





Semantic Frames and Word Embeddings at Google
Published: May 28, 2019
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

Using Semantic Frames to Add Context to Word Embeddings
Word Embeddings are a way for Google to look at the text, whether a short tweet or query, or a page, or a site, and understand the words in those better. It can understand when it can add a word or a sentence, which is how to query rewriting under Rankbrain. But the Word Embedding approach doesn’t understand the context of words, like the difference between a riverbank or withdrawing money from a bank account. So, Google has been working on exploring ways to pre-train text so that not only can this natural language processing approach understand what might be missing, but possibly so that contexts and meanings of words can be better understood.
Related Content:
The words we speak can fit into semantic frames that give them meaning. The same is true with the words that we use on a Website. If a pre-training approach can associate possible semantic frames that words might fit into, that may make this kind of natural language processing may be more effective.
More About Semantic Frames
When I worked for the largest trial court in the State of Delaware, there were terms that we used that everyone working in the Court knew the meaning of. But weren’t words that most people would see in normal conversations. These included a capias (a bench warrant issued by a judge) or Nolle Pros’d (a notice of nolle prosequi filed by a deputy attorney general stating that they decided not to prosecute a charge from a grand jury or brought on a warrant by a police officer.) These words can mean that someone may end up imprisoned or released from jail or from a prison and are part of the everyday language framework for people who work in a court system. When those words are used within the context of a frame, such as the Criminal Justice System, they gain a lot of meaning.
Frame Semantics has been part of something known as computational linguistics for over 20 years. It appears to be something that Google will be working into some of the more recent technology that they have been coming up with, like the Word Vectors or word embeddings that are behind technology, such as their RankBrain Update. Before I talk about a Google patent that introduces that, it’s essential to look more at what Semantic Frames are and how they work.
Here’s a definition of Semantic Frames to give this post more preciseness:
Thus, conceptual structures (called semantic frames) provide a background of beliefs and experiences necessary to interpret the lexical meaning of the word in question.
The criminal justice system I start this post off with is a conceptual framework that gives words such as capias and Nolle Pros’d meaning. Without having been in that world, I wouldn’t understand them. I also wouldn’t know what the difference between prison and jail was either, and a jail is a place where someone stays before sentencing and convicted of a criminal offense, and a prison is where they go after a trial and sentencing. When someone uses either word and means the other, I know they haven’t worked in the criminal justice system; that frame is outside of their experience.
There is a project at the University of California at Berkeley, where people with experience in Semantic Frames are building knowledge about those frames in something called the FrameNet project. On the About Framenet pages, we can find out more about how Frame Semantics work.
Learning about the FrameNet Project at Berkeley is a good starting point for this post. This video provides a good sense of the work behind the project.
The FrameNet Database
I don’t usually start a blog post with a video, or even two of them. Still, I also watched and enjoyed this video explaining what frame semantics are, and thought that sharing this one, too, would make the process I am describing in this post make a lot more sense:
A course in Cognitive Linguistics: Frame Semantics
The video presents several frame semantics to help explain how a word derives meaning from the frame it appears within.
To provide more technical background, the founder of the FrameNet project at Berkeley wrote the following paper: Frame Semantics for Text Understanding. Spending time at the website of the Berkeley FrameNet Project can also be helpful.
Besides looking at the FrameNet project pages, it is rare seeing a Google Patent in which the inventors behind a patent have written a whitepaper on the same topic. I’ve seen this done with many patents from Microsoft, but only a handful from Google. In this case, there is one that is worth spending some time with. The paper is Semantic Frame Identification with Distributed Word Representations.
Websites that focus upon a specific industry or affiliation, such as construction or cooking, or music, may use words that are very relevant to the dialog that might be common among people engaged in those fields.
I explained how working at Delaware Courts gave me an understanding of words that were commonly used at a courthouse that often meant a difference between people incarcerated or released from prison, but which most people wouldn’t understand. In the video on cognitive Linguistics, we learn about the frame of someone waiting on customers in a restaurant and how words come from that frame. The frame of commercial buying was also mentioned and gets displayed in a screenshot from the Google Patent. We see how such language might work under that frame:
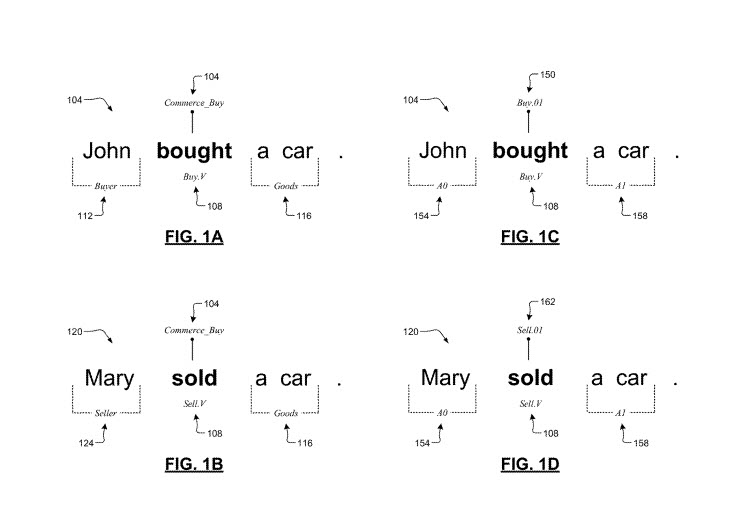
While this newly granted patent from Google tells us about how semantic frames may work with word embeddings, Google also has a patent about Word Embeddings, invented by members of the Google Brain Team, which I wrote about in the post, Citations behind the Google Brain Word Vector Approach.
Google’s Definition of Semantic Frames
Many patents have many definitions, and this new one from Google is no different. While I have provided some examples and a definition of what semantic frames are, and a couple of videos about it, looking at Google’s definition from the patent is worth doing because they provide context for how they may be used in their patent process is about. Here is how they define semantic frames:
Linguistic semantics focuses on the history of how words have worked in the past. Frame semantics is a theory of language meaning that relates linguistic utterances to word knowledge, such as event types and participants. A semantic frame refers to a collection of facts or a coherent structure of related concepts that specify features (attributes, functions, interactions, etc.) typically associated with the specific word. One example semantic frame is a commercial transfer or transaction situation, which can involve a seller, a buyer, goods, and other related things.
So, this use of Semantic Frames with Word Embeddings is interesting, and the look at Semantic Frames was one worth taking. The summary section of the description of this patent shows us how frames might be useful:
A computer-implemented technique is presented. The technique can include receiving, at a server having one or more processors, labeled training data, including a plurality of groups of words. Each group of words has a predicate word, each word having generic word embeddings. The technique can include extracting, at the server, the plurality of groups of words in a syntactic context of their predicate words. The technique can include concatenating, at the server, the generic word embeddings to create a high dimensional vector space representing features for each word. The technique can include obtaining, at the server, a model having a learned mapping from the high dimensional vector space to a low dimensional vector space and learned embeddings for each possible semantic frame in the low dimensional vector space. The technique can also include outputting, by the server, the storage model, the model can identify a specific semantic frame for an input.
This differs from the Word embeddings approach that Google patented because it includes a context behind word embeddings learned in Semantic Frames.
That is more clear in an alternative embodiment of the patent, also described in the summary section of the patent:
In other embodiments, the labeled training data includes (i) frames for verbs and (ii) possible semantic roles for each frame, and modifier roles in the labeled training data shared across different frames.
Question Answering
The summary also points at the possibility of this approach being useful in question-answering in response to spoken queries:
In other embodiments, the technique further includes: receiving, at the server, speech input representing a question, converting, at the server, the speech input to a text, analyzing, at the server, the text using the model, and generating and outputting, by the server, an answer to the question based on the analyzing of the text using the model.
Translation
Would this approach be useful in translation from one language to another? The patent summary tells us a variation of the process described within this patent could work in that manner:
In some embodiments, the technique further includes: receiving, at the server, a text to translate from a source language to a target language, the source language being the same as a language associated with the model, analyzing, at the server, the text using the model, and generating and outputting, by the server, a translation of the text from the source language to the target language based on the analyzing of the text using the model.
Search Results
Unsurprisingly, the summary of the patent also points to the possibility that the process behind the patent could work in a way that could lead to returning search results:
In some embodiments, the operations further include: indexing a plurality of web pages using the model to get an indexed plurality of web pages and utilizing the indexed plurality of web pages to provide search results in response to a search query.
The Semantic Frames patent is at:
Semantic frame identification with distributed word representations
Inventors: Dipanjan Das, Kuzman Ganchev, Jason Weston, and Karl Moritz Hermann
Assignee: Google LLC
US Patent: 10,289,952
Granted: May 14, 2019
Filed: January 28, 2016
Abstract
A computer-implemented technique can include receiving, at a server, labeled training data including a plurality of groups of words, each group of words having a predicate word, each word having generic word embeddings. The technique can include extracting, at the server, the plurality of groups of words in a syntactic context of their predicate words. The technique can include concatenating, at the server, the generic word embeddings to create a high dimensional vector space representing features for each word. The technique can include obtaining, at the server, a model having a learned mapping from the high dimensional vector space to a low dimensional vector space and learned embeddings for each possible semantic frame in the low dimensional vector space. The technique can also include outputting, by the server, the storage model, the model can identify a specific semantic frame for an input.
Is Google in a post Semantic Frames time?
Google is continuing research on Semantic Frames, as seen by this recent paper, from April 12, 2019, as well:
A Crowdsourced Frame Disambiguation Corpus with Ambiguity
The abstract for this paper explains why the research behind it was interesting:
Abstract
We present a resource for the task of FrameNet semantic frame disambiguation of over 5,000 word-sentence pairs from the Wikipedia corpus. The annotations use a novel crowdsourcing approach with many workers per sentence to capture inter-annotator disagreement. In contrast to the typical approach of attributing the best single frame to each word, we provide a list of frames with disagreement-based scores that express the confidence with which each frame applies to the word. This is based on the idea that inter-annotator disagreement is at least partly caused by the ambiguity that is inherent to the text and frames. We have found many examples where the semantics of individual frames overlap sufficiently to make them acceptable alternatives for interpreting a sentence. We have argued that ignoring this ambiguity creates an overly arbitrary target for training and evaluating natural language processing systems – if humans cannot agree, why would we expect the correct answer from a machine to be any different? We also utilized an expanded lemma-set provided by the Framester system to process this data, which merges FN with WordNet to enhance coverage. Our dataset includes annotations of 1,000 sentence-word pairs whose lemmas are not part of FN. Finally, we present metrics for evaluating frame disambiguation systems that account for ambiguit
But, we can’t be sure how much effort Google will give to this Semantic Frames approach because other approaches that are worth investigating have also shown up.
An even newer paper that the Semantic Frames one I just linked to, published on May 15, 2019.
BERT Rediscovers the Classical NLP Pipeline
The abstract from the paper:
Abstract:
Pre-trained text encoders have a rapidly advanced state of the art on many NLP tasks. We focus on one such model, BERT, and a quantify where linguistic information is captured within the network. We find that the model represents the steps of the traditional NLP pipeline in an interpretable and localizable way. The regions responsible for each step appear in the expected sequence: POS tagging, parsing, NER, semantic roles, then coreference. Qualitative analysis reveals that the model can and often does adjust this pipeline dynamically, revising lower-level decisions based on disambiguating information from higher-level representations.
I’ve summarized the summary of this patent, but looking at it and what has come after it, it might be worth skipping ahead in time to see some of the other things that Google is working upon. The detailed description of this patent provides more details about how it works. But, one of the inventors of this Semantic Frames patent, and author of the related white paper (Dipanjan Das) is an author of a more recent paper at Google around BERT as well, which appears to be creating a buzz around the Search industry (the classical NLP Pipeline paper I linked to above.) The semantic frames patent is an updated continuation patent for a patent filed on May 7, 2014. Knowing about semantic frames and how they work is helpful, especially understanding how it aims at giving context to words processed.
But there is also BERT, which is worth looking at, and how it pre-trains text, too:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT is at Github: https://github.com/google-research/bert
So, understanding how Google is doing natural language processing can be helpful and the role that Semantic Frames could play in doing that, but it appears to be something that BERT can do too.