


Structured Metadata Used by Google in Episodes and Song Results
Published: February 12, 2015
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

What is Structured Metadata?
Sometimes certain searches at Google trigger unusual rich search results. We like to try to get an idea of how those types of results come about, and why.
That’s one of the reasons why I like looking through Google patents, to see if I can find explanations for features we see at Google. A patent granted to Google this week explained one type of search result that I was curious about, involving what is referred to as structured metadata.
A query using the word “episodes” teamed with the name of a TV show may result in an actual listing of episodes for that TV series. A search for [i love lucy episodes] turns up this kind of result at Google:

A search for ‘I love Lucy episodes returns a unique layout of episode listings.
It’s not just older TV shows that get treatment like this, but even more modern shows, like “The Walking Dead:”
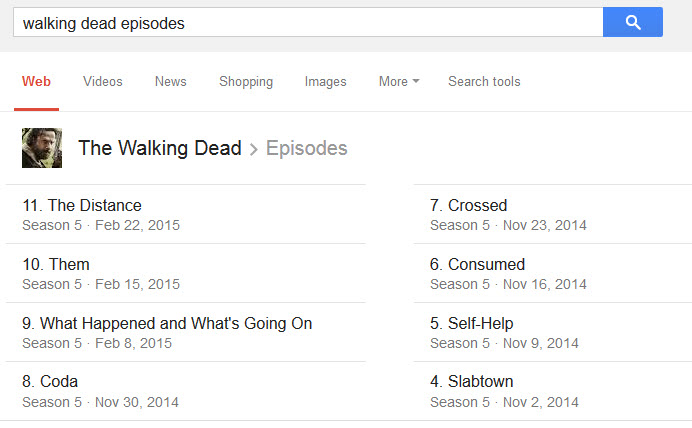
A search for ‘Walking Dead episodes shows a results layout naming the most recent episodes.
These episode listings spread across a computer desktop page from left to right, and often scroll in either direction with arrows that appear over either end if you hover a mouse over them.
Related Content:
A very similar feature appears for searches that involve music, with a search for an artist’s name, and then the word “songs.” For example, here’s a song list for [springsteen songs]:
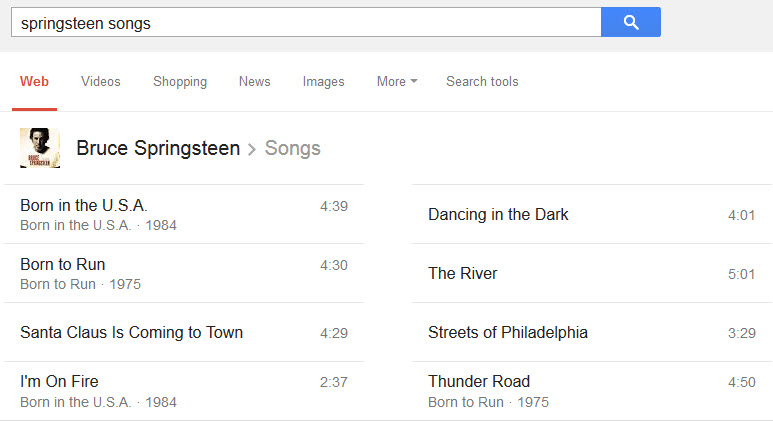
Very similar to the episodes results are results for songs from a particular artist.
And this type of song result is even interactive to a degree. For example, when I search for [tom waits songs], I get a listing of songs in Google, like this:
![A search for [tom waits songs] turns up a structured metadata.](https://gofishdigital.com/wp-content/uploads/2025/07/tomwaitssongs.jpg)
A search for [tom waits songs] turns up a similar set of results.
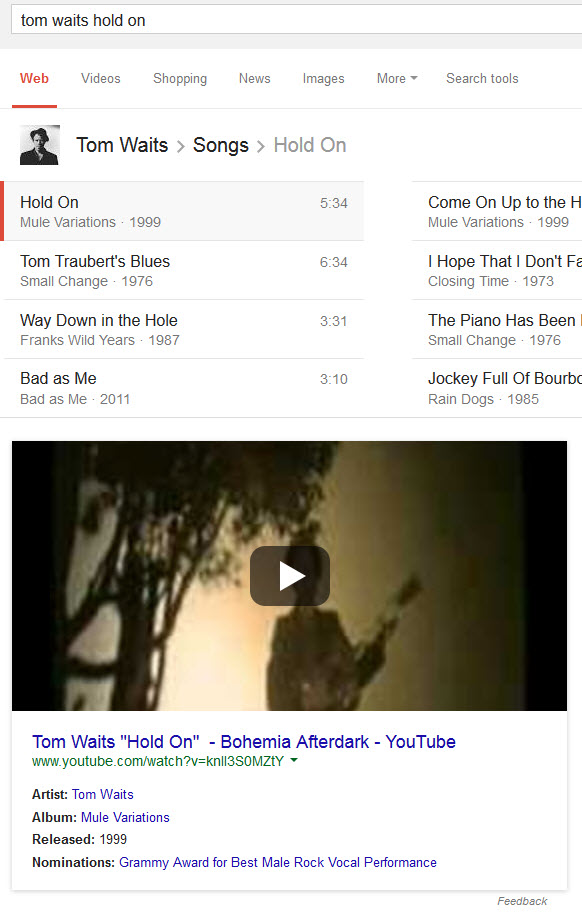
These song results are interactive, and clicking upon one song gives me a video of that song in this instance.
A patent granted to Google this week about structured metadata describes how these lists are made by Google.
Part of the process is finding mentions of entities, like the TV series “I Love Lucy” or “The Walking Dead” on pages that list the episodes made for those. This is an automated process, and it involves looking for patterns from page URLs, from links, from lists, and so on, that Google could use to get a list. It’s quite likely that Google would look for a few copies, maybe in different formats, and extract lists from those to compare with each other and to make sure that their lists are complete.
Same with the musical artists – look for pages where they are mentioned, find the different URLs or lists that they are mentioned in, understand the patterns where they are listed, and extract song titles and album titles and other information that might be displayed with them as well.
The patent describes how they go about this process. It starts though by mentioning the reason why they came up with this approach:
Many web sites provide access to structured data. For example, some websites compile information about different episodes of television shows in a structured format.
Compiling a list of episodes can be accomplished by accessing this stored data and organizing it accordingly. However, because different websites use different formats, extracting desired data has been accomplished by manual techniques.
Given the large numbers of TV Episodes and songs available, if people were in charge of manually entering episodes and song names into a database for them to be returned in results like above, it could take a lot of people, and a fair amount of time and chances are it would become out of date quickly.
By automating the structured metadata process, and extracting the information from websites that might contain such information, the process is speeded up, and likely more up to date as well.
The structured metadata patent is:
Structured metadata extraction
Invented by Yiqiang Mao, Alvin Tang, Nitin Khandelwal
Assigned to Google
US Patent 8,954,438
Granted February 10, 2015
Filed: May 31, 2012
Abstract
Structured metadata extraction may include accessing one or more documents from which to extract the structured metadata from each of a plurality of hosts. A plurality of entity names can be extracted from the one or more documents from one of the plurality of hosts using an entity name pattern.
A first element list can be extracted from the one or more documents based at least in part on the plurality of entity names and based at least in part on one or more heuristic rules.
An element list pattern may be generated based at least in part on the first element list, and a second element list may be extracted from the one or more documents based at least in part on the element list pattern.
We do see lists of TV episodes at knowledge bases like Wikipedia, which has a page specifically on Walking Dead episodes. The Producer of the series, AMC, also has a page listing episodes of The Walking Dead. IMDB also provides lists and synopses of episodes of The Walking Dead.
The patent provides several examples of patterns that might be used to extract structured metadata such as lists of episodes from pages like those of Wikipedia, the IMDB, and the creators or producers of a TV show. The patent mentions songs and TV episodes, but refers to other possible types of structured metadata that could also be extracted from pages:
Elements for a particular entity can be clustered and referred to collectively as an element list. Element lists can include element groups, which can include, for example, seasons of episodes, collections of songs, any other suitable categorization of elements, or any combination thereof.
So, mystery solved on the formatting of songs for a particular artist, and episodes for TV series. They aren’t taken directly from a source like Freebase, but possible from a range of sites across the web that provide that kind of data. Google has found a way to extract the information from those pages so that it can be presented in a unique query results layout.
We will be looking to better understand more unique query presentations like these, and what they might mean for website owners, in the future.