





Thematic Modeling Using Related Words in Documents and Anchor Text
Published: August 05, 2016
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

Entity Models and Thematic Models
I’ve been looking at using models that can help with how pages are indexed and understood by search engines.
This includes both entity models and thematic models.
For an entity model, we’ve looked at entities that appear on websites, in Knowledge Graphs, and in related entities, to see if we should write about those related entities.
For a thematic model, I looked at something Google has been calling Phrase-Based Indexing, and I noticed a patent from two years ago that I hadn’t written about, and liked it enough to share it.
An entity model was helpful to us when we worked on a website that was about an apartment building. The apartment itself could be called an entity because it is a unique business with some interesting features that were worth describing to people possibly interested in moving into it. Our thought was “location sells” and we wanted to test that out.
Related Content:
The location of the apartment was important because it was very close to Washington, DC, and right above the D.C. Metro line connecting Northern Virginia, Southern Maryland, and our nation’s capital. It was in a busy Northern Virginia town with a large underground shopping mall next to it, some nearby schools, and close to headquarters of large corporations and government agencies. If you worked at one of those places, the commute to the apartment complex would be a comfortable one.
Learning about the place and how those entities were related would give visitors to their web site some insights into what it would be like living there.
By including entity information on the site, we not only helped Search Engines understand the site better but also helped visitors who came to the site understand it better. It also provided us with a useful strategy for enriching the content found on the website. We also thought about Knowledge Panels for the site, and how Google presented the apartments in search results.
In addition to thinking about how an entity model might help us with a site like this one, we wanted to look closer at the words used on the site, and how those might be related to each other in meaningful ways. We needed a strategy to do that with, and it appears that we have found one.
Phrase-Based Indexing and Thematic Modeling
This is a screenshot from the phrase-based indexing patent that points out some good phrases that help the search engine understand the content on the Website better:

Google’s Phrase-Based Indexing has been in development since 2004. It focuses upon indexing, searching, and classifying documents specifically in a system such as the Internet. It was brought to Google by Anna Patterson and has been shown off in a series of patents that describe different aspects of it. One of the most recent related patents, granted in 2014 is worth looking at more closely because it provides details on how the use of related words; certain terms and phrases on pages and in anchor text can help a search engine understand what pages are about, and rerank those pages.
The patent discusses how search engines function and work in helping people find information on the Internet:
Information retrieval systems, generally called search engines, are now an essential tool for finding information in large scale, diverse, and growing corpuses such as the Internet. Generally, search engines create an index that relates documents (or “pages”) to the individual words present in each document. A document is retrieved in response to a query containing several query terms, typically based on having some number of query terms present in the document. The retrieved documents are then ranked according to other statistical measures, such as frequency of occurrence of the query terms, host domain, link analysis, and the like. The retrieved documents are then presented to the user, typically in their ranked order, and without any further grouping or imposed hierarchy. In some cases, a selected portion of a text of a document is presented to provide the user with a glimpse of the document’s content.
I’ve written about phrase-based indexing before. Regardless of whether Google is using phrase-based indexing or not, the ideas behind it on topic modeling can help when creating content to use to create relevant and meaningful content for web pages.
I thought enough of the phrase-based indexing patents to make my last post about the part of a series, titled 10 Most Important SEO Patents, Part 5 – Phrase-Based Indexing. I considered these patents to be some of the most important ones from Google, even though we haven’t received any signs that Google is using the processes behind the patents.
To provide another look, it might be helpful for you to read another person’s post on phrase-based indexing, and I found this one from Justin Briggs to be very readable – Phrase Based Indexing and Semantics. Justin includes the idea of a “co-occurrence matrix” into the discussion and Google has made that the focus of another patent, worth looking at because it can help explain how co-occurrence can help describe how phrase-based indexing can help someone building a thematic model.
A Co-Ocurrence Matrix
I wrote about Google’s co-occurrence matrix patent in Ranking Webpages Based Upon Relationships Between Words (Google’s Co-Occurrence Patent). The co-occurrence patent is similar to the phrase-based indexing patents in that both try to look at important phrases that tend to co-occur on documents that rank for specific terms (the co-occurrence matrix process is slightly different from phrase-based indexing and has some additional steps to it, but many similar ones.)
A page that might rank highly for “baseball stadium” might have related terms such as these show up on that page: Playing surface, Pitcher’s Mound, Outfield, Home Plate. If these terms appear frequently on the top 10 or top 100 ranking pages for “baseball stadium”, that could be an indication that they cover the same or very similar themes.
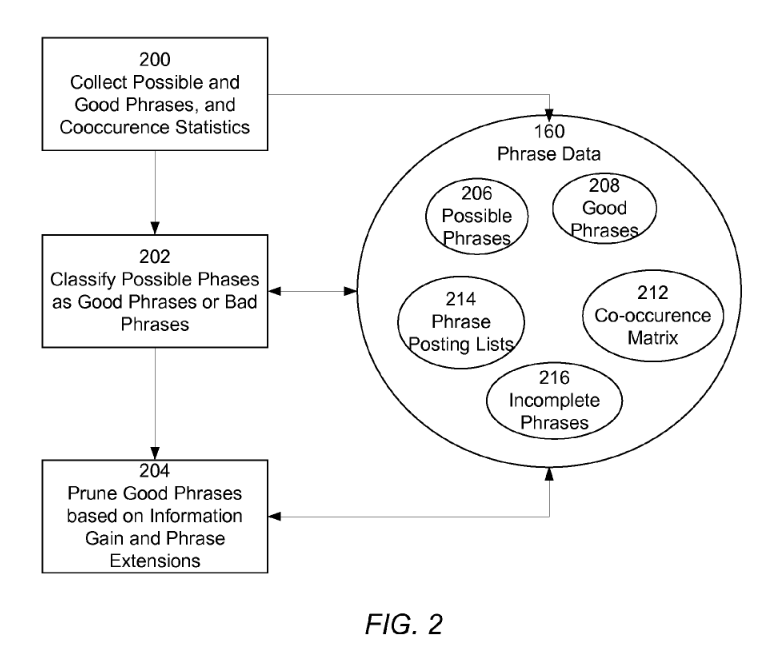
If a search engine indexes meaningful phrases like these (and the second generation of patents about phrase-based indexing tells us about how they might), then that search engine might be looking for clues that pages that cover the same topics.
If related phrases like those are used as anchor text pointed to pages about “baseball stadiums,” that tells us that the pages being targeted by that anchor text cover the same theme as well.
This patent looks for phrases that tend to show up on high ranking pages for certain terms… Those phrases are described as having “sufficiently frequent and/or distinguished usage in the document collection to indicate that they are “valid” or “good” phrases.”
Phrases looked for on these high ranking pages are ones that are said to be “related to each other.” For example, phrases such as “white house” and “President of the United States” tend to co-occur on the same pages, and they tend to cover the same concept or topic. So, if you see “white house” on a page, there’s a chance you may see “President of the United States.” on the same page.
Those phrases are related to each other and can be said to predict each other’s presence.
When Google builds an index of words that appear upon pages of the Web, it stores them in something that is referred to as a “posting list”.
In addition to an index that stores information about single words that show up on pages on the web, Google also could collect a second-tier index that contains a posting list that includes related phrases that point to query phrases. A page about the query “President of the United States” might have a related phrase on it of “white house”. If it does, that page is likely more about the concept or topic of “President of the United States.” than pages that don’t mention “white house.” These related phrases might also appear in Anchor text pointed to a page that ranks for a certain query phrase. If the anchor text is a phrase that is a related phrase to the query phrase that the page ranks for, that anchor text may also indicate that the page is about that topic or concept, and its existence as anchor text pointed to the page may lead to the page ranking higher for that query phrase.
The patent tells us that this phrase-based indexing can be used to “determine a list of top phrases for each website, such as the most representative phrases for the website.”
This patent is:
Integrated external related phrase information into a phrase-based indexing information retrieval system
Inventor: Anna L. Patterson
Assigned to: Google
United States Patent 8,631,027
Patterson January 14, 2014
Filed: January 10, 2012
Abstract
An information retrieval system uses phrases to index, retrieve, organize and describe documents, analyzing documents, and storing the results of the analysis as phrase data. Phrases are identified that predict the presence of other phrases in documents. Documents are indexed according to their included phrases. Related phrases and phrase extensions are also identified. Changes to existing phrase data about a document collection submitted by a user are captured and analyzed, and the existing phrase data is updated to reflect the additional knowledge gained through the analysis.
More Details from the Patent about Phrases
Good phrases predict other related phrases. “President of the United States” can predict phrases such as “George Bush” and “Bill Clinton.”
Bad phrases aren’t predictive. Phrases like “fell down the stairs” or “top of the morning,” or “out of the blue” is bad phrases since they don’t state concepts or topics that might predict the presence of other related phrases.
Phrases are found while web pages are crawled, and are identified often by being terminated by end of lines, paragraph returns, markup tags, or other indications of a change in content or format.
Related phrases are good phrases that end up in the co-occurrence matrix, and they can be added to that co-occurrence matrix based upon these three associated counts in a possible phrase list. These three counts include:
P(p): Number of documents on which the possible phrase appears;
S(p): Number of all instances of the possible phrase; and
M(p): Number of interesting instances of the possible phrase. – “Interesting” phrases are distinguished from other content by grammatical or format markers, such as by being in boldface, or in underline, or as anchor text in a hyperlink, or in quotation marks. Information about interesting phrases might be tracked when a phrase is placed in the good phrase list.
The patent describes other features that might be counted and viewed that distinguish phrases
Individual words might be considered phrases, as well as multi-word phrases
Incomplete phrases might be removed from a good phrase list, for example, “President of the” is incomplete, while “President of the United States” is a complete phrase – it stands for a specific concept as a complete phrase.
The patent explores how sometimes phrases may be clustered into different groups. For instance, the good phrase “Bill Clinton” is related to the phrases “President”, and “Monica Lewinsky”.
The phrase “Monica Lewinsky” may be related to the phrase “purse designer”. “Bill Clinton,” “President”, and “Monica Lewinsky” could be said to form one cluster, “Bill Clinton,” and “President” form a second cluster, and “Monica Lewinsky” and “purse designer” may form a third cluster, and “Monica Lewinsky”, “Bill Clinton,” and “purse designer” form the fourth cluster.
The related phrase “Bill Clinton” does not likely predict the phrase “purse designer”, but “Monica Lewinsky” predicts both of these phrases.
Ranking Documents
Documents that contain these related phrases under phrase-based indexing may be ranked higher. These are informally referred to as “body hits”
Documents that are linked to by these related phrases can also be ranked higher. These are informally referred to as “anchor hits.”
Both scores from body hits and anchor hits can be combined and influence the reranking of a page for a query phrase.
The patent provides more details and information about how the presence of related phrases might be used by Google to impact the rankings of pages. I intended this post as an introduction to the impact of related phrases in phrase-based indexing. It is worth spending time digging through the patent to learn more about how this process works. You should now have an idea of how a topic modeling approach based upon phrase-based indexing could have a positive impact upon rankings for your site.
Take Aways
Using an entity model when creating content for a web page can help you create richer content for that page that could be relevant to Google’s Knowledge Graph, and make what you write about entities on your site richer and possibly more interesting. Using a Topical model when creating content for a web page can mean exploring phrases that tend to co-occur on high ranking pages for specific query phrases that your pages may be targeting. Using those related co-occurring phrases on the pages you create and as anchor text to those pages could lead to richer and higher-ranking pages.