





applications mobile
A Native Application Vertical Search Engine at Google
Published: May 19, 2020
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url
Google was granted a patent last week that is about a search engine that can do keyword searches (or find an entity) for an application vertical search engine on mobile devices that can cover such things as:
- (i) Personal content such as contacts, messages, call history, documents, notes, calendar events, or the like
- (ii) Application-specific content that is provided by the application for user consumption
- (iii) Application-specific content that is provided by the application and is responsive to user interaction, or
- (iv) A combination thereof
The patent tells us that such a search engine might:
…cluster application content items into one or more different groups such as a topic, task, or the like that can be provided in response to a search query
That kind of clustering is what we see at Google News, where articles tend to be clustered around specific topics.
Related Content:
This sounds like it could be a new vertical search at Google, much like Google has organized results into separate vertical searches such as Maps, News, Images, Videos, Finance, Scholar. We have also seen Google combine different vertical search results into an “All” category such as seen in Universal Search results.
Google has set up search results for different types of vertical searches differently, and this patent tells us that an Application verticle search engine may be set up differently as well. It might have controls that are based upon applications and may be organized by application type, and topics or tasks that are associated with each of the native applications.
Here is how the patent describes how such an application vertical search might display results:
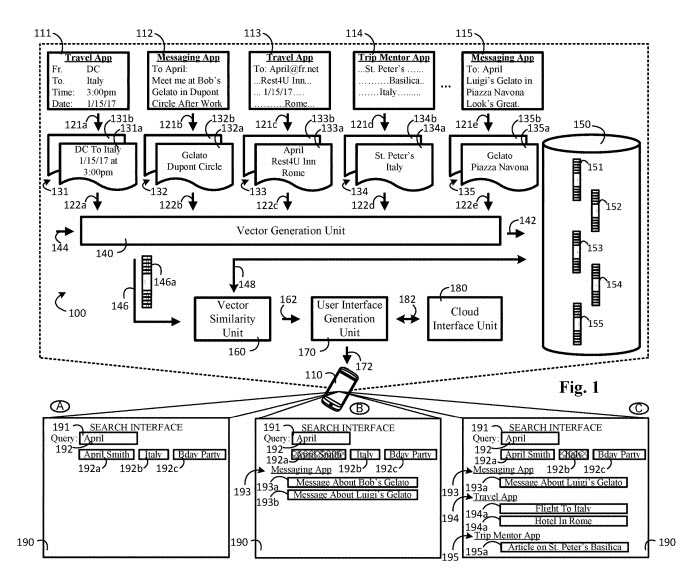
The method may include actions of receiving, by a search engine implemented on a user device and for each of multiple native applications on the user device, a set of data that is generated by the native application and that includes
(i) native application content, and
(ii) context information associated with the native application content, for each set of data that is generated by the native applications, generating, by the search engine implemented on the user device, a cluster feature-vector representation based on the set of data, storing, by the search engine implemented on the user device, the cluster feature-vector representations in a search engine index on the user device, identifying, by the search engine implemented on the user device, a set of cluster feature-vector representations that are associated with a particular feature-vector representation, identifying, by the search engine implemented on the user device, one or more topics or tasks that are associated with the set of cluster feature-vector representations, and providing, for output, a user interface including a selectable control that identifies one or more of the topics or tasks.
This patent can be found at:
Search engine
Inventors: Timo Mertens and Maxim Gubin
Assignee: Google LLC
US Patent: 10,650,068
Granted: May 12, 2020
Filed: January 9, 2017
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for using a search engine implemented on a user device to identify topics or tasks associated with native application content. The method may include actions of receiving a set of data that is generated by the native application and that includes (i) native application content, and (ii) context information associated with the native application content, generating a cluster feature-vector representation based on the set of data, storing the cluster feature-vector representations in a search engine index on the user device, identifying a set of cluster feature-vector representations that are associated with a particular feature-vector representation, identifying one or more tasks that are associated with the set of cluster feature-vector representations, and providing, for output, a user interface including a selectable control that identifies one or more of the tasks.
What an Application Vertical Search Engine Covers
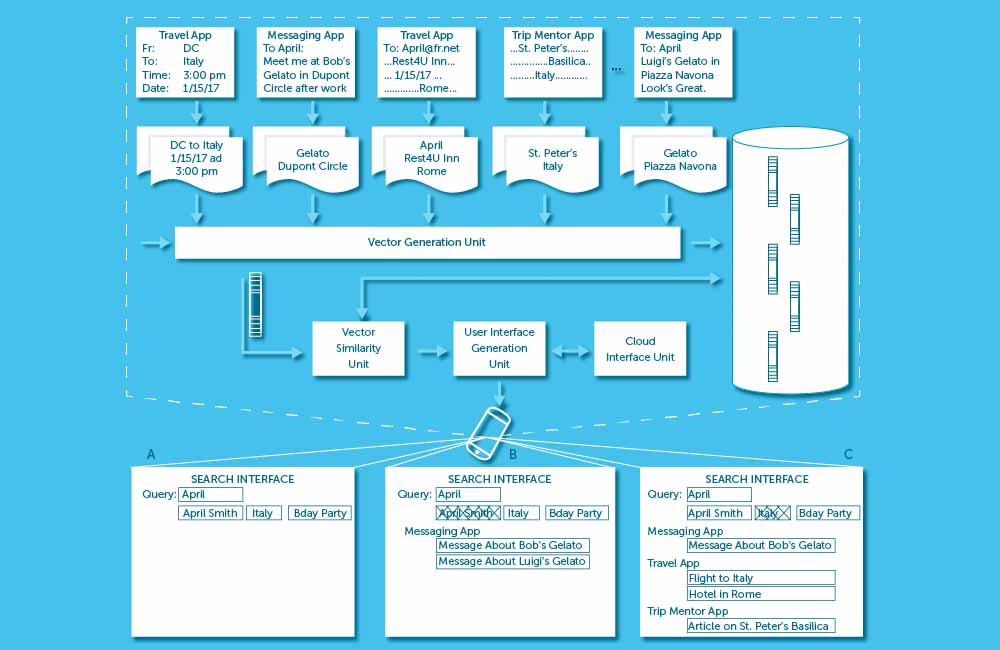
The patent lists a number of the different types of native applications that this vertical search engine might cover, including the following mobile applications:
- Travel application
- Messaging application
- Trip mentor application
- Calendar application
- Document processing application
- Contacts application
- Voice calling application
- Notes application
- Encyclopedia application
- The like
Data Found in a Native Application Vertical Search Engine
The patent points out that every native application will generate respective sets of Data, and provides at least one detailed example. These data sets are generated based on user interactions with native applications.
This is an example:
The sets of data may include native application content and context information. For example, a user may interact with the travel app to book an airline ticket from Washington, D.C. to Italy that is scheduled to depart on Jan. 15, 2017 at 3:00 pm. Based on this user interaction, the native application may generate a set of data that includes native application content such as native application content that was interacted with by the user. In this instance, the trip origin (e.g., DC), the trip destination (e.g., Italy), the trip departure date (e.g., Jan. 15, 2017), and the trip departure time (e.g., 3:00 pm) each individually, or together, are examples of one or more native application content items that were interacted with by the user, as the user-created the aforementioned application content. Other forms of user interaction with native application content items may include a user editing native application content, a user viewing native application content, a user hearing native application content, or the like. The search engine may extract one or more features from the native application content to generate a cluster feature-vector that represents the user’s interaction or consumption of one or more native application content items.
In addition to this large amount of data from user interactions, the search engine will collect and include data taken from a user profile for the person interacting with the native application.
This is another example of the kinds of data that could be included in a native application search engine (it can cover a really wide range based upon what each application does):
Data that is indicative of a field that is associated with native application content a user interacted with may include, for example, a “To:” field of a message, a “Subject” field of a message, a “Body” field of a message, a “Destination” field of a flight reservation, a “Date” field of a hotel reservation, a “Title” field of an article, or the like. Data that is indicative of user activity with a native application may include, for example, data that is indicative of several interactions a user has with a native application, data that is indicative of other native applications the user interacted with while using the native application, data that is indicative of a native application the user used before the native application, data that is indicative of a native application the user used after the native application, data that is indicative of patterns of switching between native applications by a user of a user device, and the like.
Data that is indicative of native application content creation time may include, for example, a timestamp that indicates when a user created the application content. Data that is indicative of native application content interaction time may include, for example, data that is indicative of the time a user interacted with native application content. For example, interaction time may include a timestamp that is indicative of the time a user viewed native application content in a native application. The number of application interactions may include the number of times a user interacted with a particular native application.
The number of times a user interacted with a particular native application may include:
(i) data indicative of a particular number of total application interactions with the user,
(ii) data indicative of a particular number of total application interactions within a predetermined period, or
(iii) a combination thereof. For example, the number of application interactions may include data that indicates a user opened the notes application 20 times, a user opened a travel application 46 times over the past week, or the like.
Shared Topic Native Application Use
The patent tells us that sometimes more than one native application may cover the same topics or tasks. They can involve:
- A set of multiple messages that were sent to the same recipient
- A set of multiple messages to different recipients related to the same subject
- A set of multiple disparate types of application content items related to the same subject
- Or the like
Content from multiple native application content related to the same task may be related to the same purpose, goal, or the like. For example, a trip to Italy. These can include:
- Booking a flight reservation to Italy using a Travel app
- Booking a hotel reservation in Rome using a Travel app (either the same travel app, or a different one
- Reviewing descriptions of tourist destinations using a Trip Mentor App
- Searching for restaurants or specialty shops (e.g., a Gelato shop) in Rome using a search engine
- Sending messages about specialty shops (e.g., a Gelato shop) the user is interested in visiting in Rome
- the user’s spouse using a messaging App
That wide amount of information may be clustered together and then used to generate a cluster feature vector. Or cluster feature vectors may be generated bases on entities identified by the text of native application content.
Those can include features from:
- Contact names
- Names of non-contact persons
- Place names
- Country names
- City names
- Business names
- The like
Data about the usage of different Native Applications and patterns involving users may also be identified.
Indexing for An Application Vertical Search Engine Based on Cluster Feature-Vectors
Each cluster feature-vector stored in the search engine index can be used to identify a native application content item (e.g., a message) on which the cluster feature-vector is based.
Therefore, instead of, or in addition to, performing a keyword search based on application content items, the user device may use the search engine to perform a vector similarity search of the cluster feature-vectors stored in the search engine index.
We have seen that different vertical search engines use different signals to rank and index content. This native Application Vertical Search Engine uses a Cluster Feature-Vectors approach to rank and index content from different native applications.
This patent is telling us about how such a search engine might function, and about how data from these Cluster Featured-vectors may be cached or may use a batch processing approach in the background. This kind of Cluster Feature-vector approach may be used on individual mobile devices, and a real-time generation of these cluster feature vectors may be computationally expensive, and use much of the battery of phones and tablets. But, a real-time generation of such vectors to index and rank content could be more robust and accurate. They would include data about the most recent interactions with native applications.
Take Aways about a Native Application Vertical Search Engine
This Native Applications Vertical Search Engine would be a nice addition to Google and could help Mobile device users search through the information that they had accessed in their applications. I would appreciate being able to look up travel information and arraignments about trips I’ve been planning.
I am reminded of what Google has described involving machine learning for mobile devices: Federated Learning: Collaborative Machine Learning without Centralized Training Data. As that paper tells us about Federated Learning:
Federated Learning enables mobile phones to collaboratively learn a shared prediction model while keeping all the training data on the device, decoupling the ability to do machine learning from the need to store the data in the cloud. This goes beyond the use of local models that make predictions on mobile devices (like the Mobile Vision API and On-Device Smart Reply) by bringing model training to the device as well.
I was going to publish this post on Monday, May 18, 2020, but the USPTO website appears to be broken. There’s value in decentralized databases. I will try to post it tomorrow.
One issue with a native application vertical search engine is that the data included in it relies so much upon a user’s interaction with their mobile devices. It’s questionable how much people might want that information to possibly be seen or used by other people.
It reminds me of the patent I wrote about in my post about User-Specific Knowledge Graphs to Support Queries and Predictions.
Google does have access to a lot of data about people.
It could be really useful to people who use it.
Google might be collecting too much information for many potential users.