain model(s).
The process receives the crowd-sourced inter-domain model. The crowd-sourced inter-domain model is the machine-learning model generated by the model server using the collected raw features from the client and other devices.
Next, the process creates the local inter-domain model from the crowd-sourced inter-domain model and the on-device sensitive data.
Finally, the process creates the local inter-domain model.
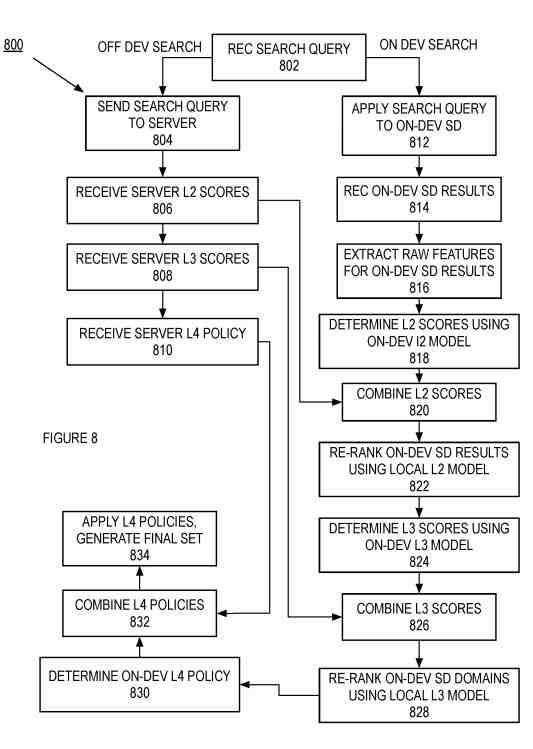
A Process to Rerank Search Results Using Intra- and Inter-Domain Models
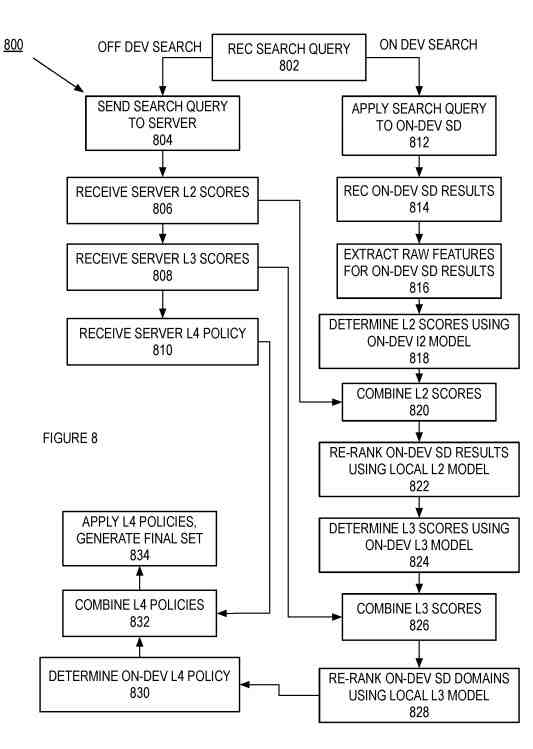
The process receives the search query.
It can perform an on-device search with the search query, off-device search with the search query, or both searches using the same search query.
If the process performs an off-device search, it sends the search query to the server to perform the off-device search.
The L2 Scores for the Results of the Off-Device Search
First, the process receives the server L2 scores for the results of the off-device search using the search query.
Next, the L2 scores for the off-device search results are from a server-based intra-domain model generated from a set of raw features collected from many devices.
Finally, the process forwards the server L2 scores—execution proceeds for the off-device search.
Next, the process receives the server L3 scores.
The L3 scores for the off-device search results or scores generated using a server-based inter-domain model. The process forwards the server L3 scores—execution proceeds for the off-device search. Finally, the process receives the server L4 policy and forwards these policies.
The process applies the search query to the on-device search domains if the process performs an on-device search.
First, the process applies to search grades to the on-device search domains.
Then, the process receives the on-device search domain results.
Finally, the process extracts the raw features for the on-device search domain results.
The process generates the L2 scores for the on-device search domain results.
First, the process generates the L2 scores.
Next, the process combines the L2 scores from the on-device search and the off-device search.
Finally, the process reranks the on-device search domain results using the local L2 model.
The process determines the L3 scores using the on-device L3 model.
Next, the process determines the L3 score.
Then, the process combines the L3 scores from the on-device search and the off-device search.
Finally, the process reranks the on-device search domains using the local L3 model.
The process determines the on-device L4 policy.
First, the process determines the on-device layer for policy.
Then, the process combines the L4 policies from the on-device and off-device L4 policies. Next, the process applies the letter for policies and generates the final set of search results. Finally, the process presents the final set of search results to the user.
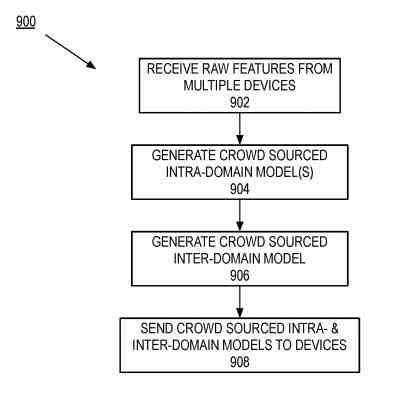
A Process to Generate the Crowd-Sourced Intra- and Inter-Domain Models
The process begins by receiving the raw features from many devices. The raw features received are data that indicate that.
Next, the process generates the crowd-sourced intra-domain model(s). The crowd-sourced intra-domain model can rerank search results within a search domain, such as the crowd-sourced intra-domain model.
Next, the process generates the crowd-sourced inter-domain model(s). The crowd-sourced inter-domain model is a model that can rerank search domains.
Finally, the process sends the crowd-sourced intra- and inter-domain models to the devices.
A rerank model module generates intra- and inter-domain models. The module to rerank search results include:
- Send raw features module
- Receive intra-domain models
- Create local intra-domain model module
- Receive inter-domain model module
- Create local inter-domain model module
The send raw features module, since the raw features from the device.
The receive intra-domain models received the crowd-sourced intra-domain model(s).
The create local intra-domain model module creates the local intra-domain model.
The receive inter-domain model module receives the inter-domain model.
The create local inter-domain model module creates the local inter-domain model.
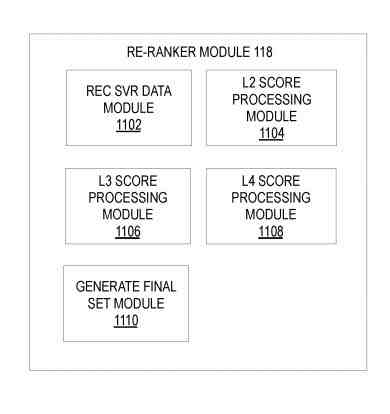
A Reranker Module That Generates Reranked Search Results Using Intra- and Inter-Domain Models
This part of the patent is a broad overview of the reranking search results process.
The reranker module includes:
- Receive server data module
- L2 score processing module
- L3 score processing module
- L4 score processing module
- Generate the final set module
The receive server data module receives the server search data.
The L2 score processing module extracts the raw features and determines the L2 scores.
The L3 score processing module processes the search results using the L3 model.
The L4 score processing module processes the search results using the L4 policy.
The generate final set module generates the final set of search results using the L4 policies.
We don’t have a lot of details about search at Apple, but it is looking like they are getting more sophisticated about how they are using it. We will see what develops there.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: