





Google Searching Quotes of Entities
Published: August 14, 2017
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url


Change is the law of life. And those who look only to the past or present are certain to miss the future. – John F. Kennedy
Searching Quotes at Google
There is a wide range of information that people search for on the Web, and I noticed a recently granted Google patent that focused upon finding and displaying quotes from famous people and celebrities and others about specific subjects. One of the interesting things about this patent was how it decided upon scores for quotes which determined how quote results would be displayed. Like most patents, this one points out potential problems with how present time (before the patent) results might be shown and problems with them. The patent provides the following example:
Such textual searches, however, often do not yield the results most desired by a user. For example, a search for the phrase “breaking bad” may return quotes like: “Most people don’t have that willingness to break bad habits. They have a lot of excuses and they talk like victims.” This quote, although real, does not relate to the popular television show “Breaking Bad.” A user searching for quotes related to the television show “Breaking Bad,” therefore, may receive quotes unrelated to the user’s query.
The patent uses an approach that pays attention to entities in a query. As we were told by Paul Haahr in his presentation from SMX last year, How Google Works, the search engine often looks for entities in queries as a first step in returning search results. This is the present of search. With a search for a quote, it seems like Google may try to find an entity that is being quoted and an entity that is the subject matter of a quote. The patent points this out immediately at the start of the description of how it works:
This disclosure presents computer-implemented systems and methods for searching for quotes of entities based on a user’s query. As part of the search, one or more subject entities associated with the query may be identified. The present disclosure also relates to systems and methods that employ a database to identify a set of quotes corresponding to a query or one or more identified subject entities. Still, further, systems and methods are provided for generating a rank order of the identified quotes, where the rank order is based on quote scores. Also, systems and methods are provided for transmitting information to display the selected quotes on a display device.
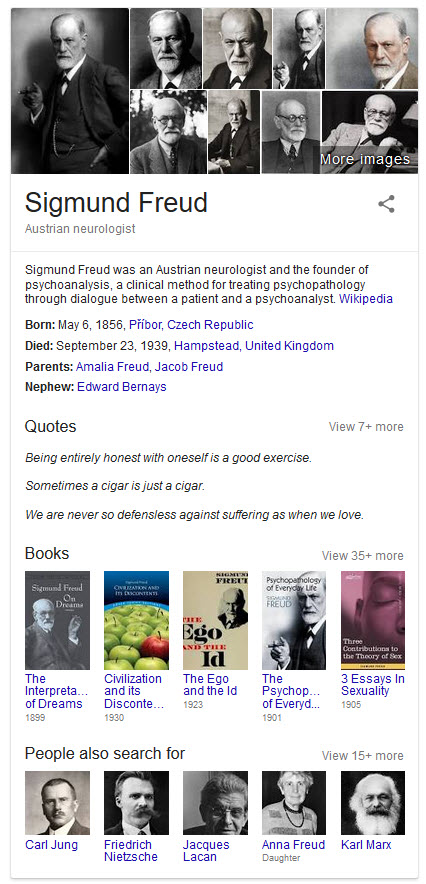
One of the things that caught my attention was how quotes were scored for ranking. I thought it was worth sharing. I also looked around to see if I could see examples of the use of quotes by Google, and noticed that in some knowledge panels, like this one from Sigmund Freud, there were several quotes, and an option to click on a link and see more quotes as well. So it seems like Google is not only interested in showing us information about entities, but also about things that they may have said in the past.
Related Content:
The patent granted last week at the USPTO is:
Systems and methods for searching quotes of entities using a database
Inventors: Eyal Segalis, Gal Chechik, Yossi Matias, Yaniv Leviathan, and Yoav Tzur
Assignee: GOOGLE
US Patent: 9,727,617
Granted: August 8, 2017
Filed: March 10, 2014
Abstract
Systems and methods are provided for searching and identifying quotes in response to a query from a user. Consistent with certain embodiments, systems and methods are provided for identifying one or more subject entities associated with the query and for identifying, from a database or search results obtained in response to the query, a set of quotes corresponding to the one or more subject entities. Further, systems and methods are provided for determining quote scores for the identified quotes based on at least one of the relationships of each quote to the one or more subject entities, the recency of each quote, and the popularity of each quote. Additionally, systems and methods are provided for organizing the identified quotes in a rank order based on the quote scores and selecting quotes based on the rank order or based on the quote scores. Also, systems and methods are provided for transmitting information to display the selected quotes on a display device.
A quotes database may be made up of content such as “quotes, authors of quotes, subject entities associated with the quotes, and/or a corpus of content items, etc.” These could be taken from, “documents, presentations, news items, articles, blog posts, books, book reviews, magazines, magazine articles, audio or video recordings, text messages, e-mail messages, social media content, or any other type of information item known in the art.”
Besides, the patent tells us that results may also include, “search logs containing search strings used by the user to search for content items and/or quotes.” I guess that would be helpful if someone is trying to refind something that they found before.
Identifying Quotes for Searching
One of the first processes described in the patent is one that focuses upon identifying and storing quotes and information associated with the quotes. We are told about quotes and how they may be found by a search engine indexing program.
First off, we are told about quotes:
A quote may include a single word, a phrase, a statement, and/or an inflected form, spoken, written or expressed in some form by an author or entity. By way of example, a single word, such as, “eureka,” “believe,” “dare,” or “action” may represent a quote. Further, by way of example, a sentence or phrase such as “the cautious seldom err,” or “hope is a waking dream” may represent a quote. Quotes may also include a paragraph or collection of sentences or phrases. An author may include a person, group, or an organization. By way of example, a person, such as, President Obama may be an author of a quote. Further by way of example, the United Nations, which is an organization, may be an author of a quote.
A quote may be associated with a particular URL or another identifier that may specify a “web page, a document, an image, or other resources.”
Identifying a quote may involve scrutinizing textual content in a content item, such as looking for the word “said” that could precede a quote, such as “President Obama said,” which might be followed by a phrase or a sentence that is in quotation marks.
The patent also tells us there that “the presence of quotation marks may be used to identify one or more quotes in the content item.”
In addition to quotation marks, other symbols may be used to identify quotes, for example, “quotes may appear in the content item as an author of the quote followed by a punctuation mark, such as, a colon, followed by the word, phrase or sentence that may be identified as a quote.”
The author of a book may be associated with a quote taken from a book. An audio statement may be associated with a speaker identified as making that statement.
Subject Entities and Quotes
In addition to identifying whom a quote is from, it can help to identify what a quote is about by determining a subject entity associated with a quote. This may be done by extracting some words from a quote, and seeing if those are what the quote is about, such as in the quote: “Education is the most powerful weapon which you can use to change the world,” words like “education” and “change,” may indicate the subject entities that may be associated with the quote.
Information Associated with Quotes
The search engine indexer may attempt to identify a date associated with a quote. That maybe when it was first spoken or written or expressed. It could be when it was first published or presented as news.
Validating Quotes
I’ve seen quotes attributed to the wrong person on the Web before, so it was good to see this mentioned in the patent.
The patent tells us that this process of identifying quotes may include a step of validating quotes and that quotes may be validated in more than one way:
- A quote may be validated by looking at if the exact quote appears in more than one content item in a corpus of content items.
- It is also considered valid if it “appears in more than one content item from different authors, publishers, web, and/or media outlets.”
- Another way to validate a quote is to see if, “the exact quote appears in a content item containing a transcript including the quote.”
- It could also be validated, “by confirming the accuracy of the quote with an author of the quote.”
Associated Information Related to a Quote
The context seems to matter a lot when it comes to most information.
The patent tells us that “associated information for a quote may include the author associated with the quote, one or more subject entities associated with the quote, and/or a date associated with the quote.”
Personalized Quote Information
This was interesting to see, too. It may be that someone’s search for quotation information may be shown personalized results, such as quotes made by the user or the user’s social media contacts. That seems like another way to show off Google+ information or Tweets.
How a Query for Searching Quotes Works
The patent provides three different examples of searching for quotes.
1. A query may identify both the author and subject entity associated with a quote, such as: “What did X say about Y?” with X as the author of the quote and Y as a subject entity associated with the quote. So, this would be similar to the query: “What did President Obama say about Nelson Mandela” with the author of the quotes, President Obama, talking about the subject entity, Nelson Mandela.
2. A query may identify just a subject entity in a requested quote, such as “Tesla Motors,” with Tesla Motors as the subject entity of a requested quote.
3. A query may include the word “quotes.” So, “Breaking Bad quotes” would be a request for quotes associated with “Breaking Bad.”
I’ve tried these and didn’t get results that showed off several quotes; seeming to indicate that this kind of quote search hasn’t yet be turned on at Google. I think it’s worth keeping an eye out for it to appear.
Subject Entities associated with Queries
The patent tells us about a step that identifies subject entities associated with a query. Subject entities may include, for example, an author, a person, a place, a topic, an item or thing, and/or an event, etc. associated with the query. For example, the query “Mandela quotes” may include the subject entity “Mandela,” who is a person.
The patent explains in more detail how subject entities could be found:
Subject entities may be identified from a query in many ways. By way of example, the structure of the query itself may be used to determine the subjects associated with the query. For example, a query of the type “what did X say about Y” may be parsed to identify the subjects X and Y separated by the words “say about.” In other embodiments, words or phrases may be extracted from the query. The extracted words or phrases may be compared to subject entities in a subject entity database to identify the subject associated with a query. For example, a query such as “Breaking Bad quotes” may provide the words “breaking,” “bad,” and the phrase “breaking bad.” These extracted words and/or phrases may be compared to words or phrases stored in the subject entity database.
More than One Subject in a Subject Entity Database
It’s not a surprise that some words or references to entities might have more than one meaning. The patent addresses this possibility, and tells us that, “When more than one subject entity in the subject entity database matches the extracted words and/or phrases, relevance scores associated with the subject entities may be used to select one or more subject entities.” The relevance score corresponding to each subject entity may be retrieved from the subject database.
The patent does tell us how relevance scores may be calculated to help determine the right subject entity. The relevance scores used in a query for a subject entity may be determined in several ways, as pointed to in the patents.
1. Relevance scores for a subject entity may be based on a popularity of a subject entity in a corpus of content items.
2. Relevance scores for a subject entity may be based on the popularity of the subject entity in search terms used by users when searching for information on the internet or web.
3. Relevance scores may be based on a popularity of a subject entity during a particular period.
4. The popularity of a subject entity may be determined based on a frequency of occurrence of the subject entity in (1) a corpus of content items, (2) in search terms used by users, (3) in web pages, etc.
The patent shows how these different ways of scoring relevance for a subject might be applied:
Tthe relevance scores for the subject entity “breaking bad” may be based on content items published between the time of release of the first episode of the television show “Breaking Bad” to one year after the release of the last episode. One or more subject entities corresponding to the highest relevance scores may be identified as subject entities corresponding to the query. By way of example, the relevance score of the subject entity “breaking bad” may be higher than the corresponding relevance scores of the words “breaking” and “bad” because the television show “Breaking Bad” may be very popular and the phrase “breaking bad” may occur very frequently in the corpus of content items or the search terms of users.
Filtering Quotes During Queries
There may be ways that a search can have the results they are shown filtered. The patent points a couple of those out for us:
1. Based upon topics, such as “television show.”
2. Based upon personalization, such as what social media contacts may have said about a topic.
Identifying Knowledge graph items associated with a subject entity
I wasn’t surprised to see a reference to knowledge graphs in this patent.
When Google looks at a query to see if it mentions or includes an entity, that can give it a lot more information to work with. As the patent tells us:
A knowledge graph item for a subject entity may include a corpus of information and content items associated with the subject entity. A corpus of information may include names, places, things, events, and/or content items. In some embodiments, the knowledge graph item may include links (for example, URLs) to the corpus of information. In other embodiments, the knowledge graph item may include references or links to other knowledge graph items and/or databases containing the corpus of information.
The patent provides specific examples using a subject entity that was a popular television show:
By way of example, a knowledge graph item for the subject entity “Breaking Bad” may include a corpus of information including the names of the actors who acted in the television show “Breaking Bad,” producers, directors, cinematographers, etc. associated with the television show, information about first release date, number of episodes, number of seasons, and/or duration of the television show, awards received by the television show or by the actors in the television show, summaries of episodes, blog posts, critics reviews, user reviews, news articles, magazine articles, speeches, books, or other content items associated with the television show “Breaking Bad,” etc. By way of another example, the knowledge graph item may include additional information such as the frequency with which users 112, 114 may have searched for information or posted comments regarding the television series “Breaking Bad,” or the popularity of the name of the show, “Breaking Bad” in a corpus of content items.

By broadening out the information that might be known about a particular subject entity based upon a knowledge graph, much more can be told about that entity. The patent tells us:
By way of example, the names of each of the actors, producers, directors, etc. of the television series “Breaking Bad,” obtained from the associated knowledge graph item, may constitute additional subject entities. By way of another example, names of events like award show where the television show was mentioned and/or the names of celebrities who attended the award show, etc. may also constitute additional subject entities. In certain embodiments, the identification of additional subject entities may include a recursive process. For example, after obtaining names of events where the television show was mentioned, knowledge graph items associated with the events may be searched to identify speakers, presenters, or other people associated with those events as subject entities. One or more additional subject entities may be selected from among the identified additional subject entities using relevance scores based on processes similar to those discussed concerning, for example, step 404 of process 400.
This wider range of subject entities from using information associated with a knowledge graph means that a much wider range of quotes can be included in a quote search (which sounds like it could be exciting.)
One of the aspects of this patent that I found interesting was a section that focused on scores that could determine how quote results might be ranked and displayed by Google.
Scores Associated with Quotes
Source-Page Scores
This shouldn’t come as a surprise. Quotes may be scored based upon a source page score for the content item may be based on the relevance of a content item, reputation or credibility of the author, publisher, or content item provider associated with the content item, and/or popularity of the content item, etc. We are told that:
A source page score based on the reputation or credibility may be determined by accessing the source page score from a database, which stores source page scores based on reputation or credibility in association with authors, publishers, or content item providers. The database of source page scores may be included in quotes database, in the content database, and/or in another database associated with system.
Popularity of Content Items
In addition to reputation and credibility, we can’t overlook things such as the popularity of a content item or an author of the content item. That could be determined based on the “popularity of the content item, the author, or a combination of the content item and the author in the corpus of content items.” Unsurprisingly, since a search engine can keep track of such things, this popularity of the content item may be determined based on (1) the number of times users access a content item or (2) based on the number of times users searched for a content item on the web.
The impact of high popularity?
A higher source page score may be assigned when a content item and/or an author of the content item have relatively high popularity. In certain embodiments, the popularity of a content item may be determined, for example, determining the popularity of a subject entity as discussed above-concerning step 404 of process 400. By way of example, an article containing a quote by President Obama on the television series “Breaking Bad” may have a high source page score if it has been accessed by a large number of users, for example, several thousand users compared to an article which may have been accessed only by 50 to a 100 users.
Relevance Scores for Quotes
I’m not sure we could tell this patent was from Google if this factor wasn’t mentioned in the patent:
A relevance score for a quote may be based on whether the quote is responsive to a query. In some embodiments, responsiveness may be determined based on the popularity of the quote, popularity of a content item containing the quote, popularity of an author of the quote, popularity of subject entities associated with the query, etc. The popularity of a quote, a content item, or an author of a quote or content item may be determined as described above, based on, for example, the popularity of the quote, the content item, and/or the author in a corpus of content items or user searches on the web. The popularity of a quote, a content item, or an author of a quote or content item may also be determined, for example, based on the frequency with which the quote, the content item, and/or the author appear with one or more of each other in the corpus of content items on in user searches on the web. In certain embodiments, a quote may receive a higher relevance score when the popularity of the quote, content items containing the quote, and/or authors of the quote or the content items containing the quote is high. In other embodiments, a quote may receive a high relevance score when the popularity of the quote together with subject entities associated with the query in the corpus of content items or user searches on the web is high. In yet other embodiments, the relevance score may be based on the relative scores of the subject identities identified in, for example, step 404 of process 400 and/or step 506 of process 500.
This section does give us examples to better place this aspect of scoring in context for us:
By way of example, a quote describing how breaking something may be considered bad may receive a low relevance score as compared to a quote related to the television show “Breaking Bad” because of the high popularity of the television show “Breaking Bad.” By way of another example, a quote regarding Nelson Mandela appearing with the subject entity President Obama may receive a higher frequency score because the quote may occur more frequently in a corpus of content items or user searches as compared to a quote regarding Nelson Mandela appearing with a subject entity such as, “world leader.” Further, in other embodiments, a relevance score may be determined based on whether the quote may be relevant to a particular user. For example, a relevance score may be determined by determining the popularity of the quote in a particular user’s profile or search history.
Recency Scores for Quotes
Something that we often see in news results is a recency score. And that is something that is mentioned about a quote search. This probably shouldn’t be a surprise. The patent tells us that:
A recency score may be based on the time elapsed between when the quote was authored and the time when the quote was identified as being associated with a query. In some embodiments, the time elapsed may be determined based on the current date, for example, the date of query and the data associated with the quote based on the information associated with the quote as obtained, for example, from quotes database. By way of example, a quote from the year 2014 may receive a higher recency score compared to a quote from the year 2012 in response to a query in the year 2014.
Frequency Scores for Quotes
Because this is something that a search engine can track, it makes sense to see it here. I suspect it could be a noisy signal, but there may be ways to limit how noisy it could be, such as limiting users accessing this information to people identified by cookies, or device IDs. The patent tells us that:
Determining the frequency score may include, for example, determining the number of times the quote may have been accessed by users, the number of times the quote appeared in the corpus of content items, or the number of times the quote may have been identified in response to a query. By way of example, a quote may receive a higher frequency score if the quote has been accessed by more users compared to a quote, which may have been accessed by fewer users.
An Overall Quote Score for a Quote
Many of the different scores mentioned in the patent might be combined into an overall quote score. This could include the source page score, the relevance score, the recency score, the frequency score, and/or another score associated with the quote. The patent tells us that these scores could be combined in several different ways.
Grouping Quotes into Sets
Something that you may see in places such as reverse image search is a grouping of results into different categories. This patent tells us that “quotes may be grouped into sets based on a relationship between the quotes, a relationship between the subject entities identified, and/or a relationship between authors of quotes.”
Again the patent provides an example for us:
…quotes made by political figures, such as President Barack Obama or Hillary Clinton, regarding “Breaking Bad” may be grouped into one set of quotes, while quotes made by film personalities, such as Clint Eastwood or Robert De Nero, regarding “Breaking Bad” may be grouped into another set. A set score may be assigned to each set of quotes based on the quote scores included in each set. In certain embodiments, set scores may be determined based on the popularity of the authors associated with the quotes.
Ranking Quotes by Quote Scores
We may need to wait until we see quote searches in action to see if it seems that Quote Scores have been used to rank quote results. This seems like an interesting way to provide information to searchers, based upon what specific people have said about specific topics. I would like to see this delivered to us by Google. I think it would be both fun and informative.
Added January 6, 2020, This patent has been updated through a continuation patent, and the process behind the patent has been updated. I wrote about the update in the post, Google Has Updated Quote Searching to Focus on Videos