


How ChatGPT, Gemini, and Copilot Decide What to Cite
Published: May 01, 2026
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

The traditional search paradigm of “10 blue links” is rapidly evolving into an era of Answer Engine Optimization (AEO) and Generative Engine Optimization (GEO). Today, AI tools like ChatGPT, Google Gemini, and Microsoft Copilot synthesize information from across the web into conversational answers with inline citations rather than returning a simple ranked list of links. This represents a shift from classic search to generative search, where models retrieve, evaluate, and synthesize relevant content from multiple sources to form a single coherent answer.
But how exactly do these large language models (LLMs) decide which websites to read, trust, and ultimately link to? Under the hood, generative engines combine retrieval mechanisms with language understanding: they first fetch relevant documents from an index or retrieval database and then summarize or synthesize the information into an answer format optimized for clarity and relevance. This process — distinct from traditional ranking algorithms — gives rise to new optimization disciplines like AEO and GEO that focus explicitly on being included and cited by AI systems.
This post breaks down the hidden mechanics behind AI source selection. We’ve compiled the latest research, industry analysis, and high-value insights to explore the technical pipelines of major AI search engines and provide actionable strategies to ensure your content becomes a citable source in AI-mediated discovery.
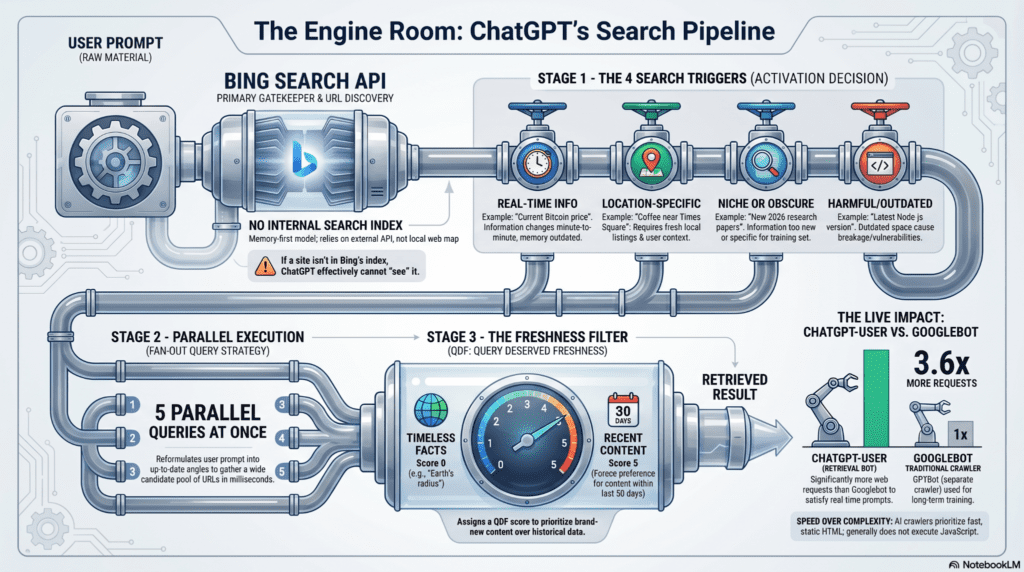
The Engine Room: ChatGPT’s Search Pipeline
Contrary to the belief that ChatGPT maintains its own independent search index, ChatGPT’s real-time web responses depend on external search infrastructure — primarily Microsoft Bing’s search index rather than an entirely separate proprietary index maintained by OpenAI. When users ask questions that require up-to-date or contextually specific information, the system queries Bing’s index to retrieve relevant content before synthesizing and citing it in its answers.
The core elements of this retrieval process include:
- Web index reliance: ChatGPT Search uses Microsoft Bing’s indexed content to supply current information for live web responses. If a page is not indexed by Bing, it is unlikely to be discovered and cited by ChatGPT.
- Retrieval-Augmented Generation (RAG) pipeline: The search pipeline combines Bing’s web-indexed results with the language model’s reasoning. First, the system issues queries to Bing, retrieves a set of top results, and then evaluates the content before generating a synthesized answer with citations.
- Bing index as discovery layer: Unlike traditional search engines that solely rely on their own indices, ChatGPT’s browse mode pulls real-time web content from the Bing index and processes it into conversational responses with inline source links. This means Bing’s index serves as the primary discovery layer for real-time content in ChatGPT Search.
- Impact on visibility: Because Bing is the foundational index for ChatGPT’s web search feature, content must be discoverable in Bing’s index to be included in these real-time responses — a constraint that reshapes how brands and publishers think about visibility in AI-mediated discovery.
The Secret Google Fallback: Does ChatGPT Only Use Bing?
Although OpenAI officially integrates Bing for ChatGPT’s web search capability, independent experiments suggest that Google’s search index can influence ChatGPT Plus responses under certain circumstances. In a controlled experiment, SEO researchers created a page containing a completely novel term — NexorbalOptimization — that existed nowhere else online and was made crawlable only by Googlebot. When asked about this term with web browsing enabled, ChatGPT Plus produced an accurate summary of the page, despite Bing never having indexed the content. This outcome indicates that Google’s index can be accessed in some form during ChatGPT’s response generation.
Additional analyses from Semrush corroborate this behavior, noting that ChatGPT does not rely exclusively on Bing for information retrieval but sometimes accesses Google-indexed content — particularly when that content is uniquely available via Google Search and not present in Bing’s index.
These findings show that Google Search visibility remains important for AI discovery, especially for unique or new content that may not yet be reflected in other search engines. Brands that are only visible to Bing may miss out when advanced AI models draw on Google’s broader index for certain queries.
The Ranking Algorithm: How ChatGPT Filters and Reranks Content
Unlike traditional SEO, which relies heavily on domain authority and backlinks to rank entire web pages, AI search and generative engines use fundamentally different mechanisms to determine which content gets cited in responses. Instead of classic link-based ranking, systems like ChatGPT Search use retrieval-augmented generation (RAG) pipelines that retrieve candidate documents and then reorder and evaluate them based on relevance, semantic meaning, and consistency across multiple query variations.
Passage-Level Relevance and RAG Pipelines
Rather than ranking pages through a static index like a traditional search engine, ChatGPT’s search-assisted responses first retrieve relevant documents and then analyze their contents for how well they match the user’s natural language intent. This is achieved through a Retrieval-Augmented Generation (RAG) pipeline, where retrieval and re-ranking filters (such as vector similarity and semantic scoring) determine which parts of content are considered for inclusion.
While some third-party sources describe this process in terms that sound like passage-level ranking, focusing on text segments that best answer the query — what’s consistently documented is that AI retrieval pipelines evaluate content by relevance to query intent and semantic context rather than purely by whole-page authority signals like backlinks or PageRank.
Reciprocal Rank Fusion (Consensus Across Variations)
Another way AI systems merge retrieval results is to combine multiple ranked lists from different retrieval strategies. Techniques such as Reciprocal Rank Fusion (RRF) — used in information retrieval research — reward documents that appear consistently across different search variations or retrieval methods by giving them a stronger collective score. This means that pages appearing moderately well across several query formulations can outperform those that rank highly in only one.
RRF works by adding up the reciprocal ranks a document obtains across multiple retrieval lists to form a composite score. Documents that repeatedly show up in diverse variations of a query thus rise in prominence when the AI constructs its internal context for generation.
Why This Matters for AI Visibility
Because generative engines prioritize semantic relevance, multiple query coverage, and consistency across retrieval methods, content that scores well through traditional SEO alone may still fail to appear in AI recommendations if it doesn’t align semantically with the query or appear across enough retrieval pathways. In contrast, content optimized for depth, clarity, and topic coverage — including structured data and clear answers — is more likely to be selected as a cited source.
How Google Gemini Grounds Answers with Real-Time Data
Google Gemini uses advanced grounding mechanisms to anchor its responses in real-world, verifiable information rather than relying solely on static training data. Instead of memorizing facts from its pre-training, Gemini can actively invoke tools like Google Search and Google Maps to fetch current, factual data that directly supports user queries. This shift toward retrieval-based accountability is central to how modern AI models ensure accuracy and relevance.
What Grounding Means in Gemini
Grounding refers to the process of connecting a model’s output to external, real-time information sources before generating a final answer. For Gemini, this typically involves:
- Google Search grounding: The model issues live search queries to Google’s index to pull up-to-date content and then incorporates those results into its response. This reduces reliance on outdated training data and enhances factual accuracy.
- Google Maps grounding: When a user’s query includes location context (such as “best cafés near me”), Gemini can leverage Google Maps data to provide accurate, geo-aware recommendations with up-to-date place details like addresses, reviews, and operating hours.
These grounding tools allow Gemini to tie its generated text directly to real sources and datasets, making the answers more reliable and useful for tasks like product search guidance, local discovery, and timely information retrieval.
Why Grounded Answers Matter
Grounded responses help solve two major challenges in AI discovery and recommendation:
- Accuracy over memorized training data: Without grounding, models may generate plausible-sounding but incorrect answers based only on patterns learned during training. Connecting responses to live search data or structured location data significantly reduces such hallucinations and increases trustworthiness.
- Up-to-date relevance for time-sensitive queries: Grounding with current web information ensures that responses reflect recent events, evolving product details, and the latest user opinions or reviews.
For example, developers can enable Google Search grounding when querying Gemini via its API, allowing the model to dynamically determine when external search results will improve response quality and include citation metadata showing the sources used.
How Grounding Works in Practice
When grounding is enabled, Gemini performs the following steps behind the scenes:
- A user prompt triggers analysis to determine whether grounding should be applied.
- The model issues one or more live search requests (e.g., through Google Search or Maps) to fetch relevant documents.
- Retrieved snippets are incorporated into the generation process, and grounding metadata is produced to indicate sources.
- The final response blends generated content with grounded facts and, where supported, clickable citations or structured data.
This approach ensures that the final answer is not only coherent and contextually relevant, but also anchored to real, verifiable information — a crucial dimension of AI visibility for retail brands whose products and specifications change frequently.
Microsoft Copilot’s Citation Checks
Microsoft Copilot uses Bing’s search index and AI synthesis to generate conversational answers, and citations play a central role in how those answers source information. Unlike traditional search results where links are organized by ranking, Copilot’s responses often include clickable references or aggregated source listings that show where the information came from, improving transparency and credibility for users.
How Copilot Displays Citations
In recent updates, Microsoft has made citations more prominent in Copilot responses. When Copilot produces an answer, it may display a “show all sources” panel or direct links to the web pages it used to craft the response, making it easier for users to trace information back to the original content.
This citation approach is part of Microsoft’s effort to build trustworthy AI experiences by clearly showing what external sources were referenced, helping users understand the provenance of the information Copilot uses to answer queries.
Patterns in Copilot’s Citation Selection
Copilot’s source selection process is influenced by multiple visibility and content quality signals rather than just traditional SEO ranking factors:
Dependence on Bing’s Index
Copilot draws candidate content from Bing’s live search index, meaning that pages well indexed and ranked in Bing are eligible to be cited in Copilot responses. Optimizing for Bing visibility remains foundational for earning citations.
Authority, Relevance, and Structure
Copilot tends to cite sources that demonstrate authority, topical relevance, and clear content structure. Pages with clean formatting, FAQ or article schema, and direct answers to likely user questions are more easily parsed and selected as citation sources.
Citation Diversity Across Sources
While some AI systems may over-rely on a few dominant domains, Copilot’s citation logic appears designed to balance authority with diversity. Sources such as business publications, expert reviews, and high-trust domains can all be cited when they meet relevancy and clarity criteria.
What This Means for AI Visibility
For brands and content creators, Copilot citations represent a new frontier in discoverability beyond traditional links. Being cited by Copilot means your content is not only indexed but also judged by AI relevance and structured clarity signals. Copilot citations can surface across Microsoft 365, Edge, and Bing Chat interfaces, offering exposure at decision-making touchpoints across the Microsoft ecosystem.
Optimizing for Copilot involves ensuring content is well-structured, aligned to user intent, and discoverable via Bing — a core part of Generative Engine Optimization (GEO) for Microsoft’s AI-first discovery platforms.
AI Citation Bias: Misaligned with Human Preferences?
AI models do not always choose citations in the same way humans expect. Research shows that large language models (LLMs) systematically differ from human citation behavior, meaning the snippets they decide to cite in generated answers may not align with what humans typically consider worthy of citation — especially for data-rich or identifiable content where human readers expect a reference.
A recent academic study on citation preferences in LLMs analyzed a dataset of 6,000 sentences categorized across eight citation motivation types and compared model citation behavior against human citation judgments. The findings reveal clear patterns of bias in how LLMs assign citations:
1. Under-selection of numerical information and personal names.
Models were significantly less likely than humans to add citations to sentences that contain numeric information or personal names — two categories where human readers strongly prefer references. Specifically, models under-selected:
- numeric sentences by about 22.6% relative to humans.
- sentences with personal names by about 20.1% relative to humans.
These are precisely the types of claims for which human citation expectations are highest.
2. Over-selection of text marked with “[Citation needed].”
Conversely, LLMs were found to add citations far more often than humans when the text was explicitly marked with “CitationneededCitation neededCitationneeded” — a pattern that inflated the alignment score for that category by up to 27% compared with human citation behavior. This suggests models pay disproportionate attention to textual cues from training data (such as Wikipedia edit markers) rather than actual informational necessity.
These biases highlight a persistent misalignment between machine-generated citation signals and human preferences, especially in contexts where factual verification matters. Brands and content teams should therefore be aware that even when AI systems cite sources, the absence or presence of a citation may not reflect true human expectations of verifiability. Instead, optimizing content for clarity, explicit claims, and structured fact statements can help reduce misalignment by making it clearer when a model should add a reference.
The Privacy Cost of AI Search: Data Leaks and “Shadow AI”
As companies rush to implement AI search, a critical risk has emerged: feeding proprietary data into these engines.
- The Redis Bug: A vulnerability in an open-source library allowed a bug to leak the chat histories and payment information (including credit card expiration dates) of 1.2% of active ChatGPT Plus subscribers during a 9-hour window in 2023.
- Agentic Exploits: As AI gets more autonomous, the attack surface grows. The “ShadowLeak” zero-click exploit recently demonstrated how attackers could use hidden HTML instructions in emails to manipulate ChatGPT’s Deep Research agent into exfiltrating private email data without the user ever clicking a link.
- Human Error: In January 2026, the acting director of the Cybersecurity and Infrastructure Security Agency (CISA) initiated an internal review after accidentally uploading sensitive, “For Official Use Only” government documents into the public version of ChatGPT.
Brands optimizing for AI must be hyper-aware that the very engines they are trying to rank on are continuously harvesting data—sometimes with unintended, highly public consequences.
The AEO Playbook: How to Get Cited in 2026
Optimizing for generative search engines requires an evolution beyond traditional SEO. Unlike classic search ranking — where high positions often lead to clicks — AI systems like ChatGPT and other large language models use internal relevance signals, structured data cues, and content readability to decide what to cite in answers. Because of this shift, brands need an Answer Engine Optimization (AEO) strategy that aligns with how AI evaluates content in 2026.
1. Don’t Rely Solely on Traditional Search Rankings
High search engine rankings alone do not guarantee that your content will be cited by AI. Research has found that Bing’s top-3 ranked URLs match actual ChatGPT citations only about 6.8% to 7.8% of the time, meaning that ranking at the top of traditional search engines—even Bing—does not reliably predict AI citation performance. This underscores the importance of optimizing for how AI models internally interpret and evaluate content, not just where your page sits in search engine result pages.
2. Implement Robust Schema Markup
Structured data like Product, FAQ, Article, and Organization schema helps AI systems parse your content with greater clarity. Schema markup turns unstructured text into machine-readable signals, making it easier for AI models to identify entities, features, pricing, and context, which increases the likelihood of citation and recommendation inside generative answers.
3. Strengthen Internal Linking and Canonical Signals
Internal links help AI crawlers understand topic authority and content context across your site. Pages with stronger internal link connectivity are more likely to be interpreted as relevant and complete when the model retrieves content. Likewise, clean canonical tags prevent duplication and help ensure that AI systems aggregate signals toward the preferred authoritative page, which supports more consistent citation eligibility.
4. Use Server-Side Rendering (SSR) or Pre-Rendering
Many AI crawling and indexing tools do not execute JavaScript, meaning content that loads dynamically via client-side scripts may never be seen by AI crawlers. Implementing server-side rendering (SSR) or pre-rendered HTML ensures that key content, structured data, and extractable information are visible in the raw HTML that AI engines ingest — improving AI discoverability and citation potential.
Generative Engine Optimization is fundamentally different from traditional SEO. It requires a laser focus on machine-readability, plain-text accessibility, and authoritative, structured formatting. As the data shows, relying on traditional ranking signals is no longer enough to guarantee visibility.
About Fiona Walker
As a Senior SEO Specialist at Go Fish Digital, Fiona Walker explores how search, storytelling, and strategy intersect. Her work pushes the boundaries of traditional SEO, transforming visibility into lasting brand impact through innovative lead gen and integrated marketing.