





Microsoft Disses Watson, Describes a Natural Language Processing Approach to Question Answering
Published: January 07, 2014
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url
Perhaps you caught the post What “viable search engine competition” really looks like from Alex Clemmer, a Microsoft Engineer who tells us that:
There are a limited number of search relevance engineers available, and many of them work for Google.
He also tells us:
This is a constant problem for all who enter the field and to be a viable threat to Google, you will need to take this into account and compensate somehow. We have our strategies for dealing with this problem.
It looks like one of those strategies is to let the Microsoft Research Asia team address some of the really hard problems, and they have a long history of doing just that, from VIPS: a Vision-based Page Segmentation Algorithm, to Object-Level Ranking (pdf) to more recent research, such as inquiries into natural language processing from principal researcher Ming Zhou, who dabbles on the side in creating programs capable of composing poetry. (Take that, Ray Kurzweil.)
Knowledge Bases like Probase and Watson Too Much Work?
A couple of months ago, I wrote about Microsoft’s Concept-Based Knowledge Base, Probase, speculating on why Microsoft appeared to have abandoned building the “world’s largest” concept-based knowledge base, especially since it seemed to solve the kind of problem that Google’s Hummingbird update might – understanding concepts within queries and delivering meaningful answers to them even if the words within the queries didn’t appear on web pages returned to searchers.
Related Content:
It looks like I got an answer in a recent patent application from the Microsoft Asia Research team that seems to stress that such a powerful knowledge base, like the chess-and-jeopardy-playing Watson from IBM, might not be the best solution:
Previous solutions tend to rely on a curated knowledgebase of data to answer natural language queries. This approach is exemplified by the Watson question-answering computing system created by IBM., which famously appeared on and won the Jeopardy! game show in the United States. Because Watson and similar solutions rely on a knowledge base, the range of questions they can answer may be limited to the scope of the curated data in the knowledge base. Further, such a knowledge base may be expensive and time-consuming to update with new data.
We recently learned that supercomputer Watson has some difficulties with the use of slang after it was programmed to learn from the Urban Dictionary, and that programming was unlearned after an answer of “bullshit” to a question that was presented to it.
This doesn’t mean that Bing is abandoning the use of knowledge base information from sources such as Wikipedia or Free Base (Google’s knowledge base acquired originally during their merger with Meta Web). The patent filing mentions multiple times how information might be found to help answer questions from such sources, but it also describes how natural language processing plays a large role in answering questions as well. In short, the process described in the patent application has several parts:
In some examples, on receiving a natural language question entered by a user, an analysis is performed to determine a question type, answer type, and/or lexical answer type (LAT) for the question. This analysis may employ a rules-based heuristic and/or a classifier trained offline using machine learning. One or more query units may also be extracted from the natural language question using chunking, sentence boundary detection, sentence pattern detection, parsing, named entity detection, part-of-speech tagging, tokenization, or other tools.
That information may then be used as the foundation of queries used to gather evidence (answers on the Web). Multiple answers might be found and analyzed to determine which is the most likely answer based upon a ranking program that uses machine learning to decide upon the most probable answer. The patent is:
Learning-Based Processing of Natural Language Questions
Invented by Ming Zhou, Furu Wei, Xiaohua Liu, Hong Sun, Yajuan Duan, Chengjie Sun, and Heung-Yeung Shum
Assigned to Microsoft Corporation
US Patent Application 20140006012
Published January 2, 2014
Filed: July 2, 2012
Abstract
Techniques described enabling answering a natural language question using machine learning-based methods to gather and analyze evidence from web searches. A received natural language question is analyzed to extract query units and to determine a question type, answer type, and/or lexical answer type using rules-based heuristics and/or machine learning trained classifiers.
Query generation templates are employed to generate a plurality of ranked queries to be used to gather evidence to determine the answer to the natural language question. Candidate answers are extracted from the results based on the answer type and/or lexical answer type and ranked using a ranker previously trained offline. Confidence levels are calculated for the candidate answers and top answer(s) may be provided to the user if the confidence levels of the top answer(s) surpass a threshold.
Natural Language Questions
We’ve been trained by search engines to ask queries using the least among of words, but that’s not quite how we talk naturally when asking questions. We’re more likely to ask “When was the Magna Carta signed?” when performing a voice search than we are when typing in a query at a search engine, where that might be shortened to [Magna Carta signed]
The patent tells us that there are four phases that might be gone through to answer a question like this:
- Question Understanding
- Query Formulation
- Evidence Gathering
- Answer Extraction/Ranking
Here’s an example of a question and answer from the patent filing that they also provide a flow chart for, showing some of the analysis that they perform at these different phases:
Upon receiving the natural language question: “Shortly after this `Gretchen am Spinnrade` composer met Beethoven, he was a torchbearer at his funeral.” Embodiments employ web search evidence gathering and analysis (at least partly machine learning-based) to attempt to ascertain an answer. The actual answer in this example is “Franz Schubert.” (Funny how that reads like a Jeopardy question, and they point at Watson as a dead-end approach to solving these types of problems.)
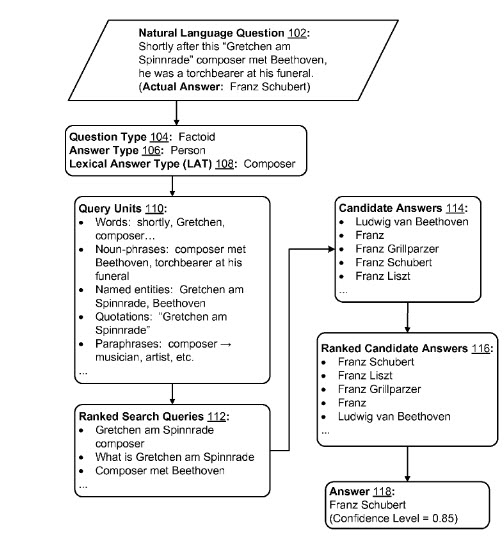
Question Understanding
Question Understanding includes analysis of the natural language question to predict a question type and an answer type.
Question types may include:
- Factoid types (e.g., “What is the capital of Bulgaria?”)
- Definition types (e.g., “What does `ambidextrous` mean?”)
- Puzzle types (e.g., “What words can I spell with the letters BYONGEO”)
- Mathematics types (e.g., “What are the lowest ten happy numbers?”)
- Or any other type of question.
Answer types may include:
- A person
- A location
- A time/date
- A quantity
- An event
- An organism (e.g., animal, plant, etc.)
- An object
- A concept
- Any other answer type.
A lexical answer type (LAT) might also be predicted – the LAT may be more specific and/or may be a subset of the answer type. For example, a question with answer type “person” may have a LAT of “composer.”
Question Understanding may also include extracting query units from a natural language question, such as:
- Words
- Base noun-phrases
- Sentences
- Named entities
- Quotations
- Paraphrases (e.g., reformulations based on synonyms, hypernyms, and the like), and
- Facts
Query units may be extracted using a grammar-based analysis of the natural language question, such as:
- Chunking
- Sentence boundary detection
- Sentence pattern detection
- Parsing
- Named entity detection
- Part-of-speech tagging
- Tokenization
So, as seen in the example image, a natural language question could include:
- Query units such as words (e.g., “shortly,” “Gretchen,” “composer,” etc.)
- Noun-phrases (e.g., “composer met Beethoven,” “torchbearer at his funeral,” etc.)
- Named entities (e.g., “Gretchen am Spinnrade,” “Beethoven,” etc.)
- Quotations (e.g., “`Gretchen am Spinnrade`”)
- Paraphrases (e.g., rewording composer to “musician,” “artist,” and so forth)
Query Formulation
Information from the Question Understanding phase may be used to create one or more search queries for gathering evidence to determine an answer to the natural language question. This could be done by taking extracted query units as well as question type, answer type, and/or LAT and applying them to one or more query generation templates to generate a set of candidate queries.
These candidate queries may be ranked using a ranker trained offline using an unsupervised or supervised machine learning technique such as support vector machine (SVM). A predefined number N (e.g., 25) of the top-ranked queries may be sent to be executed by search engines such as Bing.
Once the question is better understood, and some possible queries are created and sent to the search engine, the next phase is entered.
Evidence Gathering
The top N (n can be the top 10, top 50, or some other number) ranked search queries are executed by search engine and the search results are analyzed. The top N results of each search query (e.g., as ranked by the search engine that executed the search may be are merged to create a merged list of search results. These can include addresses for resulting web pages and may be filtered to remove duplicate results and/or noise results.
Answer Extraction/Ranking
Candidate answers may be extracted from the search results. This can involve dictionary-based entity recognition of named entities in the search result pages that have a type that matches the answer type and/or LAT determined in the Question Understanding phase.
The extracted named entities may be normalized to expand contractions, correct spelling errors in the search results, expand proper names (e.g., Bill to William), and so forth. In the pictured example above, extracted candidate answers include Ludwig van Beethoven, Franz, Franz Grillparzer, Franz Schubert, and Franz Liszt.
The candidate answers may then be ranked by applying a set of features determined for each candidate answer to a ranker trained offline using a machine learning technique, and a confidence level may be determined for one or more of the top-ranked candidate answers. In the example, the answer is Franz Schubert.
Take Aways
Instead of an all-knowing knowledge base that can answer any questions, like Watson, Microsoft describes in their patent filing an approach to answering questions that rely upon four phases – Question Understanding, Query Formation, Evidence Gathering, and Answer Extraction/Ranking. The patent provides a complex example of a natural language question with multiple parts and shows us a number of the steps that it takes to figure out the answer using resources on the Web without gathering all of that information into a well-structured knowledge base.
This does appear to be a different direction that Google is following in building their knowledge base. One gets the sense that Google is trying to build an all-knowing computer that answers questions in a Star Trek-like manner.
It looks like Microsoft is trying to build a search engine that understands queries better, and rewrites them to get answers from the Web itself.