


How Rich Results May be Chosen and Created (Granted)
Published: September 25, 2018
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

Added December 17, 2019 The patent this post is about has been granted today and can be found at Rich results relevant to user search queries
A History of Google’s Indexing of Books
In Google’s First Semantic Search Invention was Patented in 1999, I wrote about an invention from Google founder Sergey Brin, about an algorithm known as DIPRE (Dual Iterative Pattern Relation Expansion). It started off with a list of five books, and information about those books, such as:
- Publisher
- Publication data
- Length
- Author
It used a crawler to search the web for sites that listed these books, and after finding them, and indexing related information for them, it would collect facts about other books that might be listed on the same site.
Related Content:
So, when Google comes out with another patent about collecting similar information about books and displaying that information in rich results, it doesn’t come as a surprise.
Beyond 10 Blue Links; Google Showing Rich Results
That new patent hasn’t been granted yet, but previous applications for it had been filed before in 2015, 2013, and 2010. The patent is about how Google might display information-rich results in SERPS, and it reminded me of a Google Blog post that came out in 2009 that you may have seen before:
The closest patent I had seen to one about rich results was one that Google came out with about enriched results, which gave us eye-catching search results, but weren’t quite what rich snippets came out like.
There is a Google Custom Search help page on Rich Results which tells us more about how to achieve rich snippets for such things as crawl your site, “reviews, people profiles, products, recipes, music, and events.”
But this one seems to have been one of the earliest that I have seen about rich results from Google, and it is about showing off additional information about books. The patent tells us the motivation for such results, in this way:
Users of search engines are often looking for information about a specific entity, for example, a book, rather than a listing of individual resources.
Rich Results Focus Upon Filling Informational Needs
The patent describes how it fulfills such an informational need, like this:
This specification describes technologies relating to presenting a rich result in response to a search query, where it is determined that the query relates to a particular book or other publication. The rich result is a formatted presentation of content that is relevant to the query and that contains pieces of information from multiple collections of information. For example, the rich result may contain links to the publisher’s website, seller websites, or informational websites. The rich result may additionally include information about the publisher, publication year, pages in the book, and a snippet or synopsis from the book.
This is also the source of information that describes in detail how a resource might be scored so that it shows up as a response to a query that might show a rich result on a request for more information about a specific book.
- Obtaining search results responding to a query from book resources
- Determining a score for a first result ranked first that satisfies a threshold relative to respective scores of other publication results
- Generating a rich result for the first publication result, which comprises data from the first publication result and the one or more web resources, and providing the rich result with the publication search results
Where Rich Results Come From
The patent has some requirements for the site that is the source of a rich snippet, and it lays those out for us, like this:
-
- The score for the first publication result satisfies the threshold if the score is at least a threshold multiple of a score for a book search result ranked second in the ranked order of publication search results. The score for the first publication result satisfies the threshold if the score is at least a threshold multiple of a score for a publication search result ranked third or fourth in the ranked order of book search results.
- Generating the rich result also includes obtaining price information for the publication and including price information with the rich result. The price information would be obtained from a products corpus, with an ISBN and receiving a price for a book corresponding to the ISBN.
- Providing a products corpus with an ISBN comprises obtaining the ISBN from the data associated with the first publication result.
- Generating a rich result comprises correcting data from the corpus of book resources using data from the web resources. Correcting data from the corpus of book resources comprises comparing the data from the corpus of book resources with one or more variants of the data from the web resources and selecting the most popular variant for the rich result.
So, it looks like one of the purposes behind Book Rich Results is to provide information that would be helpful for someone who might be interested in purchasing a book searched for. That very last part involves using factual information from sources across the web to correct data about the book, using the most popular information available.
Information shown in Rich Results
The Rich Results for a book might contain some specific information, such as:
-
-
- A publication snippet. The snippet is a publication excerpt or a publication summary.
- One or more authors of the publication. Correcting data from the corpus of book resources further comprises correcting the one or more authors of the publication using data from the web resources.
- A link to a preview of the publication.
- Links to related websites.
- Links to bookseller websites.
- Publisher information for the publication. The publisher’s information comprises a link to a website of a publisher of the publication. The method further comprises correcting the publisher information using data from the web resources.
-
Advantages of Book Rich Results
Many patents tell us about the problems that they intend to solve, and the processes they might use to do that. In the description part of the patent, they sometimes provide a list of the advantages that following the process in the patent they work to protect may involve, and this rich results patent does that as well telling us about the advantages it provides:
-
-
-
- Users can be presented with relevant information about publications in response to their queries.
- Users can be provided with a richer search experience through an interface providing easy access to information related to the publication referred to in the search query.
- Users can easily find publication information and websites related to their search queries.
- Users can be provided convenient ways to purchase publications they have searched for.
-
-
The updated version of this patent can be found here:
Rich Results Relevant to User Search Queries
US Patent Application: 20180253498
Application Date: August 5, 2018
Publication Date: June 9, 2018
Applicants: GOOGLE LLC
Inventors: Matthew K. Gray, Gregory H. Plesur, and Garrett H. Rooney
Abstract:
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for triggering rich results in response to queries. In one aspect, a method includes receiving a query. One or more search results are obtained from a first corpus. A rich result is triggered based on a score of the first-ranked search result if it meets a threshold relative to other search results. The rich result is populated with additional metadata about the first-ranked search result obtained from a second corpus. The rich result is provided in response to the query.
Additional Takeaways from the Rich Results patent
The decription of the patent goes into more details if you would like to see them. For instance, it tells us that resources about books that might be found on the Web could include:
-
-
-
- A publisher’s website
- Book review websites
- Book seller websites
- Book synopsis websites
-
-
It also tells us that information about a publication might be taken from more than one of these resources, and a rich result may combine that information in a rich result for a publication.
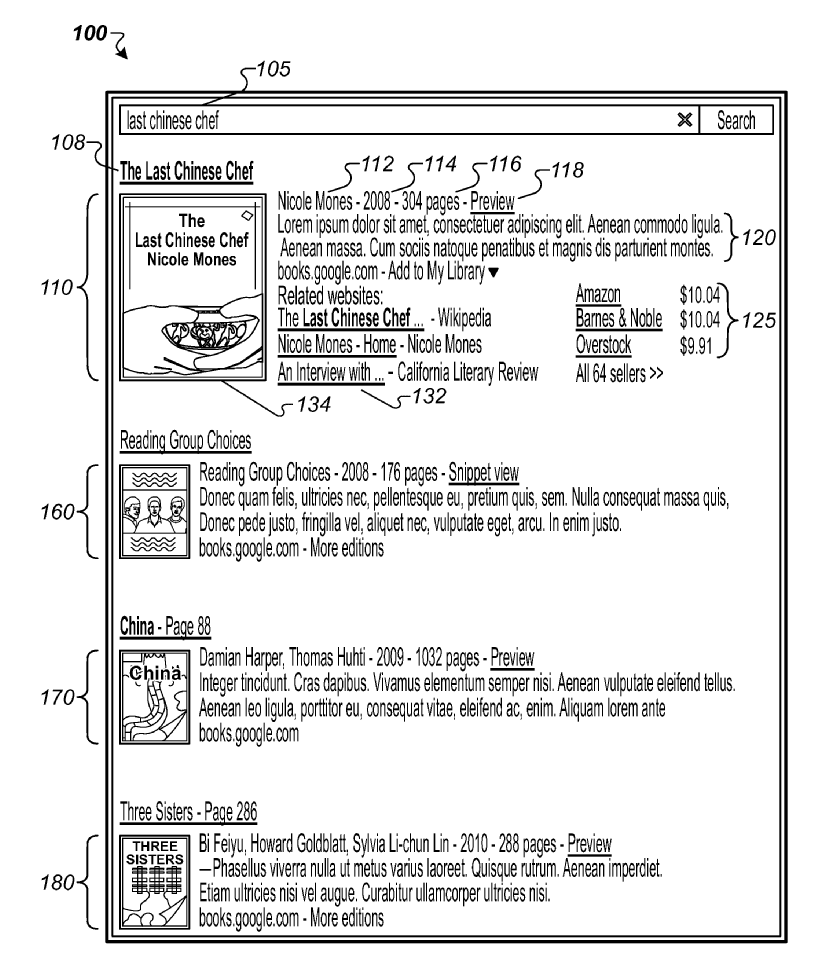
The patent provides an example of a rich result for the query “last Chinese chef.”
Note that in addition to information about the publication itself, there are links to booksellers who may provide the book, and others, such as the publisher’s site.
The patent tells us about indexing and clustering of search results and a publication index, and I thought this section about a rich result engine was worth sharing because it tells us about when certain rich results might be triggered in response to certain queries:
The rich result engine can compare information in multiple corpora to improve the data quality of the information provided in a rich result. For example, the rich result engine can determine a correct capitalization for a book title by comparing variant capitalizations of the book title in multiple corpora and selecting the most popular variant. The rich result engine also determines whether a rich result should be triggered as part of a response to a publication query. For example, the rich result engine may trigger a rich result only for publications that meet a particular popularity threshold.
More about that popularity threshold for triggering rich results here:
The search system determines whether a rich result should be triggered and presented with the search results ( 320). In some implementations, the search system triggers a rich result when the score of the first-ranked result in the book results is substantially higher than any of the other book results.
In addition to a specific query term triggering a rich result, information from the metadata record of a book resource that might be associated with the first ranked result in the book results could determine that a rich result appears in response to a query.
If you are interested in all of the aspects behind rich results appearing in response to a query, including how rich results are triggered for only some queries (with the use of thresholds), and about how information about specific books might be clustered, reading through the entire patent is recommended.
I’m not sure if Google will show rich results for most books. They are showing knowledge panels for them on searches on do now. But I think that some of the ideas behind this patent, like how Google might look through a corpus of resources to correct facts for rich results might be used in other rich results.
Knowledge Panels as an Alternative for Rich Results
Instead of a rich result, Google may have decided to show knowledge panels for books, which would be a business process decision that it could be faced with when it comes to other types of entities that it might show answers for. Here is a knowledge panel for the Book, The Sun Also Rises, which contains a lot of the things that this patent tells us a rich result would contain:
