





Query Categorization Based On Image Results
Published: April 27, 2022
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

Google was recently granted a patent on Query Categorization Based On Image Results.
The patent tells us that: “internet search engines provide information about Internet-accessible resources (such as Web pages, images, text documents, multimedia content) responsive to a user’s search query by returning, when image searching, a set of image search results in response to the query.”
A search result includes, for example, a Uniform Resource Locator (URL) of an image or a document containing the image and a snippet of information.
Related Content:
- Technical SEO Agency
- Ecommerce SEO Agency
- Shopify SEO Services
- Franchise SEO Agency
- Enterprise SEO Services
Ranking SERPs Using a Scoring Function
The search results can be ranked (such as in order) according to scores assigned by a scoring function.
The scoring function ranks the search results according to various signals:
- Where (and how often) query text appears in document text surrounding an image
- An image caption or alternative text for the idea
- How standard the query terms are in the search results indexed by the search engine.
In general, the subject described in this patent is in a method that includes:
- Obtaining images from the first image results for a first query, where a number of the acquired images associated with scores and user behavior data that state user interaction with the obtained images when the obtained images are search results for the query
- Selecting a number of the acquired images each having respective behavior data that satisfies a threshold
- Associating the chosen first images with several annotations based on analysis of the selected images’ content
These can optionally include the following features.
The first query can be associated with categories based on the annotations. The query categorization and annotation associations can get stored for future use. The second image results responsive to a second query that is the same or like the first query can get received.
Each of the second images gets associated with a score, and the second image can get modified based on the categories related to the first query.
One of the query categorizations can state that the first query is a single-person query and increases the scores of the second image, whose annotations say that the set of second images contains a single face.
One query categorization can state that the first query is diverse and increase the scores of the second images, whose annotations say that the set of second images is diverse.
One of the categories can state that the first query is a text query and increase the scores of the second image, whose annotations say that the set of second images contains the text.
The first query can get provided to a trained classifier to determine a query categorization in the categories.
Analysis of the selected first images’ content can include clustering the first image results to determine an annotation in the annotations. User behavior data can be the number of times users select the image in search results for the first query.
The subject matter described in this patent can get implemented so on realize the following advantages:
The image result set gets analyzed to derive image annotations and a query categorization, and user interaction with image search results can get used to derive types for queries.
Query Categorization
Query categories can, in turn, improve the relevance, quality, and diversity of image search results.
Query categorization can also get used as part of query processing or in an off-line process.
Query categories can get used to provide automated query suggestions such as “show only images with faces” or “show only clip art.”
Query categorization based on image results
Inventors: Anna Majkowska and Cristian Tapus
Assignee: GOOGLE LLC
US Patent: 11,308,149
Granted: April 19, 2022
Filed: November 3, 2017
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for query categorization based on image results.
In one aspect, a method includes receiving images from image results responsive to a query, wherein each of the photos gets associated with an order in the image results and respective user behavior data for the image as a search result for the first query and associating of the first images with a plurality of annotations based on analysis of the selected first images’ content.
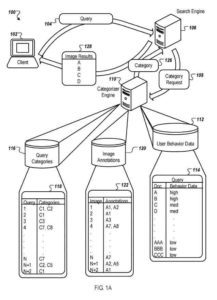
A System That Uses Query Categorization To Improve The Set Of Results Returned For A Query
A client, such as a web browser or other process executing on a computing device submits an input query to a search engine, and the search engine returns image search results to the client. In some implementations, a query comprises text such as characters in a character set (e.g., “red tomato”).
A query comprises images, sounds, videos, or combinations of these. Other query types are possible. The search engine will search for results based on alternate query versions equal to, broader than, or more specific than the input query.
The image search results are an ordered or ranked list of documents or links to such, which are determined to be responsive to the input query, with the documents determined to be most relevant having the highest rank. A copy is a web page, an image, or another electronic file.
In the case of image search, the search engine determines an image’s relevance based, at least in part, on the following:
- Image’s content
- The text surrounding the image
- Image caption
- Alternative text for the image
Categories Associated With A Query
In producing the image search results, the search engine in some implementations submits a request for categories associated with the query. The search engine can use the associated categories to re-order the image search results by increasing the rank of image results determined to belong to the related categories.
In some cases, it may decrease image results that do not belong to the associated categories or both.
The search engine can also use the categories of the results to determine how they should get ranked in the finalized set of results in combination with or of the query category.
A categorizer engine or other process employs image results retrieved for the query and a user behavior data repository to derive categories for the query. The repository contains user behavior data. The storage indicates the number of times populations of users selected an image result for a given query.
Image selection can be accomplished in various ways, including using the keyboard, a computer mouse or a finger gesture, a voice command, or other methods. User behavior data includes “click data.”
Click Data Indicates How Long A User Views Or “Dwells” On An Image Result
Click data indicates how long a user views or “dwells” on an image result after selecting it in a results list for the query. For example, a long time dwelling on an image (such as greater than 1 minute), termed a “long click,” can state that a user found the image relevant to the user’s query.
A brief period of viewing an image (e.g., less than 30 seconds), termed a “short click,” can get interpreted as a lack of image relevance. Other types of user behavior data are possible.
By way of illustration, user behavior data can get generated by a process that creates a record for result documents selected by users in response to a specific query. Each form can get represented as a tuple: <document, query, data>) that includes:
- A question submitted by users
- A query reference indicating the query
- A document reference a paper selected by users in response to the query
- Aggregation of click data (such as a count of each click type) for all users or a subset of all users that selected the document reference in response to the query.
Extensions of this tuple-based approach to user behavior data are possible. For instance, the user behavior data can get extended to include location-specific (such as country or state) or language-specific identifiers.
With such identifiers included, a country-specific tuple would consist of the country from where the user query originated, and a language-specific tuple would consist of the language of the user query.
For simplicity of presentation, the user behavior data associated with documents A-CCC for the query get depicted in the table as being either a “high,” “med,” or “low” amount of favorable user behavior data (such as user behavior data indicating relevance between the document and the query).
User Behavior Data For A Document
Favorable user behavior data for a document can state that the paper is selected by users when it gets viewed in the results for the query, or when a users view the document after choosing it from the results for the query, the users view the document for an extended period (such as the user finds the document to be relevant to the question).
The categorizer engine works in conjunction with the search engine using returned results and user behavior data to determine query categories and then re-rank the results before they get returned to the user.
In general, for the query (such as a query or an alternate form of the query) specified in the query category request, the categorizer engine analyzes image results for the query to determine if the query belongs to categories. Image results analyzed in some implementations have been selected by users as a search result for the query a total number of times above a threshold (such as set at least ten times).
The categorizer engine analyzes all image results retrieved by the search engine for a given query. in other implementations
The categorizer engine analyzes image results for the query where a metric (e.g., the total number of selections or another measure) for the click data is above a threshold.
The image results can be analyzed online using computer vision techniques in various ways, either offline or online, during the scoring process. Images get annotated with information extracted from their visual content.
Image Annotations
For example, image annotations can get stored in the annotation store. Each analyzed image (e.g., image 1, image 2, etc.) gets associated with annotations (e.g., A1, A2, and so on) in a photo to annotation association.
The annotations can include:
- The number of faces in the image
- The size of each face
- The dominant colors of the image
- Whether a picture contains text or a graph
- Whether an image is a screenshot
Additionally, each image can get annotated with a fingerprint which can then determine if two images are identical or identical.
Next, the categorizer engine analyzes image results for a given query and their annotations to determine query categories. Associations of query categories (e.g., C1, C2, and so on) for a given query (such as query 1, query 2, etc.) can be determined in many ways, such as using a simple heuristic or using an automated classifier.
A Simple Query Categorizer Based On A Heuristic
As an example, a simple query categorizer based on a heuristic can get used to determine the desired dominant color for the query (and whether there is one).
The heuristic can be, for example, that if out of the top 20 most often clicked images for the query, at least 70% have a dominant color red, then the query can get categorized as “red query.” For such queries, the search engine can re-order the retrieved results to increase the rank of all images annotated with red as a dominant color.
The same categorization can get used with all other standard colors. An advantage of this approach to over-analyzing the text of the query is that it works for all languages without the need for translation (such as it will promote images with dominant red color for the question “red apple” in any language). It is more robust (such as it will not increase the rank of red images for the query “red sea”).
An Example Categorizer Engine
The categorizer engine can work in an online mode or offline mode in which query category associations get stored ahead of time (e.g., in the table) for use by the search engine during query processing.
The engine receives query image results for a given query and provides the image results to image annotators. Each image annotator analyzes image results and extracts information about the visual content of the image, which gets stored as an image annotation (e.g., image annotations) for the idea.
A Face Image Annotator
By way of illustration, a face image annotator:
- Determines how many faces are in an image and the size of each face
- a fingerprint image annotator extracts visual image features in a condensed form (fingerprint) which then can get compared with the fingerprint of another image to determine if the two images are similar
- A screenshot image annotator determines if an image is a screenshot
- A text image annotator determines if a picture contains text
- A graph/chart image query determines if an image includes graphs or charts (e.g., bar graphs)
- A dominant color annotator determines if a picture contains a dominant color
Other image annotators can also get used. For example, several image annotators get described in a paper entitled “Rapid Object Detection Using a Boosted Cascade of Simple Features,” by Viola, P.; Jones, M., Mitsubishi Electric Research Laboratories, TR2004-043 (May 2004).

Next, the categorizer engine analyzes image results for a given query and their annotations to determine query categories (e.g., query categories). Query categories are determined using a classifier, and a query classifier can get realized using a machine learning system.
Use of Adaptive Boosting
By way of illustration, AdaBoost, short for Adaptive Boosting, is a machine learning system that can be used with other learning algorithms to improve their performance. AdaBoost gets used to generate a query categorization. (More learning algorithms are possible)
AdaBoost invokes a “weak” image annotator in a series of rounds. By way of illustration, the single-person query classifier can get based on a learning machine algorithm trained to determine whether a query calls for images of a single person.
By way of illustration, such a query classifier can get trained with data sets comprising a query, a set of feature vectors representing result images for the question with zero or more faces, and the correct categorization for the query (i.e., faces or not). For each call, the query classifier updates a distribution of weights that indicates the importance of examples in the training data set for the classification.
On each round, the weights of each classified training example get increased (or the consequences of each classified training example get decreased), so the new query categorization focuses more on those examples. The resulting trained query categorization can take as input a query and output a probability that the query calls for images containing single persons.
A diverse/homogeneous query classifier takes as input a query and outputs a probability that the query is for various images. The classifier uses a clustering algorithm to cluster image results according to their fingerprints based on a measure of distance from each other. Each image gets associated with a cluster identifier.
The image cluster identifier gets used to determine the number of clusters, the size of the groups, and the similarity between clusters formed by images in the result set. For example, this information gets used to associate a probability that the query is specific (or inviting duplicates) or not,
Associating Queries With Canonical Meanings And Representations
The query categorization can also get used to associate queries with canonical meanings and representations. For example, if there is a single large cluster or several large clusters, the probability of the question getting related to duplicate image results is high. If there are many smaller clusters, then the likelihood that the query gets associated with the same image results is low.
Duplicates of images are usually not very useful as they provide no more information, so they should get demoted as query results. But, there are exceptions. For example, if there are many duplicates in initial results (a few, large clusters), the query is particular, and duplicates should not get demoted.
A screenshot/non-screenshot query categorization takes as input a query and outputs a probability that the query calls for images that are screenshots. A text/non-text query classifier accepts as input a query and outputs a chance that the query calls for images that contain text.
A graph/non-graph query categorization takes an input of a query and outputs a probability that the query calls for images that contain a graph or a chart. A color query classifier 133f takes an information query and outputs a chance that the query calls shots that get dominated by a single color. Other query classifiers are possible.
Improving The Relevance Of Image Results Based On Query Categorization
A searcher can interact with the system through a client or other device. For example, the client device can be a computer terminal within a local area network (LAN) or a vast area network (WAN). The client device can be a mobile device (e.g., a mobile phone, a mobile computer, a personal desktop assistant, etc.) capable of communicating over a LAN, a WAN, or some other network (e.g., a cellular phone network).
The client device can include a random access memory (RAM) (or other memory and a storage device) and a processor.
The processor gets structured to process instructions and data within the system. The processor is a single-threaded or multi-threaded microprocessor having processing cores. The processor receives structured to execute instructions stored in the RAM (or other memory and a storage device included with the client device) to render graphical information for a user interface.
A searcher can connect to the search engine within a server system to submit an input query. The search engine is an image search engine or a generic search engine that can retrieve images and other types of content such as documents (e.g., HTML pages).
When the user submits the input query through an input device attached to a client device, a client-side question gets sent into a network and forwarded to the server system as a server-side query. The server system can be server devices in locations. A server device includes a memory device consisting of the search engine loaded therein.
A processor gets structured to process instructions within the device. These instructions can install components of the search engine. The processor can be single-threaded or multi-threaded and include many processing cores. The processor can process instructions stored in the memory related to the search engine and send information to the client device through the network to create a graphical presentation in the user interface of the client device (e.g., search results on a web page displayed in a web browser).
The server-side query gets received by the search engine. The search engine uses the information within the input query (such as query terms) to find relevant documents. The search engine can include an indexing engine that searches a corpus (e.g., web pages on the Internet) to index the documents found in that corpus. The index information for the corpus documents can be stored in an index database.
This index database can get accessed to identify documents related to the user. Note that an electronic copy (which will s get referred to as a document) does not correspond to a file. A record can get stored in a part of a file that holds other documents, in a single file dedicated to the document in question, or in many coordinated files. Moreover, a copy can get stored in a memory without being stored in a file.
The search engine can include a ranking engine to rank the documents related to the input query. The documents’ ranking can get performed using traditional techniques to determine an Information Retrieval (IR) score for indexed records given a given query.
Any appropriate method may determine the relevance of a particular document in a specific search term or to other provided information. For example, the general level of back-links to a document containing matches for a search term may get used to infer a document’s relevance.
In particular, if a document gets linked to (e.g., is the target of a hyperlink) by many other relevant documents (such as documents containing matches for the search terms), it can get inferred that the target document is particularly relevant. This inference can get made because the authors of the pointing papers presumably point, for the most part, to other documents that are relevant to their audience.
The pointing documents target links from other relevant documents, which can be considered more relevant. The first document is particularly appropriate because it targets applicable (or even highly relevant) documents.
Such a technique may determine a document’s relevance or one of many determinants. Appropriate methods can also get taken to identify and cut attempts to cast fraudulent votes to drive up the relevance of a page.
To further improve such traditional document ranking techniques, the ranking engine can receive more signals from a rank modifier engine to assist in determining an appropriate ranking for the documents.
In conjunction with image annotators and query categorization described above, the rank modifier engine provides relevance measures for the papers. The ranking engine can use to improve the search results’ ranking provided to the user.
The rank modifier engine can perform operations to generate the measures of relevance.
Whether an image result’s score increases or decreases depends on whether the image’s visual content (as represented in image annotations) matches the query categorization, each image category gets considered.
For example, if the query’s categorization is “single person,” then an image result that gets classified both as a “screenshot” and “single face” would first have its score decreased because of the “screenshot” category. It can then increase its score because of the “single face” category.
The search engine can forward the final, ranked result list within server-side search results through the network. Exiting the network, client-side search results can get received by the client device, where the results can get stored within the RAM and used by the processor to display the results on an output device for the user.
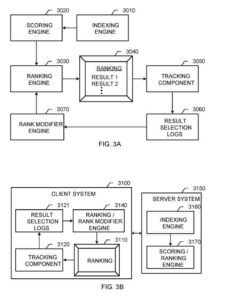
An Information Retrieval System
These components include an:
- Indexing engine
- Scoring engine
- Ranking engine
- Rank modifier engine
The indexing engine functions as described above for the indexing engine. The scoring engine generates scores for document results based on many features, including content-based features that link a query to document results and query-independent parts that generally state the quality of documents results.
Content-based features for images include aspects of the document that contains the picture, such as query matches to the document’s title or the image’s caption.
The query-independent features include, for example, aspects of document cross-referencing of the paper or the domain or image dimensions.
Moreover, the particular functions used by the scoring engine can get tuned to adjust the various feature contributions to the final IR score, using automatic or semi-automatic processes.
The ranking engine ranks document results for display to a user based on IR scores received from the scoring machine and signals from the rank modifier engine.
The rank modifier engine provides relevance measures for the documents, which the ranking engine can use to improve the search results’ ranking provided to the user. A tracking component records user behavior information, such as individual user selections of the results presented in the order.
The tracking component gets embedded JavaScript code included in a web page ranking that identifies user selections of individual document results and identifies when the user returns to the results page, thus indicating the amount of time the user spent viewing the selected document result.
The tracking component is a proxy system through which user selections of the document results get routed. The tracking component can also include pre-installed software for the client (such as a toolbar plug-in to the client’s operating system).
Other implementations are also possible, for example, one that uses a feature of a web browser that allows a tag/directive to get included in a page, which requests the browser to connect back to the server with messages about links clicked by the user.
The recorded information gets stored in result selection logs. The recorded information includes log entries that state user interaction with each result document presented for each query submitted.
For each user selection of a result document presented for a query, the log entries state the query (Q), the paper (D), the user’s dwell time (T) on the document, the language (L) employed by the user, and the country (C) where the user is likely located (e.g., based on the server used to access the IR system) and a region code (R) identifying the metropolitan area of the user.
The log entries also record negative information, such as that a document result gets presented to a user but was not selected.
Other information such as:
- Positions of clicks (i.e., user selections in the user interface
- Information about the session (such as existence and type of previous clicks (Post-click session activity))
- R scores of clicked results
- IR scores of all results shown before click
- Titles and snippets are displayed to the user before the click
- User’s cookie
- Cookie age
- IP (Internet Protocol) address
- User-agent of the browser
- So on
The time (T) between the initial click-through to the document result and the users returning to the main page and clicking on another document result (or submitting a new search query) also gets recorded.
An assessment gets made about the time (T) about whether this time indicates a longer view of the document or a shorter one since more extended arguments generally show quality or relevance for the clicked-through result. This time assessment (T) can be made in conjunction with various weighting techniques.
The components shown can be combined in various manners and multiple system configurations. The scoring end tanking engines merge into a single ranking engine, such as the ranking engine. The rank modifier engine and the ranking engine can also get merged. In general, a ranking engine includes any software component that generates a ranking of document results after a query. Moreover, a ranking engine can fit a client system also (or rather than) in a server system.
Another example is the information retrieval system. The server system includes an indexing engine and a scoring/ranking engine.
In this system, A client system includes:
- A user interface for presenting a ranking
- A tracking component
- Result selection logs
- A ranking/rank modifier engine.
For example, the client system can include a company’s enterprise network and personal computers, in which a browser plug-in incorporates the ranking/rank modifier engine.
When an employee in the company initiates a search on the server system, the scoring/ranking engine can return the search results. An initial ranking or the actual IR scores for the results. The browser plug-in then re-ranks the results based on tracked page selections for the company-specific user base.
A Technique For Query Categorization
This technique can be performed online (as part of query processing) or in an offline manner.
First image results responsive to the first query get received. Each of the first images gets associated with an order (such as an IR score) and a respective user behavior data (such as click data).
A number of the first images get selected where a metric for the respective behavior data for each selected image satisfies a threshold.
The selected first images get associated with several annotations based on the chosen first images’ content analysis. The image annotations can get persisted in image annotations.
Categories are then associated with the first query based on the annotations.
The query categorization associations can last in query categories.
Second image results responsive to a second query that is the same or the first query are then received.
(If the second query is not found in the query categorization, the second query can get transformed or “rewritten” to determine if an alternate form matches a query in the query categorization.)
In this example, the second query is the same as or can be rewritten as the first query.
The second image results are re-ordered based on the query categorization before being associated with the first query.