





Entity Normalization As Part of Google’s Knowledge Graph
Published: March 08, 2019
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

Entity Normalization Was Developed as Part of Google’s Annotation Framework
Googlebot crawls the web and collects information about facts it finds. It started doing this as part of a project at Google under the name, the Annotation Framework, for Google’s Fact Repository, which was the precursor to Google’s Knowledge Graph. Some of the ideas that came from the Fact Repository still have value under today’s Knowledge Graph.
Related Content:
A patent granted to Google this week was a continuation patent, updating an earlier granted patent about how Google collects information about facts, and how it handles “duplicate facts in an object collection,” or Entity Normalization.
This updated patent tells us about the problem it was intended to solve in these words:
Data is often organized as large collections of objects. When objects are added over time, there are often problems with data duplication. For example, a collection may include multiple objects that represent the same entity. As used herein, the term “duplicate objects” refers to objects representing the same entity. The names used to describe the represented entity are not necessarily the same among the duplicate objects.
Duplicate objects are undesirable for many reasons. They increase storage costs and take a longer time to process. They lead to inaccurate results, such as an inaccurate count of distinct objects. They also cause data inconsistency.
Sometimes, unique identifiers can help a search engine distinguish between objects that share the same name. For instance, Books have ISBNs, and people have social security numbers, and if the names match, but those numbers don’t, they might not be duplicates even though they share a name. This is a conventional approach to identifying duplicate objects and distinguishing when they aren’t duplicates. The patent points out problems with conventional approaches:
One drawback of the conventional approaches is that they are only effective for specific types of objects and tend to be ineffective when applied to a collection of objects with different types. Also, even if the objects in the collection are of the same type, these approaches tend to be ineffective when the objects include incomplete or inaccurate information.
The problem that this entity normalization patent is intended to resolve is: “a method and system that identifies duplicate objects in a large number of objects having different types and/or incomplete information.”
The process invented in the patent addresses this problem by:
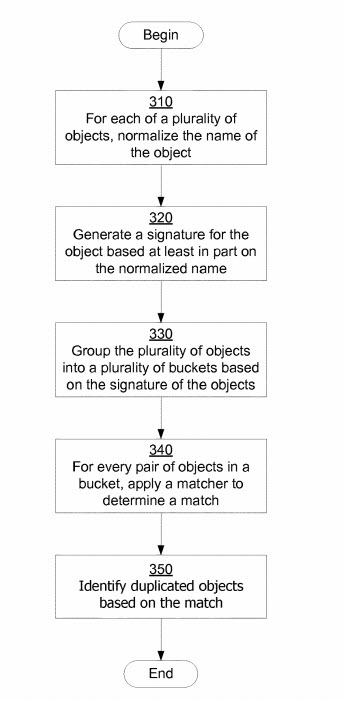
…identifying duplicate objects from a plurality of objects. For each object, the name used to describe the represented entity is normalized. A signature is generated for each object based on the normalized name. Objects are grouped into buckets based on the signature of the objects. Objects within the same bucket are compared to each other using a matcher to identify duplicate objects. The matcher can be selected from a collection of matches.
In a little more detail, and using some terms that we’ve seen more frequently from Google:
This approach normalizes names used by objects to describe the represented entity. Therefore, objects representing the same entity share the same normalized name. As a result, this approach can identify duplicate objects even if the associated names are initially different. This approach is also computationally cost-efficient because objects are pair-wise matched only within a bucket, rather than being pair-wise matched across all buckets.
This updated continuation patent about Entity Normalization is:
Entity normalization via name normalization
Inventors: Jonathan T. Betz
Assignee: Google LLC
US Patent: 10,223,406
Granted: March 5, 2019
Filed: June 29, 2017
Abstract
Systems and methods for normalizing entities via name normalization are disclosed. In some implementations, a computer-implemented method of identifying duplicate objects in a plurality of objects is provided. Each object in the plurality of objects is associated with one or more facts, and each of the one or more facts having a value. The method includes: using a computer processor to perform: associating facts extracted from web documents with a plurality of objects; and for each of the plurality of objects, normalizing the value of a name fact, the name fact being among one or more facts associated with the object; processing the plurality of objects following the normalized value of the name facts of the plurality of objects. In some implementations, normalizing the value of the name fact is optionally carried out by applying a group of normalization rules to the value of the name fact.
The earliest version of this patent was filed in 2006, under the name Entity normalization via name normalization Sometimes Continuation patents have the same description as the original version but have updated claims. This one appears to have also updated the description as well. The abstract for the original is shorter than the abstract above. The original abstract:
A system and method identifying duplicate objects from a plurality of objects. The system and method normalizes name values of objects, groups objects into buckets based at least in part on the normalized name values, matches objects within the same bucket based on a selected matcher, and identifies the matching objects as duplicate objects.
Andrew Hogue. The head of the annotation framework, which was a project that this patent was part of, had a Google talk in 2011 that describes the focus of the team he was working with. The video is called, “The Structured Search Engine,” and if you watch it, you will get some insights into projects that came before and influenced the knowledge graph at Google. The video is:
Google’s Annotation Framework
Andrew Hogue left Google to join Foursquare, and his resume was posted online. In his resume, he indicated that he was in charge of a Google project known as the Annotation Framework. The description of that position made it look like he was supervising several search engineers who were researching what appeared to be the following patents, one of which is named “annotation framework,” and a couple which mentions a “fact repository,” which sounds very much like a precursor to Google’s Knowledge Graph. Hogue was also responsible for onboarding technology from the acquisition of Metaweb, and their freebase project, which sounds like it was very similar in many ways to what the annotation framework was doing. This patent lists many of the related patents that came out along with this one, and those taken together provide some insights into what the annotation framework covered. For instance, the very first one, titled “Generating Structured Information,” tells us about how information for local entities might be collected for something like Google Maps. This list of patents doesn’t disclose what this patent about Entity Normalization covers, but does a good job of explaining why it covers what it does. I’ve linked to the ones listed in case you are curious about these related patents.
This patent application potentially relates to the following U.S. Applications, which are part of that annotation framework:
1) Generating Structured Information
2) Support for Object Search
3) Data Object Visualization
4) Data Object Visualization Using Maps
5) Query Language
6) Automatic Object Reference Identification and Linking in a Browseable Fact Repository
7) Browseable Fact Repository
8) ID Persistence Through Normalization
9) Annotation Framework
10) Object Categorization for Information Extraction
11) Modular Architecture for Entity Normalization
12) Attribute Entropy as a Signal in Object Normalization
13) Designating Data Objects for Analysis
14) Data Object Visualization Using Graphs
15) Determining Document Subject by Using Title and Anchor Text of Related Documents
16) Anchor Text Summarization for Corroboration
17) Unsupervised Extraction of Facts
Those aren’t the only related patents in the Annotation Framework, and others cover similar topics and share inventors which could be said to be related. One that I wrote about in 2014 (when it was granted), I described in a post with the name Extracting Facts for Entities from Sources such as Wikipedia Titles and Infoboxes
That post covers a lot of the same technology that is described in this post describing how Google might do entity normalization by identifying entities on pages at places such as at a knowledge base like Wikipedia and using data janitors to perform what Google refers to as normalization of entities. We see similar language in this patent as well:
Janitors operate to process facts extracted by importers. This processing can include but is not limited to, data cleansing, object merging, and fact induction. In one embodiment, many different janitors perform different types of data management operations on the facts. For example, one janitor may traverse some set of facts in the repository to find duplicate facts (that is, facts that convey the same factual information) and merge them. Another janitor may also normalize facts into standard formats. Another janitor may also remove unwanted facts from the repository, such as facts related to pornographic content. Other types of janitors may be implemented, depending on the desired types of data management functions desired, such as translation, compression, spelling or grammar correction, and the like.
Entity Normalization and Normalizing Names
This patent specifically focuses upon the normalization of facts and names, and we are told that very clearly here:
Various janitors act on facts to normalize attribute names, and values and delete duplicate and near-duplicate facts, so an object does not have redundant information. For example, we might find on one page that Britney Spears’ birthday is “Dec. 2, 1981” while on another page that her date of birth is “Dec. 2, 1981.” Birthday and Date of Birth might both be rewritten as Birthdate by one janitor, and then another janitor might notice that Dec. 2, 1981, and Dec. 2, 1981, are different forms of the same date. It would choose the preferred form, remove the other fact, and combine the source lists for the two facts. As a result, when you look at the source pages for this fact, on some, you’ll find an exact match of the fact, and on others, text that is considered to be synonymous with the fact.
I’ve written about Machine IDs involving entities when I wrote about Google’s Acquisition of MetaWeb, in 2010 in the post, “Google Gets Smarter with Named Entities: Acquires MetaWeb.” At the start of that post, I describe how a string of letters and numbers might track Arnold Schwarzenegger to identify him. This Google Patent, originally filed in 2007, talks about an object ID that sounds very similar:
Repository contains one or more facts. In one embodiment, each fact is associated with exactly one object. One implementation for this association includes in each fact an object ID that uniquely identifies the object of the association. In this manner, any number of facts may be associated with an individual object, by including the object ID for that object in the facts. In one embodiment, objects themselves are not physically stored in the repository, but rather are defined by the set or group of facts with the same associated object ID, as described below. Further details about facts in the repository are described below, about FIGS. 2(a)-2(d).
So MetaWeb refers to these IDs as Machine IDs, and the Annotation Framework refers to them as Object IDs. This particular patent lets us understand better how entities are related to such object IDs. This section provides a couple of examples, using Spain and the USPTO, and how different names for each of those entities might be associated with an Object ID for each of them:
Some embodiments include one or more specialized facts, such as a name fact and a property fact. A name fact is a fact that conveys a name for the entity or concept represented by the object ID. A name fact includes an attribute of “name” and a value, which is the object’s name. For example, for an object representing the country Spain, a name fact would have the value “Spain.” A name fact, being a special instance of a general fact, includes the same fields as any other fact; it has an attribute, a value, a fact ID, metrics, sources, etc. The attribute of a name fact indicates that the fact is a name fact, and the value is the actual name. The name may be a string of characters. An object ID may have one or more associated name facts, as many entities or concepts can have more than one name. For example, an object ID representing Spain may have associated name facts conveying the country’s common name “Spain” and the official name “Kingdom of Spain.” As another example, an object ID representing the U.S. Patent and Trademark Office may have associated name facts conveying the agency’s acronyms “PTO” and “USPTO” as well as the official name “United States Patent and Trademark Office.” If an object does have more than one associated name fact, one of the name facts may be designated as a primary name, and other name facts may be designated as secondary names, either implicitly or explicitly.
Machine IDs or Object IDs
Specific facts about an entity are associated with a specific ID for that entity. This may be helpful to Google when it might try to use facts to answer queries. The abstract for the “Annotation Framework patent tells us:
A fact repository contains facts having attributes and values and further having associated annotations, which are used, among other things, to vet facts in the repository and which can be returned in response to a query.
An Entity that is associated with an Object ID may have multiple names associated with it. The patent tells us that an entity that is a duplicate with different names may be identified as relating to the same object. And this is true with the entities that MetaWeb was indexing in its Freebase Directory, so Arnold Schwarzenegger, who is also played the Kindergarten Cop and the Terminator, is recognized by the search engine as being the same entity.
Google might see the text on pages that stand for entities, and recognize those entities, and attributes for the entities, and relationships between the entities, and classes for them, as I recently described in the post Google Shows Us How It Uses Entity Extractions for Knowledge Graphs. As Google extracts entities, it sees if it recognizes those entities as ones it may have seen before, and if it does, and can associate them with an ID, it may do so as part of the process described in this patent.
I haven’t seen Google refer to Machine IDs or Object IDs much when it comes to Entities, and I have been referring to those as Machine IDs. Using IDs like this allows Google to track entities better.
Google refers to these IDS being used in Reverse Image Searches in their Blog post, Improving Photo Search: A Step Across the Semantic Gap. They describe what those IDs look like in that post, and they sound very similar to what we see for entities linked to at Google Trends, and the IDs for entities that appear in the Google Knowledge Graph. We saw these in the same format for IDs in Freebase, so I’m likely to refer to them as Machine IDs. But, interestingly, the idea behind them seems very similar to the Object IDs from this patent.