


Natural Language Queries in Spreadsheets at Google
Published: May 12, 2021
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

Answering Natural Language Queries From Spreadsheets
Imagine a site owner shares information on the web using spreadsheets or databases. I wrote a related post at Natural Language Query Responses. We see Google with patents focused on answering natural language queries using data tables. Today’s blog post is about answering questions about spreadsheets or databases written using natural language.
A searcher may want to access that information combined in many ways. This is something that Google has patented. I will go over this patent granted in May 2021 and what it says.
Related Content:
How The Search Engine Might Make It Easier For a Searcher to Use Data Tables in Spreadsheets
The patent starts with data tables in spreadsheets and then shows how the search engine might make it easier for a searcher to use that information.
A spreadsheet is a data document that includes one or more data tables storing data under different categories.
Sometimes the spreadsheet may perform calculation functions. For example, a searcher may want certain data from the spreadsheet. The searcher can then construct a database search query to look for the desired data they want.
Sometimes, the spreadsheet may not store the searcher-desired data set. The searcher may use available data from the spreadsheet to derive the desired data.
The searcher may review the spreadsheet identifying relevant data entries in the spreadsheet to compile a formula using the calculation function associated with the spreadsheet to calculate the result.
For example, when the spreadsheet records a test score for each student in a class, a searcher may want to know the average score of the class.
Then the searcher may need to compile a formula by summing the test scores and then dividing by the number of students to find the average score of the class.
The data table may then calculate the average score of the class based on the compiled formula.
Thus the searcher may need to compile a formula and input it into the data table for calculation. That may be inefficient when processing a large amount of data. It also requires a high level of knowledge of database operations from the searcher.
The Patent Covers Systems and Methods to Process Natural Language Queries on Data Tables
This granted patent covers systems and methods to process natural language queries on data tables, such as spreadsheets.
According to the patent, natural language queries may originate from a searcher.
A natural language query may find a query term and a grid range from a data table relevant to the query term.
A table summary may include data entities based on the grid range.
A logic operation may then apply to the number of data entities to derive the query term.
The logic operation may change into a formula executable on the data table. Finally, you can apply the formula to the data table to generate a result in response to the natural language query.
Natural language queries can go through a searcher interface at a computer or manually or vocally entered by a searcher.
Those queries can also go to servers from computers through HTTP requests.
Those Natural Language Queries Can Originate In a First Language
Natural language queries can originate in a first language (e.g., non-English, etc.) and then be translated into a second language, e.g., English, for processing.
A grid range at a computer when the data table is not the computer or a server after receiving the natural language query when the data table is at the server.
The data table includes any data table stored at a computer, a remote server, or a cloud.
The number of data entities includes any of dimensions, dimension filters, and metrics.
The result gets seen by a searcher via a visualization format, including any answer statement, a chart, or a data plot.
The search engine may get searcher feedback after the result gets provided to the searcher. For example, the formula gets associated with the natural language query or the query term when the searcher feedback is positive.
When the searcher feedback is negative, an alternative interpretation of natural language queries may be provided. Alternative results may be provided based on the alternative interpretation.
The Patent for Processing a Natural Language Query in Data Tables
Systems and methods for processing a natural language query in data tables
Inventors: Nikunj Agrawal, Mukund Sundararajan, Shrikant Ravindra Shanbhag, Kedar Dhamdhere, McCurley Garima, Kevin Snow, Rohit Ananthakrishna, Daniel Adam Gundrum, Juyun June Song, and Rifat Ralfi Nahmias
Assignee: Google LLC
US Patent: 10,997,227
Granted: May 4, 2021
Filed: January 18, 2017
Abstract
Systems and methods disclosed herein for processing a natural language query on data tables.
According to some embodiments, a natural language query may come from a searcher via a searcher interface.
The natural language query may obtain a query term, and a grid range may show a data table as relevant to the query term.
A table summary may include many data entities based on the grid range.
A logic operation may apply to the plurality of data entities to derive the query term.
The logic operation may translate into a formula executable on the data table. The formula applied to the data table will generate a result in response to the natural language query.
To provide an overall understanding of the disclosure, certain illustrative embodiments will include systems and methods for connecting with remote databases.
In particular, there is a connection between an application and a remote database.
The application modifies the data format imported from the remote database before displaying the modified data to the searcher.
But, a person of ordinary skill in the art that the systems and methods described herein may get adapted and modified as is appropriate for the application and the systems and methods described herein may get used in other suitable applications, and that such other additions and modifications will not depart from the scope thereof.
Generally, the computerized systems described herein may comprise one or more engines. Those will include a processing device or devices, such as a computer, microprocessor, logic device, or other device or processor that works with hardware, firmware, and software to carry out one or more of the computerized methods described herein.
A Searcher Can Enter a Query For Data in Natural Language
Systems and methods for processing a natural language query allow a searcher to enter a query for data in natural language.
The natural language query may translate into a structured database query. When the structured database query indicates the data is not readily available in the data table, existing data entries may identify in the data table that may be relevant to generate the desired data. Then, the formula may be automatically compiled to derive the desired data based on the available data entries.
For example, when the data source includes a spreadsheet that records a test score for each student in a class, a searcher may input a natural language query. That might be, “what is the average score of the class?”
The natural language query may be interpreted and get parsed by extracting terms from the query, such as “what,” “is,” “the,” “average,” “score,” “of,” “the,” and “class.”
Among the extracted terms, the term “average score” may be a key term of the query based on previously stored key terms that are commonly used.
It may then be seen that no data entry is available in the spreadsheet corresponding to the data category “average score,” e.g., no column header corresponds to “average score.”
Logic may derive an “average score” from the existing data entries.
For example, an “average score” may work, to sum up, all the class test scores and divide the sum by the total number of students.
A formula may then be automatically generated to calculate the “average score” and output the calculation result to the searcher in response to the natural language query.
The generated formula may work in association with a tag “average score” such that even when the spreadsheet updates with more data entries, e.g., with new test scores associated with additional students, the formula may still be applicable to automatically calculate an average score of the class, in response to the natural language query.
How A Searcher May Get an Answer About Their Data
A searcher may get an answer about their data faster and more efficiently than by manually entering formulas or doing other forms of analysis by hand.
For searchers who may not know all the spreadsheet features, the platform may help the searcher generate structured queries or even formulas.
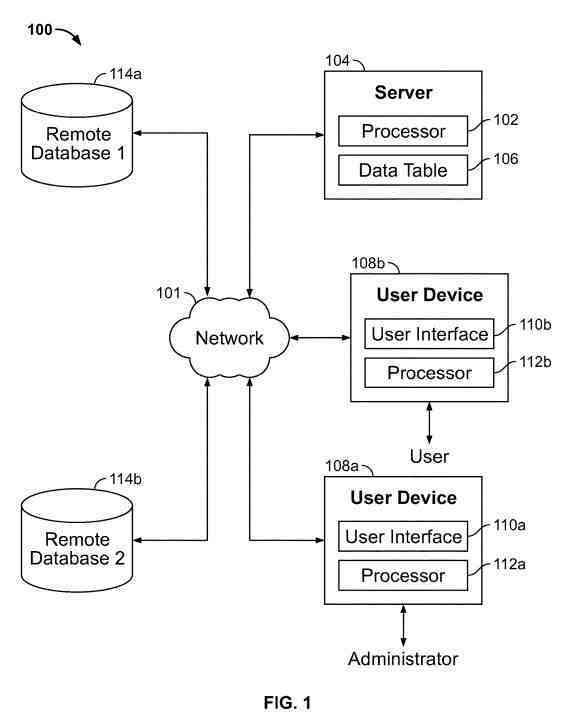
The system includes a server, two remote databases (generally referred to as a remote database), searcher devices (generally referred to as a searcher device), and/or other related entities that communicate with one another over a network. The searcher devices contain searcher interfaces (generally referred to as searcher interfaces) respectively.
Each searcher device includes a device such as a personal computer, a laptop computer, a tablet, a smartphone, a personal digital assistant, or any other suitable type of computer or communication device.
Searchers at the searcher device access and receive information from the server and remote databases over the network.
The searcher device may include components, such as an input device and an output device.
How The Searcher Device Works
A searcher may operate the searcher device to input a natural language query via the searcher interface, and the processor may process the natural language query.
The searcher device may process the natural language query and search within a local database.
Also, The searcher device may send the natural language query to a remote server storing data tables and using a processor to analyze the natural language query.
The server may provide updates and may access remote databases a-b for a data query.
Thus, when a natural language query is received at the searcher device, upon translation of the query into a database query, the database query may be performed locally at the searcher device, at the data tables stored at the server, or at the remote databases (e.g., cloud, etc.).
And, the searcher device may have a locally installed spreadsheet application for a searcher to review data and enter a natural language query.
Aspects of Processing Natural Language Queries Using Spreadsheets
Natural language queries go through a searcher interface.
Natural language queries may be questions from searchers such as the growth of monthly total sales” “what is the average score of MATH 301.,”
Natural language queries may be input by a searcher with input devices or articulated by a searcher using a microphone through the searcher device.
Natural language queries may come from an analytics application and go through to the server via an application programming interface (API) from another program.
For example, a business analytics software may include a list of business analytics questions such as “how’s the growth of monthly total sales” in a natural language. Then, the question may go to the server.
Natural language queries may originate in many different natural languages. It may translate into a language compatible with the platform (e.g., the operating system, or the natural language query processing tool, and/or the like), such as English, etc.
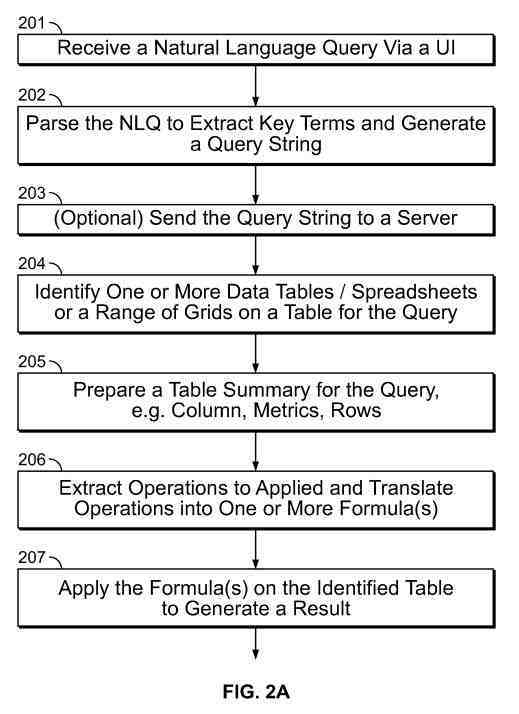
Natural language queries may extract key terms, and generate a query string.
The parsing may happen at the searcher device.
The server may receive a parse request over HTTP from the searcher device.
The server may send a request to an analytics module.
An Example Answer to a Natural Language Question
For example, for a natural language question, “what is the monthly growth of sales,” extracted words in the question may get assessed to rule out words such as “what,” “is,” “the,” “of,” etc. as meaningful query terms.
Words such as “monthly growth” and “sales” may query terms based on previously stored query term rules and/or heuristics from previously processed queries.
The query string may optionally go to the server. Alternatively, natural language queries may work within one or more spreadsheets that are locally stored on the searcher device.
One or more data tables or spreadsheets, or a grid range of a spreadsheet, may be relevant to the query string.
A table detection module may output tables detected from originally stored data tables or spreadsheets, e.g., based on heuristics or machine learning. For example, natural language key terms from the query string may identify relevant data tables/spreadsheets.
When the query string includes key terms such as “growth,” “monthly,” “sales,” data tables/spreadsheets that have a column or a row recording may identify monthly sales.
Data Tables/Spreadsheets Could Also Work Based on Previously Used Data Tables for Similar Query Strings,
As another example, data tables/spreadsheets could also work based on previously used data tables for similar query strings, e.g., when a natural language query “what is the monthly distribution of sales” identified a certain data table, the same data table may be for the query “how’s the growth of monthly total sales” as well.
The selected range of cells from the data table may change in orientation if necessary.
The searcher may manually select the cells by selecting a single cell or a range of cells that may belong to a table.
The cells surrounding the selection could have possible table structures.
A table schema may work with the selected range of cells.
Sometimes when the whole table schema is too small, to avoid communication of a large number of small messages from the computer to the server and improve communication efficiency, several table schemas may be in a batch request to the server.
When the identified table is too large to include in an XMLHttpRequest (XHR) request, the searcher device may only send the grid range of the detected table (for chart recommendations), and the server may determine a table structure from the sent grid range.
The server may prepare a table summary by extracting the dimensions, columns, rows, metrics, dimension filters, and/or other characteristics of the detected data table and map the extracted table characteristics to cell ranges or addresses in a spreadsheet.
For example, for a data table recording monthly sales data of the year, the table summary may include the number and index of rows and columns, the corresponding value in a cell identified by the row and column number, the metric of the value, and/or the like.
The server may extract operations to the data table and translate the operations into one or more formulas executable on the data table.
The server may send the formula(s) back to the searcher device. The formula(s) may be in the detected data table to generate a result in response to a natural language query.
In some implementations, the generated result may get a different visualization, such as, but not limited to, a pie chart, a data plot, and/or the like.
Feedback on a Data Tables Result
When the searcher receives the result in response to the original question via a searcher interface, the searcher may provide feedback on the result.
For example, the searcher may provide a positive rating if the result is accurate.
Or, the searcher may submit a negative rating when the result is unsatisfactory, e.g., misinterpreting the question, insufficient data, etc.
When the searcher feedback is positive, the server may save the formula building objects such as the table summary and formula(s) associated with the query string for machine learning purposes. The formula may be a reference with similar questions.
When the searcher feedback is negative, the server may disassociate the formula-building objects with the question. When similar questions get received, such questions are not interpreted in the same way.
The server may optionally obtain further information from the searcher’s feedback on the result.
For example, if the searcher asks, “how’s the monthly growth of sales,” and a result of the monthly increase from last month to the current month is, although, still. Still, the searcher submits negative feedback. The searcher interface may prompt the searcher to provide further information.
The searcher may re-enter the question with a time period “how’s the monthly growth of sales from ______ to ______?” Or the searcher interface may prompt the searcher to confirm whether the identified data entities “monthly growth” and “sales” are accurate.
Another example is that the searcher interface may provide suggested queries to the searcher if the server fails to parse and identify what the natural language query is.
Other additional methods may work for the searcher to provide further detailed feedback to refine the question.
The server may provide an alternative interpretation of the query string based on information obtained and generate an alternative formula using the alternative table summary.
Then the server may proceed to provide the updated result to the searcher.
Data Flows between the Client-Side and the Server-Side to Process Data Tables Natural Language Queries
A searcher interface may present an answer panel, which may post a query request to a backend.
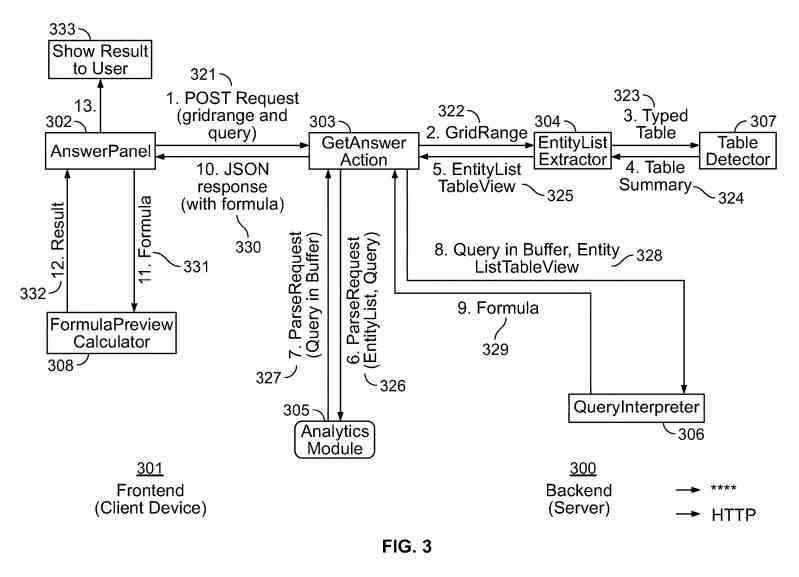
The query may include a query string (e.g., the question asked by a searcher, or key terms extracted from the original natural language question asked by the searcher, etc.), a list of data entities (e.g., table schema generated based on key terms from the query string, etc.), a grid range from an existing data table, or the like.
The backend server may run using a java environment. It may pass the query request to a series of modules such as a get-answer action module, an entity list extractor, an analytics module, a query interpreter, a table detector, or the like.
The get-answer action module may act as a communication interface receiving the client request, which may include query parameters such as a query string (e.g., the question asked by the searcher, etc.), a grid range of the data table detected in and around cell selection, or the like.
If the request has reached the server, the grid range may contain a constructed table. If a data table is not detected or the selected grid range contains any data, the answer panel interface may not go to a searcher initially.
The get-answer action module may send the grid range information to the entity list extractor to get a table view of the data entity list based on the grid range information, e.g., a sub-table with columns rows defining relevant data entities.
How The entity List Extractor May Construct a Table Schema
The entity list extractor may construct a table schema, e.g., a data entity list including data entities relevant to the query.
The entity list extractor may get a table summary (e.g., including column headers, data types, labels column, cell metrics, and/or other properties) from the table detector.
The entity list extractor may also build a typed table from the grid range and pass it on to the table detector for summarization.
The entity list extractor may provide a table view that represents the data entity list.
The entity list may be in a data structure as a per-table knowledge graph, represented by graph nodes such as but not limited to dimensions, dimension filters, metrics, and/or the like.
Dimensions may include the header of a column whose values act as row keys (or labels) into the table.
For example, “Country” will be a dimension in a table with country names as labels or row keys).
Dimension filters may include values in the dimension column (row keys/label column).
For example, “India” “U.S.A” is the dimension filters for the dimension “Country.” Metrics may include all number columns taken as metrics or column values.
Generally, a searcher may look for metrics for a particular dimension filter (or label). For example, in the string “Population of India,” “Population” is a metric, and the dimension filter is “India” for dimension “Country.”
The entity list extractor may provide an entity list table view to the get-answer action module.
The entity list table view may extract metrics, dimensions, and dimension filters from the table summary.
For example, all column headers that correspond to cells with numeric values are metrics (e.g., a column header “population” is a metric as in the above example), all string and date/time column headers are dimensions (e.g., a column header “country,” a text string, is a dimension).
The values in these dimension columns are dimension filters (e.g., values under the column header “country” such as “The U.S.A.,” “India,” etc., are dimension filters).
How Metrics, Dimensions, and Dimension Filters Can be Applied
Other determinations of the metrics, dimensions, and dimension filters can be applied.
In addition, the entity list table view may serve to reverse lookup row and column indices given a dimension, metric, or dimension filter string, which may map parameters such as dimensions, metrics, dimension filters back to the grid row, and column indices during formula construction.
To allow this, the entity list table view may provide a metrics-to-column number map, a dimensions-to-column number map, and a dimension-filters-to-row-and-column pair map.
The table detector may extract information from a data table and generate a table summary, determining what entities in the table can generate a formula to derive the query term.
Tables can be generally represented as a common object, which stores the data in a table, the column headers and types of data in the columns, and derived facts about the data.
The table detector may extract information from a data table in several steps.
First, light parsing of cells and inference of column headers and data types may be performed.
For cells with numeric values between 1900 and 2100, the cells may be years instead of pure numeric values.
The table detector may then filter out spurious rows and columns, including but not limited to empty rows/columns, numeric columns with ID numbers, columns for taking notes, and/or the like.
The table detector may then add column-based statistics.
For example, for all column types, the number of missing or distinct values may be tracked.
The number of negative/positive/floats/zero values and the sum, standard deviation, monotonicity, and uniformity of the array may be recorded.
The table object created from the input table cell values from the data table may create an aggregate table.
Each column in the aggregate table may determine the number of unique values compared to the total values (e.g., the range of data values).
If the column is categorical (e.g., when the unique values in the column are a subset of the entire spectrum of data values), then the column may create an aggregated table.
For each categorical column, two aggregated objects may associate with the column.
A new “count” aggregated object may record information relating to the “count” of a unique value.
For example, each row of the object may represent a unique value. In each row, the first cell stores the unique value, and the second cell records the number of times that the respective unique value appears in the original categorical column.
A new “sum” aggregated object may record the total sum of each unique value in the original table.
For example, each row of the object represents a unique value, and each column of the object represents a categorical numeric column in the original table.
The value in each cell of the object represents a sum of unique values of all cells in the respective categorical column that contain the respective unique value (based on the respective row of the object).
The “count” and “sum” objects may be examples of objects for aggregation.
Or, average aggregation objects may use the count and sum of each unique value and may carry information from the original data table.
A Parse Requiest Sent From a Get Answer Action Module
The get-answer action module may also send a parse request, including data entity list information and query information, to the analytics module, generating a parse response.
The parse response may include a structured data table/spreadsheet query represented as the query in the protocol buffer.
The query interpreter may interpret returned query response to an executable formula string using the entity list table view passed on from the get-answer action module.
The query interpreter may include various comparable classes for formula builder, e.g., a particular formula builder may correspond to one type of formula.
Here a given set and count of fields in the query may correspond to only one formula, e.g., a query with exactly two metrics corresponds to a correlation formula.
For example, the query interpreter may invoke a variety of operations.
A Query Scoring Operation May be from an Example Operation
An example operation includes a query scoring operation, e.g., score query (the query in the protocol buffer), which returns a score, built by counting the number of fields of the input query in the protocol buffer it can consume, or returns a negative/zero score if the fields in the query in the protocol buffer are not enough to build a formula.
For example, if the input query in the protocol buffer having two-dimension filters and a dimension goes to a formula builder that requires at least one dimension filter and at least one dimension, the scoreQuery( ) operator may return a score of two. This would be one point for satisfying the at least one dimension need and one point for satisfying the at least one dimension filter need).
The two (non-zero scores) state that the parameters included in the query in the protocol buffer are enough for formula building.
A given query may have more than one formula builder that may return the same score. If another formula builder requires just two-dimension filters, the input query in the protocol buffer in the above example would have a score of two with this formula builder.
The query interpreter may then run a getFormula (query in the protocol buffer, EntityListTableView) operation, based on the input of the query and the entity list table view.
After determining that a query score is a positive number, the query interpreter may return a formula built by joining data in the input values query in the protocol buffer and EntityListTableView.
The Query Interpreter
The query interpreter may take in a list of formula builders available (injected) and may interpret the input query in the protocol buffer by first scoring each formula builder by the number of fields of the input query in the protocol buffer may consume.
This may filter out a set of formula builders that cannot understand the input query in the protocol buffer.
If there is at least one formula builder with a positive score in response to the input query in the protocol buffer, the formula builder with the highest score may map a formula.
In this way, the formula builder that consumes the maximum number of fields from the input query in the protocol buffer can construct the possible formula parses.
The query interpreter may be a class with many smaller formula builders plugged into it.
In this way, the query interpreter structure can be expandable with more formula builders.
When a different type of query gets returned, a new formula type can add to the formula builders without changing the existing formula builder.
When the get-answer action module receives a formula from the query interpreter, a JSON response including the formula may return the answer panel at the frontend (e.g., at the client-side).
The answer panel may then provide the formula to a formula preview calculator. That may, in turn, generate a result based on the formula. The answer panel may then provide the result to the searcher.
A Searcher Interface Diagram Showing the Answer Panel to Data Tables Natural Language Queries
An example mobile interface may show example mobile screens of the answer panel.
The answer panel may have an interface on a desktop computer. Such as a browser-based application.
A searcher can type a natural language question in the query box, e.g., “how’s the growth of monthly totals?”
The query box may show a query suggestion in response to the searcher entered question to help searchers better understand how to structure their own questions using precise terms.
The question intake at the query box may also automatically complete or correct typographical mistakes from the searcher-entered question. Besides, the data entities for the query can be auto-completed.
The query may display the same colors with relevant sections in a spreadsheet to show how key terms in the query relate to sections in the spreadsheet.
An answer may show, e.g., a statement containing a calculated result of the “monthly total.”
The answer may include a human-friendly interpretation of the answer in natural language, e.g., “for every week, monthly total increases by,” and the calculated result, “$1,500.”
The query “how’s the growth of monthly totals” may take various visualization formats.
For example, the generation of a chart may show different data plots over a period of time. For example, the monthly totals, commission income, sales of product and service income, etc., as related to the query question “growth of monthly total.”
The answer panel may further provide analytics of the data plots.
The answer screen may include a rating button, a “like” or “dislike” button, or a “thumbs up” or “thumbs down” button for the searcher to provide feedback to the answer to the original question asked.