


Word Sense Disambiguation Using Neural Networks
Published: June 01, 2020
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

Word Sense Disambiguation Helps Google Understand the Meaning of a Word on a Page
About 40% of English words are polysemous. This means that they have more than one meaning. Some words, such as run or set have more than thirty different meanings. Polysemous words can cause difficulty in contexts where the meaning is other than the primary* meaning of the word.
~ Polysemy
In 2016, I wrote a post Google Patents Context Vectors to Improve Search. The patent I wrote about tells us that when a word has more than one meaning, Google might look at other terms on a page to try to get a better sense of the meaning of that word on that page. That Context Vectors patent provided the following example of the different senses that a word may hold:
For example, a horse to a rancher is an animal. A horse to a carpenter is an implement of work. A horse to a gymnast is an implement on which to perform certain exercises. Thus, the communication element that we call “horse” belongs to, or pertains to, multiple domains.
My takeaway from the Context Vector patent was to find a knowledge base article about the meaning of a word that has more than one meaning and find words from that knowledge base article that might put that word into context.
Related Content:
For example, a page about a horse, the animal, would be better understood if it had words such as “hooves” and “hay” and “pasture” on it. These are not synonyms, and they are not semantically related words. They are words that tend to co-occur on a page with the word “horse” and provide context to that page to indicated that is is about an animal named a horse.
One place where you can find lots of senses for different words is the Princeton site Wordnet.
At the end of November of last year, Google was granted a patent that reminded me very much of the Context Vectors Patent I wrote about four years ago. This newer patent is about word sense disambiguation.
It tells us that Google may be using neural networks to perform word sense disambiguation. That 2016 patent talked about domain list terms to identify the domain of knowledge that a word might come from, and may use to perform word sense disambiguation.
This patent tells us that it describes a system that can be used to:
…determine the word sense of a word when the word appears in a text sequence with one or more context words.
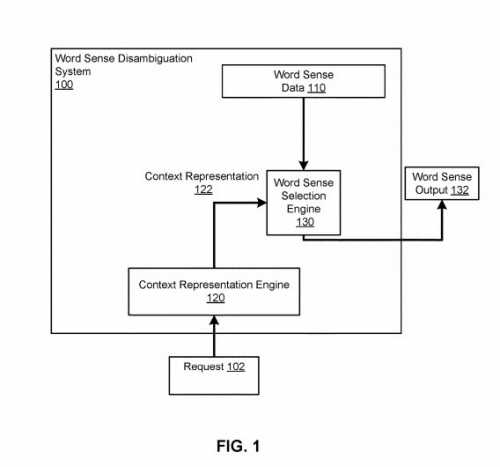
Rather than referring to terms as “domain list terms” like in the context vectors patents, it refers to context words that might be used to help a search engine understand word senses:
In particular, the system maintains a respective word sense numeric representation of each of multiple word senses of the word. The system receives a request to determine the word sense of the word when included in a particular text sequence that includes one or more context words and a particular word. The system determines a context numeric representation of the context words in the particular text sequence and selects the word sense having the word sense numeric representation that is closest to the context numeric representation as to the word sense of the word when appearing in the particular text sequence.
The patent tells us what the advantages are of using the word sense disambiguation process described within it:
The word sense disambiguation system described in this specification can effectively disambiguate the word sense of words appearing in text sequences based on only the other words in the text sequence. The word sense disambiguation system can effectively incorporate unlabeled and therefore readily available text data when determining the numeric representation for a given word sense rather than needing to rely solely on labeled text data.
So, when a page tells you it is about “Fishing for bass,” it is about a type of fish based on the context word “fishing,” rather than a musical instrument.
This patent can be found at:
Determining word senses using neural networks
Inventors: Dayu Yuan, Ryan P. Doherty, Colin Hearne Evans, Julian David Christian Richardson, and Eric E. Altendorf
Assignee: Google LLC
US Patent: 10,460,229
Granted: October 29, 2019
Filed: March 20, 2017
Abstract
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for disambiguating word sense. One of the methods includes maintaining a respective word sense numeric representation of each of a plurality of word senses of a particular word; receiving a request to determine the word sense of the particular word when included in a particular text sequence, the particular text sequence comprising one or more context words and the particular word; determining a context numeric representation of the context words in the particular text sequence; and selecting a word sense of the plurality of word senses having a word sense numeric representation that is closest to the context numeric representation as to the word sense of the particular word when included in the particular text sequence.
One of the inventors behind the patent, Colin Evans tells us of his work at Google as a Senior Software Engineer:
I’m currently managing a research team and building scalable neural network models for understanding text and semantic data. I’ve worked on the Google Knowledge Graph, large scale machine learning, and information extraction systems, and natural language understanding backed by semantic databases.
We don’t have much more information from the profiles of the other inventors on the patent. But, there is a Google white paper that looks like it is related to this patent that has the inventors of this patent listed at authors:
Semi-supervised Word Sense Disambiguation with Neural Models
The Abstract of the paper provides details on what it is about:
Determining the intended sense of words in the text – word sense disambiguation (WSD) – is a longstanding problem in natural language processing. Recently, researchers have shown promising results using word vectors extracted from a neural network language model as features in WSD algorithms. However, a simple average or concatenation of word vectors for each word in a text loses the sequential and syntactic information of the text. In this paper, we study WSD with a sequence learning neural net, LSTM, to better capture the sequential and syntactic patterns of the text. To alleviate the lack of training data in all-words WSD, we employ the same LSTM in a semi-supervised label propagation classifier. We demonstrate state-of-the-art results, especially on verbs.
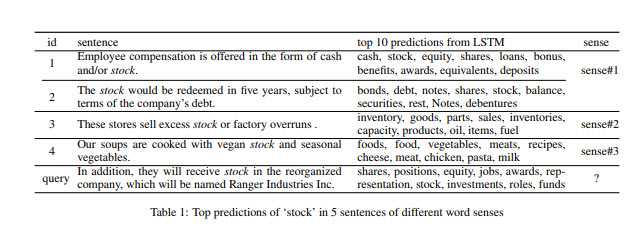
The following table from the paper shows how context terms can be identified that show off different senses of the word “stock.”
The patent explains the same concept in this way:
?A word sense of a given word is the meaning of the word when used in a particular context. Because many words have different meanings when used in different contexts, the system disambiguates the possible word senses for a word using the context for the word, i.e., the other words in the text sequence identified in the request, to select the appropriate word sense to return in response to a received request. For example, when used in the sequence “I went fishing for bass,” the word “bass” has the sense “fish,” while when used in the sequence “My friend plays the bass,” the word “bass” has the sense “musical instrument.”
Once a word sense has been identified, a word that has been better understood by this process might be used in other ways by a search engine. The patent tells us that some examples may include performing:
- Sentiment analysis
- Question answering
- Summarization
- Another natural language processing task
Word Sense Numberic Representations
As the paper tells us, this process is a matter of word sense disambiguation. The patent puts it into context for us by telling us about how the word sense numeric representation process is used to understand the word sense in a textual passage that contains the word and a context word:
In particular, the system selects the word sense (among the different word senses for the particular word) that has the word sense numeric representation that is the closest to the context numeric representation according to a distance metric. For example, the distance metric can be cosine similarity and the system can select the word sense that has the word sense numeric representation that has the highest cosine similarity with the context numeric representation.
In some cases, the particular word may be able to have multiple lemmas, multiple parts of speech, or both. In these cases, the system considers only the word sense numeric representations for word senses for the particular word that are associated with the same lemma and part of speech as the particular word has when used in the particular text sequence.
The patent points out a paper from the Google Brain team about word vectors, which is involved in the process behind this patent:
Example techniques for training such a system and generating the representations are described in Tomas Mikolov, Kai Chen, Greg S. Corrado, and Jeffrey Dean, Efficient estimation of word representations in vector space, International Conference on Learning Representations (ICLR), Scottsdale, Ariz., USA, 2013.
This word representation process is used in the context words:
The system adjusts the word numeric representation for each of the context words based on a rank of the context words in a ranking of the word in the vocabulary of words, e.g., a ranking based on the frequency of occurrence of the words in the vocabulary in a text corpus, to generate a respective adjusted word numeric representation for each of the context words (step 304). For example, the system can generate the adjustment factor from the rank of the context word and then multiply the word representation by the adjustment factor to generate the adjusted representation. In some cases, the adjustment factor is equal to the logarithm of the rank plus a constant value, e.g., one.
The system combines the adjusted word numeric representations to generate the context numeric representation (step 306). For example, the system can sum the adjusted word numeric representations, average the adjusted word numeric representations, or apply a different combining function to the adjusted word numeric representations to generate the context numeric representation.
Generating a Word Sense using Numeric Representations
The patent does provide more details on the process “for generating a word sense numeric representation for a particular word sense of a particular word.”
A word sense disambiguation system performs this process.
It starts by obtaining multiple example text sequences which each include the particular word and one or more respective context words.
The patent details how word senses understood by those context words might help define the word sense being used in those test sequences.
Take aways from this Word Senses Approach
Writing naturally appears to be the best way to optimize so that Google can understand the word sense being used by the choice of a word that might have multiple word senses. If you are writing about fishing for bass, your choices of words in what you write will be very different than when you may write about performing a song with a bass stringed musical instrument.
Make sure when you write about a word that may have multiple senses that you use context terms that help define the meaning of that word.