





Google Speech Search Using Language Models
Published: March 04, 2021
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

Language Models Being Used For Speech Recognition
Way back in 2007, I wrote a post called Google Learning Speech Recognition for Voice Search from MTV? My post was about language models being used for speech recognition and how Google was learning new words to fit into language models.
That post was about a Google patent that was filed in 2001 and was granted in 2006 on Voice Interface for a Search Engine.
This new patent is also about language models. It tells us that speech recognition is becoming more and more common and that as technology has advanced, people using computing devices have increased access to speech recognition functionality.
Related Content:
We are also told that many searchers rely on speech recognition in their professions and other aspects of daily life. This can include mobile phones to search on and the growth of speaker devices to search on (including TVs.)
This patent focuses on language models that use information about non-linguistic contexts to increase the accuracy of automatic speech recognition.
This information about the environment or a situation that a searcher is in and information about the searcher can determine which words are most likely for a searcher to have spoken. I
Searchers may be more likely to speak certain words in some environments than in other environments.
For example, when a searcher is located in New York City, it can be more likely for the searcher to say the name of a restaurant located in New York City than to say the name of a restaurant located in another city.
A different example, searchers may commonly use the first set of words or phrases with an application for sending a short message service (SMS) text message. Still, searchers may use a different set of words and phrases with a map application.
Such language models may include one or more domain-specific model components corresponding to different domains or types of non-linguistic context data.
The language model could also include a baseline model component that can operate independently of non-linguistic context data.
The baseline model component and the domain-specific model components can be used together to determine a score for a language sequence using both linguistic and non-linguistic context information.
Language models may be log-linear models, and the baseline model component and the domain-specific model components each weights corresponding to n-gram features.
If non-linguistic context data is not available or does not match any of the domain-specific model components, the baseline model component alone is used to recognize speech.
If speech is known to occur in a non-linguistic context corresponding to one or more of the domain-specific model components, then the relevant domain-specific model components and the baseline model component are used to recognize the speech.
For example, suppose a searcher is in New York City. In that case, the log-linear model weights in a domain-specific model component for New York City are used, along with the log-linear model weights of the baseline model component. In contrast, the domain-specific model components for other locations are not used.
Domain Specific Language Models Components
As a result, different domain-specific model components are used with the baseline model component at different times and for different users, depending on the non-linguistic context when speech is detected.
Those domains can represent various aspects of a non-linguistic context.
For example, a domain may represent:
- A location (e.g., being located in a particular country, a particular city, or other location)
- A user characteristic (e.g., that the user is male or female, the user speaks a particular dialect, etc.)
- An application running on a device (e.g., a maps application, an email application, etc.)
- A time (e.g., a particular day, a time of day, a weekend or weekday, etc.)
- A device status (e.g., in a vehicle, moving or not moving, etc.)
- Or another aspect of non-linguistic context.
The patent tells us that training language models to use non-linguistic contexts can present several challenges.
One of those is that the amount of training data to give examples in specific domains can be generally small, much smaller than the amount of training data showing general language usage.
This sparsity of domain-specific examples may not allow domain-specific training for many of the words and phrases in language models. Because of that, anguage models may effectively ignore domain-specific information.
Another problem is that the overall performance of the model may be negatively affected by domain-specific information.
For example, words entered into a map application may inappropriately increase the likelihood that the model provides for those examples, even for speech that is not provided to the map application.
Also, the order of samples used in training and the learning rate parameters used can greatly affect the accuracy of the final model.
And finally, there are a vast number of possible combinations of n-grams and different contextual factors.
The patent tells us that it would not be feasible to train a model with features for each of these combinations since it would require an extreme number of training examples and would require a model of excessive size and complexity.
The patent tells us that various implementations of the techniques disclosed address one or more of these challenges.
Language models can include a baseline model component that is domain-independent and one or more domain-specific components that correspond to domains representing different non-linguistic contexts.
This model structure allows the domain-specific components to have a meaningful influence when a matching context is present while avoiding the improper influence of the domain information on the baseline model component.
This baseline model component can be trained first.
Parameters of the baseline model component can be constant, while the domain-specific model components are each trained separately.
The domain-specific model components are trained using the trained baseline model component but do not affect the baseline model component.
Regardless of the amount, content, and ordering of training data for different domains, the accuracy of the baseline model is not affected.
This preserves the accuracy of the model for general use when non-linguistic context information is not provided or does not correspond to any domain-specific model components.
Also, each domain-specific model component can be focused on the most frequently occurring n-grams for its domain, limiting the total number of features needed in language models and trains the most significant features for each domain using the limited set of training data available.
This domain-specific model component may include parameters for multiple sets of features, such as unigrams, bigrams, or other n-grams.
The various domain-specific model components may include parameters for different sets of n-grams. Each domain-specific model component includes parameters representing the n-grams that occur most commonly in the corresponding domain.
When language models are used to recognize speech, the speech recognition system uses non-linguistic context information to select which domain-specific model components to use.
The baseline model component and the selected domain-specific model components are used to determine scores for candidate transcriptions.
One innovative aspect of the subject matter described in this specification is embodied in methods that include the actions of:
- Obtaining a baseline language model for speech recognition, baseline language models are configured to determine likelihoods of language sequences based on linguistic information
- Accessing, for each domain of a set of multiple domains, a respective set of training data indicating language occurring in a particular non-linguistic context associated with the domain.
This method can also include generating multiple domain-specific model components based on the training data and training each of the domain-specific model components using the respective set of training data for the domain of the domain-specific model component, wherein training includes updating parameters of the domain-specific model component using the output of baseline language models without changing parameters of baseline language models.
Other implementations of this and other aspects include corresponding systems, apparatus, and computer programs, that are configured to use language models.
These may include one or more of the following features.
Obtaining the baseline language model for speech recognition includes training the baseline model using language sequences not labeled as occurring in the non-linguistic contexts associated with the domains.
The linguistic information may correspond to previous words in a sentence.
Baseline language models may not use non-linguistic context information.
Baseline language models may be log-linear models, and baseline language models and the domain-specific model components form log-linear models.
The set of multiple domains may include particular applications, particular times, particular locations, particular user types or user characteristics, and particular events.
The training data for a particular domain may include the text of user input labeled as being provided in the particular domain.
Generating multiple domain-specific model components based on the training data may include initializing weights of the domain-specific model components to zero. At the beginning of training, output using the baseline language model and the domain-specific model components is equal to the output of the baseline language model alone.
Generating multiple domain-specific model components based on the training data may include multiple feature sets for each domain-specific model component.
The multiple domain-specific model components may include a unigram feature set, a bigram feature set, or a trigram feature set.
Generating multiple domain-specific model components based on the training data may include:
- Determining, for each of the multiple domain-specific model components, a set of n-grams, the sets of n-grams for the different domain-specific model components being determined using different sets of training data
- Generating each of the domain-specific model components to include features corresponding to the set of n-grams determined for the domain-specific model component
Determining the set of n-grams for a domain-specific model component may include selecting a subset of n-grams that occur in the training data for the domain-specific model component using a frequency-based cutoff.
The baseline model has features corresponding to n-grams, and each of the domain-specific model components has fewer features than the baseline model.
The n-grams determined for the domains represent terms or phrases having corresponding features and weights in baseline language models.
Training each of the domain-specific model components using the respective set of training data for the domain of the domain-specific model component can include training using stochastic gradient descent.
Training each of the domain-specific model components using the respective set of training data for the domain of the domain-specific model component includes: generating a score for a language sequence that occurs in a first non-linguistic context using (i) weights of the baseline language model and (ii) weights of at least one of the domain-specific model components that corresponds to the first non-linguistic context.
In some implementations, generating the score includes generating the score independent of domain-specific model components for domains that do not correspond to the non-linguistic context.
Training each of the domain-specific model components may include adjusting the weights of the domain-specific model components that correspond to the first non-linguistic context based on the generated score while not adjusting the weights of baseline language models.
The method includes providing combined language models that may include baseline models and the domain-specific model components, combined language models being configured to generate a language model score using the baseline language together with zero or more of the domain-specific model components dynamically selected according to the non-linguistic context of audio data to be recognized using combined language models.
The combined language model provides output equal to the output of the baseline language model alone when the non-linguistic context of audio data to be recognized does not correspond to any of the domains of the domain-specific model components.
Another innovative aspect of the subject matter described in this specification is embodied in methods that include the actions of:
Obtaining context data for an utterance, the context data can indicate:
(i) a linguistic context that includes one or more words preceding the utterance
(ii) a non-linguistic context; selecting, from among multiple domain-specific model components of a language model, a domain-specific model component based on the non-linguistic context of the utterance; generating a score for a candidate transcription for the utterance using the language model, the score is generated using
(i) the selected domain-specific model component, and
(ii) a baseline model component of the domain-independent language model determines a transcription for the utterance using the score. It provides the transcription as an output of an automated speech recognition system.
The domain-specific model components correspond to a different domain in a set of multiple domains, and the baseline model does not correspond to any of the multiple domains.
The baseline model component is configured to provide a language model score independent of non-linguistic context information.
Generating the score for a candidate transcription for the utterance using the language model may include generating the score without using the domain-specific model components that were not selected.
The baseline model component and each of the domain-specific model components are log-linear models. Each of the log-linear models comprises weights corresponding to a respective set of features.
The respective set of features for each of the log-linear models may include n-gram features.
The baseline model component can include weights for features representing the occurrence of n-grams independent of non-linguistic context. In addition, the domain-specific model components can include weights for features that represent n-grams in specific non-linguistic contexts. Thus, each of the domain-specific model components has weights for a different non-linguistic context.
Language models can include
(i) the baseline model component, which uses linguistic context information and does not use non-linguistic context information
(ii) the domain-specific model components, which use both linguistic context information and non-linguistic context information.
Each of the domains may correspond to at least one of a:
- Location
- Time condition
- User characteristic
- Device characteristic
- Device status
Generating the score for the candidate transcription can include: generating the score using a scoring function that changes according to which domain-specific model components are selected.
Generating the score for the candidate transcription can include determining.
(i) first feature values for first n-gram features of the baseline model component
(ii) second feature values for the second n-gram features of the selected domain-specific model component.
The second n-gram features of the domain-specific model component correspond to a subset of words or phrases with n-gram features in the baseline model component but represent the words or phrases in the particular non-linguistic context associated with the domain-specific model component.
Generating the score for the candidate transcription for the utterance using language models includes: multiplying the first feature values with corresponding weights for the first n-gram features in the baseline model; multiplying the second feature values with corresponding weights for the second n-gram features in the selected domain-specific model component, and generating the score using a sum of the results of the multiplications.
Generating the score for the candidate transcription for the utterance using language models include: determining a sum of
(i) weights for the first n-gram features of the baseline model and
(ii) weights for the second n-gram features of the selected domain-specific model component; and generating the score based on the sum.
The method includes:
- Obtaining data indicating multiple candidate transcriptions for the utterance
- Generating a score for each of the multiple candidate transcriptions, wherein the score for each of the multiple candidate transcriptions is generated using the baseline language model component and the selected domain-specific model component
- Determining the transcription for the utterance can include selecting, as the transcription for the utterance, a particular candidate transcription of the multiple candidate transcriptions based on the generated scores
Each of the domain-specific model components has multiple feature sets.
Generating the score for the candidate transcription includes generating the score using at least one, but less than all, of the feature sets of the selected domain-specific model component.
Generating the score for the candidate transcription includes generating the score using all of the feature sets of the selected domain-specific model component.
The method includes dynamically changing which domain-specific components are used to recognize different utterances in a sequence based on changes in the non-linguistic context for the utterances.
Advantages Of Following the Process in the Langauge Model Patent
The accuracy of speech recognition may be increased by taking into account the user’s situation that is speaking.
Language models may provide estimates using linguistic and non-linguistic contextual information.
Language models may be accessed to generate multiple domain-specific model components based on training data that can include linguistic and non-linguistic contextual information.
The domain-specific model components can improve speech recognition accuracy for a particular domain while remaining independent from the initial language models.
Further, the amount of time and computation required to generate a model that corresponds to a particular context can be decreased while providing better accuracy with less training data.
For example, using a baseline model, a relatively small amount of training data for a specific context may be used to tailor recognition for that context.
The techniques described in this patent application to many modeling techniques.
The technique of forming a log-linear model with a baseline component and domain-specific adaption components, and the process of training, is widely applicable.
While language modeling for speech recognition is discussed in detail, the same techniques can be used for any application involving language modeling, including machine translation, parsing, and so on.
We are also told that apart from language modeling, the techniques can be used to generate, train, and use models for:
- Spam detection
- Image classification
- Visual analysis
- In conditional random field models.
This patent can be found at the following location:
Language Models Using Domain-Specific Model Components
Innvented by: Fadi Biadsy and Diamantino Antionio Caseiro
Assignee: Google LLC
US Patent Application: 20210020170
Published January 21, 2021
Filed: October 1, 2020
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for language models using domain-specific model components.
In some implementations, context data for an utterance is obtained.
A domain-specific model component is selected from among multiple domain-specific model components of language models based on the non-linguistic context of the utterance.
A score for a candidate transcription for the utterance is generated using the selected domain-specific model component and a baseline model component of domain-independent language models.
Transcription for the utterance is determined using the score the transcription is provided as an output of an automated speech recognition system.
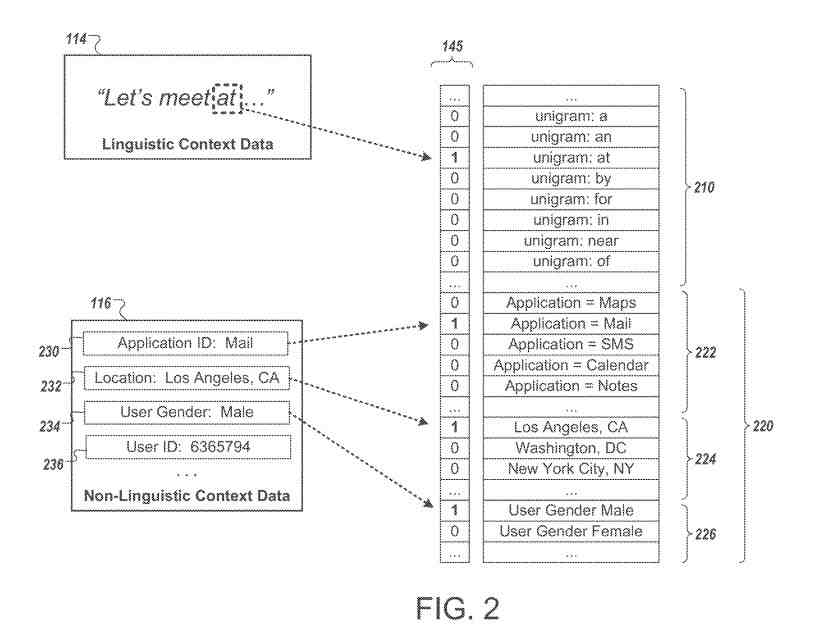
This patent starts with a system for speech recognition with language models using a non-linguistic context.
The system includes a client device, a computing system, and a network.
The computing system may provide scores determined from non-linguistic context data to a language model, which provides an output that the computing system uses to determine a transcription for the audio data.
The functions performed by the computing system can be performed by individual computer systems or can be distributed across multiple computer systems.
A computing system may receive audio data indicating characteristics of an utterance and context data indicating the non-linguistic context of the utterance.
Scores for the non-linguistic features can be generated based on the context data.
Those scores can be provided to language models trained to estimate likelihoods based at least in part on scores for non-linguistic features.
Information from language models can be received and used to determine a transcription for the utterance.
The language model is log-linear.
The language model is a maximum entropy model, a support vector machine model, a neural network, a set of classifiers, or another type of model.
During stage (A), a user speaks, and the client device detects the user’s utterance.
The client device may record the utterance using a microphone.
The user may provide the utterance as voice input for any of a variety of applications, including applications for:
- Calendar
- Mapping
- Navigation
- So on
Thus, the utterance may represent any of a variety of types of input:
- Queries
- Messages
- Body of messages
- Voice commands
- Addresses
- Phone numbers
- So on
In the example, the user dictates the contents of an e-mail message while a “Mail” application is running on the client device.
The searcher previously entered the text “Let’s meet at” as part of the message, and the utterance includes the words “Hermosa beach” as further input to add to the message.
During the second stage (B), the client device collects information and sends nonlinguistic context information to the computing system over the network. The information may be sent with, for example, a request for a transcription of the utterance.
The client device sends audio data for the utterance to the computing system.
The audio data may be, for example, a recording of the utterance or information derived from the detected utterance, such as filterbank energy values, mel-frequency cepstral coefficients (MFCCs), or scores for other acoustic features.
The client device may also send linguistic context data that indicates a linguistic context for the utterance (such as the words actually said by the message sender.)
For example, the client device may provide data that indicates the words that the utterance follows.
In the illustrated example, the linguistic context data indicates the words “Let’s meet at” that immediately precedes the utterance.
In some implementations, the linguistic context data provides a specific amount of text, for example, the previous one, two, three, five, or ten words, or the text recognized within a predetermined amount of time.
The linguistic context may include words that were previously spoken by the user and are recognized and/or text that was entered or accessed in another manner.
For example, a user could open a text file, place a cursor at a particular position in the text, and begin speaking to insert additional text.
Some text before the cursor may be provided as linguistic context, regardless of how the text in the file was entered.
The client device may also determine and send non-linguistic context data to indicate a non-linguistic context for the utterance.
The non-linguistic context data may indicate, for example, characteristics of the environment in which the utterance is spoken.
The non-linguistic context data can indicate factors related to the physical environment of the user or client device, such as:
- Geographical location
- Time
- Temperature
- Weather
- Ambient noise
The non-linguistic context data can provide information about the physical state of the client device:
- Whether the device is moving or stationary
- The speed of movement of the device
- Whether the device is being held or not
- A pose or orientation of the device
- Whether or not the device is connected to a docking station
- The type of docking station to which the client device is connected
The non-linguistic context data can provide:
- Information about the operating state of the client device
- An identifier for an application running on the client device
- A category or classification for the application to which that the utterance was provided as input
The non-linguistic context data can also indicate information about the user that spoke the utterance:
- A user identifier
- Whether the user is male or female
- Other information from a user profile for the user
The client device may determine its location using a global positioning system (GPS) module or other techniques. For example, it can determine that the client’s device is located in the city of Los Angeles.
The client device can also determine that the utterance was recorded as input to a mail application running on the client device.
The client device may provide data indicating the location, e.g., “Los Angeles.” The active application, e.g., the “Mail” application, to the computing system as non-linguistic context data.
The client device also provides the audio data and the linguistic context data to the computing system.

During stage (C), the computing system uses a speech recognizer module to determine candidate transcriptions for the utterance.
The candidate transcriptions may be provided as, for example, a list, a word lattice, or in other forms.
The candidate transcriptions may be scored or ranked to indicate which candidate transcriptions the speech recognizer module estimates to be most likely to be correct transcriptions.
In the illustrated example, the candidate transcriptions represent a set of highest-ranking or most likely transcriptions, as estimated by the speech recognizer.
This set can be an n-best list, including, for example, the top 3, 5, 10, 25, or another integer number of candidate transcriptions.
The speech recognizer module may use an acoustic model and a language model to identify the candidate transcriptions.
Those models used by the speech recognizer module may or may not use non-linguistic context data to determine candidate transcriptions.
The candidate transcriptions may be determined based on audio data and linguistic context data without being influenced by the non-linguistic context data.
Another language model may use information about the non-linguistic context to re-score or re-rank the candidate transcriptions to improve accuracy.
The speech recognizer module may use the non-linguistic context data to identify and/or score the candidate transcriptions.
During stage (D), the computing system uses a feature extraction module to determine scores for various features.
For example, the feature extraction module can determine which of various linguistic features and/or non-linguistic features should be set as being active for a particular utterance.
Examples of Language Model Feature Scores
The linguistic context data can be used to determine scores for linguistic features.
The non-linguistic context data can be used to determine scores for non-linguistic features.
In the example, each of the feature scores is a binary value that indicates whether the corresponding feature describes the environment in which the utterance is spoken.
The feature scores can be organized as one or more feature vectors.
For example, scores for linguistic features and scores for non-linguistic features are included together in a context vector.
The feature scores may be determined based on information received from the client device or other information, such as information from other devices and information stored at or accessible to the computing system.
The feature scores may be values that correspond to a predetermined set of features used to train the language model.
For example, each value in the vector can represent a score for a particular predetermined contextual feature, with the scores being arranged in the vector in the same order or arrangement used during training.
In the example, each of the feature scores is a binary value. Thus, a value of “1” indicates that the data from the client device indicates that the feature corresponding to the feature score is likely part of the context for the utterance. Conversely, a value of “0” may indicate that the corresponding feature is likely not part of the context in which the utterance is spoken or that sufficient information is not available to confirm whether the feature reflects the current context.
Although the illustrated example uses binary values as feature scores, other values may be used. For example, different values may indicate different estimates or likelihoods that different features describe the current context.
The feature scores include a score for each of a set of linguistic features, which can represent, for example, characteristics of text that the utterance occurs after.
For example, the scores for linguistic features may indicate one or more words that occur in sequence before the utterance.
The linguistic features may include n-gram features.
For example, a unigram feature may indicate whether a particular word occurs immediately before the words in the utterance.
A bigram feature may indicate whether a particular sequence of two words occurs before the utterance.
A trigram feature may indicate whether a particular sequence of three words occurs before the utterance.
Scores may be determined for n-gram features for any appropriate value of n. In addition, they may include scores for multiple values of n, such as a combination of unigram, bigram, and trigram features.
In some implementations, linguistic features may indicate other information about the lexical characteristics of prior words, such as the part of speech of one or more prior words or whether a prior word includes a particular prefix, suffix, or another component.
The feature scores can also include a set of scores for non-linguistic features, which can represent, for example, the physical environment in which the utterance is spoken, or the operating state of the client device, or characteristics of the user, or other features other than words or phrases that the utterance follows.
The scores for the non-linguistic features can be separate and independent from the text or spoken words that precede the utterance. Examples of non-linguistic features include application features, location features, and user features.
Application features may indicate an application that is active on the client device, for example, the application to which the utterance is provided as input.
Each of the application features may correspond to a specific application, and the score indicates whether the application is active.
The non-linguistic context data can include an application identifier for the active application.
A predetermined set of applications can each have a different corresponding application identifier.
Location features may indicate the geographical location of the user and/or the client device.
For example, different location features may indicate whether the client device is located in a particular country, state, county, city, or another geographical region.
In the example, each location indicates whether the utterance is entered at a particular city.
The non-linguistic context data includes a location identifier that indicates that the client device is located in the city of “Los Angeles,” so the score for the “Los Angeles” location feature is set to “1.”
Since the user is not in any of the other cities, the remainder of the location features is set to “0.”
The user features indicate the user’s characteristics that are believed to have spoken the utterance, e.g., a user that is logged in at the client device or the owner of the client device.
In the example, the user features indicate whether the user is male or female.
The non-linguistic context data indicates that the user is male, and so the score for the “male” feature is set to “1.”
Other user features may indicate other user attributes.
In some implementations, the non-linguistic context data includes a user identifier that corresponds to the user.
The user identifier may be used to access a user profile, a search query history, or a browsing history for the user to determine other scores.
For example, in some implementations, user scores may indicate whether the user has previously submitted a search query with certain words or phrases or whether the user has searched for or browsed web pages related to various topics.
Various features may correspond to different categories or topics of searches, such as “sports,” “shopping,” “food,” etc.
In some implementations, non-linguistic features may indicate personalized information for a user:
- Names in a phone contact list or address book
- Names or numbers in a list of frequently called list
- Addresses stored as favorite locations
- So on
A client device may provide, or the computer system may store, information indicating names in the frequently called list or other data.
Some Other Non-Linguistic Language Model Features
There are several different non-linguistic features that information might be collected about, such as:
- A domain name (e.g.., “example.com,”) with the scores indicating whether the user is currently visiting a web page
- An operating system running on the client device
- A device type of the client device (e.g., tablet computer, phone, laptop computer, etc)
- A type of input field that the transcription of the utterance will be entered into (e.g., whether the input field accepts an address, a name, a phone number, an e-mail address, a URL, a search query, etc.)
- A task a searcher may be performing, such as dictating, composing a message, or shopping.
- Any information about the user, the client device, or the environment in which the utterance is made, other than information that describes or is derived from the words that precede the utterance
Feature Scores and Language Model
The feature scores can be provided as input to the language models.
Based on the feature scores, language models can provide a set of output values. For example, these may indicate the likelihood that one or more words will occur in the current context.
The language model can be a model that has been trained to estimate the likelihood of a word or phrase occurring based on scores for linguistic and/or non-linguistic features.
For example, the language model can determine a posterior probability of a current word, e.g., the first word of the utterance, given information about the context for the utterance, which may include linguistic context, e.g., the prior words “Let’s meet at,” and/or non-linguistic context, e.g., location, device state, application, user characteristics, etc.
The features used to train the language model can be the same linguistic features and non-linguistic features corresponding to the feature scores.
In other words, the feature scores are determined for the features that the language model was trained to be able to process and use to determine word likelihoods.
The language model may include a set of internal weights representing the training state of the language model.
These weights may indicate how various aspects of context make words more or less likely to occur. Typically, the weights in the language model are set during the language model training and do not change during the use of the language model.
However, the weights are trained using examples of input from various users and different environments. As a result, the language model can estimate the likelihoods of words occurring given many different types of linguistic and non-linguistic contexts.
The language model may be log-linear.
Log-linear models may effectively consider scores from large numbers of features and scores for features of multiple different types.
For example, a log-linear model may be used to combine word n-gram feature scores with feature scores indicating:
Physical environment
User characteristics
Other factors.
In some implementations, log-linear models may provide greater efficiency or smaller storage requirements than, for example, hidden Markov models (HMMs) or other statistical models.
The language model may be a maximum entropy model. Other types of models and other training techniques may additionally or alternatively be used:
- Support vector machines
- Neural networks
- Classifiers
- Linguistic feature scores
- Non-linguistic feature scores
- Other types of information
Location Information in Language Models
Trained language models may include:
Weights so that when the feature scores indicate that the user is using the navigation application, the language model indicates an increased likelihood that the location names used in the navigation application may occur in the speech of the user. If the word “theater” frequently occurs in the searcher’s language, there is a possibility that they are located there.
Training data may also indicate which words are spoken most frequently at different locations, and the weights within the language model can adjust for differences in likelihoods between different locations.
When the user’s location is indicated in the features scores, weights within the language model can increase the likelihood for words frequently spoken at the user’s location and can decrease the likelihood for words infrequently spoken or not spoken at the user’s location.
Since men and women may use certain words with different frequencies, a language model may include weights that take into account the gender of the user in estimating which word occurs in a sequence.
Output values that the language model provides may be scores indicating the likelihood of different words given the context indicated by the feature scores.
For example, the language model may indicate a posterior probability P(y|X), or values from which the probability may be determined, where y represents a lexical item, such as a word, number. URL, or another lexical item, and X is a vector including the feature scores.
The training of the language model allows the language model to use the various feature scores to adjust probabilities according to the user’s situation.
The probability that a word is the name “Mike” may be greater if the feature scores indicate that the name “Mike” is in the user’s frequently called list than if the name is not in the list.
An athlete’s name may be indicated to be more likely if the feature scores indicate that one or more of the user’s prior searches relate to the topic of sports than if prior searches are not related to the topic of sports.
Business names and addresses that are near the user or were spoken by others near the location of the user may have a higher probability than if the business names and addresses that are far from the location of the user or are not frequently used by other users at the location of the user.
Typically, the user’s environment does not change mid utterance, so scores for non-linguistic features may remain the same for each word in the candidate transcriptions in some instances.
However, if factors such as location, the application in which a user is speaking, the field in which input is entered, or other contextual aspects change during dictation, the scores for non-linguistic features may be updated to reflect the different environment in which different words were entered.
The client device may provide updated non-linguistic context data when the non-linguistic context changes. For example, the computing system may associate different non-linguistic contexts with different utterances or different portions of an utterance.
During stage (F), the computing system uses a re-scoring module to determine scores for the different candidate transcriptions.
For example, based on outputs from the language model for each of the different words of the candidate transcriptions, the re-scoring module determines a score indicating a likelihood of occurrence of each candidate transcription as a whole.
For example, for the first candidate transcription, the re-scoring module may combine scores from the language model for the individual words “hair,” “mousse,” and “beach” to determine an overall score for the phrase “hair mousse beach.”
During stage (G), the computing system selects a transcription for the utterance based on the scores.
For example, the computing system may select the candidate transcription with the score indicating the highest likelihood of occurrence.
The output of the language model indicates that the phrase “Hermosa beach” is the candidate transcription that is most likely to be correct.
Although the initial ranking of the candidate transcriptions did not indicate it to be the most likely transcription, non-linguistic context data allows the language model to more accurately estimate the likelihood that it is the correct transcription.
“Hermosa Beach” is the name of a place near Los Angeles, and training data for the language model indicated that users in Los Angeles are more likely than users at other places to say the phrase.
Accordingly, the training for the language model was trained “Hermosa beach” and other words spoken in Los Angeles, a higher likelihood when a user is located in Los Angeles.
Because the non-linguistic context data indicated that the user is located in Los Angeles, the language model provided output indicating “Hermosa beach” has a high likelihood of being correct.
During stage (H), the computing system provides the selected transcription to the client device.
The client device may insert the transcription in the application running to complete the user’s intended phrase, “Let’s meet at Hermosa beach.”
In the example shown, non-linguistic context data is used to re-score candidate transcriptions that were determined without considering non-linguistic context data.
In some implementations, the speech recognizer may use a language model, such as the language model, that uses non-linguistic context data to select and rank the candidate transcriptions.
In these implementations, a separate re-scoring process may not be needed.
In some implementations, the input to the language model may include only feature scores for non-linguistic features.
In other implementations, feature scores may be provided for both linguistic and non-linguistic features.
In some implementations, a language model that determines likelihoods using both linguistic and non-linguistic features may have better accuracy than a language model that provides scores based on only linguistic features or only non-linguistic features.
A Word Lattice Provided by a Speech Recognizer System
The word lattice represents multiple possible combinations of words that may form different candidate transcriptions for an utterance.
The word lattice can include one or more nodes that correspond to the possible boundaries between words.
The word lattice includes multiple edges for the possible words in the transcription hypotheses that result from the word lattice.
Besides, each of the edges can have one or more weights or probabilities of that edge being the correct edge from the corresponding node.
The speech recognizer module system determines the weights. They can be based on, for example, confidence in the match between the speech data and the word for that edge and how well the word fits grammatically and/or lexically with other words in the word lattice.
Initially, the most probable path through the word lattice may include the edges, which have the text “we’re coming about 11:30.”
A second-best path may include the edges, which have the text “deer hunting scouts 7:30.”
Each pair of nodes may have one or more paths corresponding to the alternate words in the various candidate transcriptions.
For example, the initial most probable path between the node pair beginning at the node and ending at the node is the edge “we’re.”
This path has alternate paths that include the edges “we are” and the edge “deer.”
Weights for the edges may be determined using a language model that takes into account non-linguistic context.
For example, a language model may be used to determine weights for each edge using information abou:
- A location an utterance was spoken
- An application used
- The user that spoke the utterance
- Other non-linguistic context
The new or revised weights may be replaced or be combined with, e.g., averaged or otherwise interpolated, with the initial weights for the edges.
The re-scored lattice may then be used to select a transcription.
Alternatively, a language model that uses non-linguistic context data may be used to determine the initial weights for the edges.
A language Model that uses Non-Linguistic Context
This starts with audio data indicating the characteristics of an utterance is received.
The audio data may include recorded audio, including the utterance. As another example, the audio data may include scores for acoustic features that represent acoustic characteristics of the utterance.
Context data indicating the non-linguistic context of the utterance is received.
The context data may indicate:
- A location the utterance was received
- An application that is active on a device that detected the utterance
- Information about a user of the device that detected the utterancev
- Personalized information stored on the device, such as calendar entries
- A list of people called, or other information
Scores for Non-Linguistic Features can be Based on Context Data
The context data may indicates:
- An application through which the utterance is entered
- The application belongs to a particular class or category (an active application)
- A gender of a speaker of the utterance
- A geographical location where the utterance was spoken
- Names in a contact list or list of calls made or received
- A task that the user is performing (dictating, entering a URL, composing a message, entering an address, entering a query, etc.)
- A type of input field that is active
- Topics of prior searches or web browsing of the user
- A user identifier (a user account name or a value from a cookie)
- A physical state of a device that detects the utterance
The feature scores may be binary values that indicate whether a particular aspect of a non-linguistic context describes the context in which the utterance is entered.
For example, a different feature score may be determined for each of a set of applications.
For each application, a binary value may be determined to indicate whether the utterance was entered using that particular application.
Similarly, a different feature score may be determined for each of a predetermined set of locations to indicate whether the utterance was spoken at the corresponding location.
Scores for the non-linguistic features are provided to a log-linear language model.
The language model may be trained to process scores for non-linguistic features.
The language model may be trained to estimate the likelihood that a word occurs in a sequence of words based at least in part on scores for non-linguistic features.
The language model may be trained based on the text entered by multiple users in various contexts (e.g., users using different applications, users in different locations, users having different characteristics, and/or users performing different tasks.)
The output from the log-linear language model is received.
For example, the output may include a score for a word. The score indicates an estimated likelihood that the word occurs given the non-linguistic features provided as input to the language model.
The output may be based on input to the language model that indicates linguistic context for the utterance, such as one or more words that precede the utterance.
Transcription for the utterance is determined using the output of the log-linear language model.
The output of the log-linear language model may be used to score one or more transcriptions, and transcription may be selected based on the scores.
A set of candidate transcriptions, such as an n-best list, for the utterance is received, and scores for each of the candidate transcriptions in the set are determined based on the output of the log-linear language model.
One of the candidate transcriptions may be selected based on the scores for the candidate transcriptions.
A word lattice indicating candidate transcriptions for the utterance may be received.
Scores corresponding to elements of the word lattice may be determined based on the output of the log-linear language model, and a transcription for the utterance may be selected based on the scores corresponding to elements of the word lattice.
Data can be received that indicates a linguistic context for the utterance (e.g., one or more words occurring before the utterance.)
Feature scores may be determined for one or more linguistic features based on the data indicating the linguistic context.
For example, word n-gram scores may be determined based on one or more words spoken or otherwise entered before the utterance.
The scores for one or more linguistic features may be provided to the log-linear language model.
Scores for linguistic features and non-linguistic features are provided together as part of the same vector of feature scores.
The output received from the log-linear language model can be based on
(i) the scores for the non-linguistic features and
(ii) the scores for the linguistic features.
For a given the word, the output may include a score indicating the likelihood of the word occurrence, given both the scores for the linguistic features and non-linguistic features.
The Process for Training a Language Model
The patent tells us about how training data for training a language model is obtained.
First, unsupervised user input is collected from different users. For a language model to use in speech recognition, spoken inputs may be collected from various users and used as training data.
That training data may include utterances entered by different users over the normal course of using many applications or performing various tasks.
The training data may include data entered through:
- Spoken input
- Typed input
- Other forms of input
Next, non-linguistic context data for the training data is obtained.
That data can be metadata or other information that indicates characteristics of the environment in which the utterances or text samples in the training data were entered.
The non-linguistic context data may indicate which applications users used to enter their utterances.
The non-linguistic context data may indicate a location of a user or a device when utterances were spoken.
Different contextual information may be available for different portions of the training data.
The application user may be known for some training data and not for other training data.
It may be advantageous to use some training data where some non-linguistic context is not indicated, which may improve robustness and accuracy when the model is used with inputs that do not provide non-linguistic context data.
Some training data may not have any corresponding application identified, and so examples for training may have no application identified.
Those examples may help the training process create model weights that can accurately estimate input sets that do not indicate an application.
After that, transcriptions are generated for the training data.
An automatic speech recognizer may determine likely transcriptions for utterances in the training data. In addition, transcriptions may be determined from logs of previously transcribed inputs.
Next, a set of features are selected.
The features may include linguistic features and non-linguistic features.
The linguistic features may include word n-gram features. A different unigram feature may be used for each word in a vocabulary used to train the language model.
Bigram features, trigram features, or other n-gram features may also be selected. An n-gram feature may be selected for each n-gram in the training data at least a predetermined number of times.
The non-linguistic features may indicate, for example, different applications, locations, user attributes, or any other appropriate aspects of non-linguistic context.
The training data may be evaluated to determine the most frequently used applications.
A different feature may be selected to represent each of a predetermined number of the most frequently used applications (e.g., the 25, 50, or 100 most commonly used applications.)
The most frequent locations indicated by the non-linguistic context data may be identified.
A different feature may correspond to each city within the set of most frequent locations.
Similarly, sets of features, which may be binary features, may be selected for all appropriate contextual factors that the model will be trained to use.
The features used to train a language model and provide input to a trained model may indicate two or more contextual factors.
A feature could indicate the presence of two different non-linguistic factors, e.g., a value of “1” for a single feature could indicate (i) that an application identifier corresponds to a mail application and (ii) that the user is in New York City.
A feature could represent a combination of a particular linguistic factor together with a non-linguistic contextual factor.
A single feature could correspond to the prior word spoken being “park” and the current application being a map application.
Other combinations of contextual information in features, including features representing three or more aspects of linguistic and/or non-linguistic context, may be used.
Next, language model weights or other parameter values are determined.
From the training data, feature vectors are determined.
From an utterance transcribed as “the cat is black,” one feature vector may indicate the occurrence of the word “the” at the beginning of a phrase, another feature vector may indicate the occurrence of “cat” after the word “the” another feature vector may indicate the occurrence of the word “is” after the word “cat,” and so on.
Each feature vector includes feature scores for all selected features to indicate the context in which the word occurred.
A different example feature vector may be determined for each transcribed word in each utterance instance in the set of training data.
Using the feature vectors extracted from the training data, the model is trained to model the probability distribution of the word occurrences in the training data.
A log-linear model may be trained using a stochastic gradient descent technique using characteristics of the training data.
The posterior probability distribution of the training data may be modeled directly, using unsupervised spoken data, such as the output of a speech recognition system and/or data typed by users.
A different weight can be included in the language model for each word in the vocabulary of the language model concerning each one of the selected features.
If a language model has a vocabulary of 10,000 words and 15,000 contextual features were selected, the language model’s total number would be 10,000*15,000=150,000,000 weights.
As a result, the effect of any of the selected features concerning any of the words in the vocabulary may be determined.
The language model may include fewer weights to reduce space or computation requirements or remove weights for unlikely words or unlikely combinations of words and contexts.
Several different models may each be trained in parallel using different subsets of the training data.
The parameters of the various models may be adjusted in various iterations.
The models may be adjusted using various examples from the training data until the parameters converge, reach a threshold level of similarity, or meet other desired criteria.
The weights of different models may be combined (e.g., averaged, at one or more iterations until a final set of weights for the model is determined.)
A log-linear model is trained to provide a probability of occurrence of any particular word, y, in a vocabulary given a vector of input feature scores, x, and using the language model weights, w, determined during the training of the language model.
The probability may satisfy Equation (1), below:
P ( y | x ; w ) = exp ( w * f ( x , y ) ) y ‘ .di-elect cons. Y ( exp ( w * f ( x , y ‘ ) ) ( 1 ) ##EQU00001##
In Equation (1), Y is a finite set of lexical items such as the set of words or other lexical items in the vocabulary, y is a particular item from the set Y, x is a feature score vector indicating the feature scores for a particular context, w is a parameter vector indicating weights of the trained language model, and f(x, y) is a function that maps a combination of a lexical item and context to a vector.
The output of the function f(x, y) represents the set of input feature scores, x, concatenated or otherwise combined with one or more scores that indicate which lexical item, y, is being predicted.
For example, a second vector can be determined to include a score of “1” for the lexical item for which the probability estimate is desired, and a score of “0” is included for every other lexical item in the vocabulary of the language model.
The second vector may be combined with the feature score vector, x, to form the output vector of function f(x, y).
Other techniques for the function f(x, y) may additionally or be used.
In some implementations, the output of the function f(x, y) may include a value corresponding to each weight in the language model.
For example, the output vector may include a score for the particular word to be predicted concerning each linguistic and non-linguistic feature and zero for every other word in the vocabulary for every linguistic and non-linguistic feature.
Other types of models besides log-linear models may additionally be used.
For example, the process may train a support vector machine, a neural network, one or more classifiers, or another type of model using appropriate training algorithms.
Generating Language Models with Domain-Specific Model Components
This system includes a computing system that generates a language model with a baseline model component and multiple domain-specific model components.
The computing system connects to several groups of training data (e.g., a general corpus and domain-specific corpora.)
A training module is used to update the parameters of the language model.
The functions to update it can be performed by individual computer systems or distributed across multiple computer systems.
At first, the computing system generates the baseline model component.
The baseline model component can be a log-linear model trained using stochastic gradient descent (SGD).
The baseline model component includes features corresponding to n-grams from the general corpus, including examples of language sequences.
The examples in the general corpus are typically not labeled with any non-linguistic context and so represent a large set of domain-independent data.
The general corpus includes a large amount of examples such as:
- Voice search queries
- Text from dictation
- Web documents or other text
That corpus may include examples from a broad set of different sources.
To generate the baseline language model component, n-grams in the general corpus are identified.
Features corresponding to the n-grams are defined for the baseline model component so that the baseline model component has a log-linear model weight for each feature.
The values of the weights are then updated using SGD training, for example, until the desired level of accuracy of the baseline model component is achieved.
The baseline model component is trained to determine language model scores independent of non-linguistic context information through this process.
Different Domains For This Language Model
The computing system may then determine feature sets for the domain-specific model components.
Each of the domain-specific model components has a corresponding domain.
The domains represent different aspects of a non-linguistic context.
For example, different domains may represent different locations where a user may be located
with one domain representing New York City, another domain representing Paris, another domain representing San Francisco, etc.
As another example, domains may represent particular applications running on a device that receives spoken input. For example, one domain represents a maps application used for navigation, another domain represents an e-mail application, and so on.
Other examples of domains include different dialects that a user may speak, whether the user is in a vehicle, and the day of the week or time of day.
The domains may represent any appropriate type of non-linguistic context, such as:
- Location
- Time
- Weather
- Device status
- Movement status
- User characteristics
- Device characteristics
- Others
A domain may also represent multiple aspects of a non-linguistic context, e.g., a user in New York City on the weekend.
To train one of the domain-specific model components, the computing system accesses training data that includes examples of language sequences that occur in the domain of the model component to be trained.
For example, to train the model component as a domain for a speaker in New York City, the corpus containing input users while in New York City is accessed.
This corpus can include queries, dictations, or other user inputs that have been labeled as being entered in New York City.
For example, the corpus may include a set of queries submitted during a certain time range, such as the previous three months, by users in New York City.
The computing system may identify the examples for a particular corpus by selecting language sequences from a log, or other sources tagged or labeled as occurring in the particular domain.
The computing system can identify n-grams in the corpus for the domain of the model component being trained.
To train the model component for the New York City domain, the computing system may identify all of the unigrams and bigrams that occur in the examples in the New York City corpus.
The computing system also determines a count of how many times each n-gram occurs in the corpus.
From the identified n-grams, the computing system selects a subset to use in the model component for the New York City domain.
For example, the computing system may apply a threshold to select only the n-grams at least twice in the corpus.
Other thresholds may alternatively be used to filter the n-grams.
By applying a minimum threshold and selecting only a subset of the n-grams, the domain-specific model component focuses on the words and phrases that are most likely to be relevant to the domain and have sufficient training examples for weights to be trained.
The selected n-grams are used to define the features of the model component.
A separate model feature may be defined for each selected n-gram.
One bigram feature may be defined to represent the phrase “a restaurant” being entered in New York City. Another bigram feature may be defined to represent the phrase “a pizza” being entered in New York City.
The model component includes a parameter, such as a log-linear model weight, corresponding to each feature of the model component.
The parameters are all initialized at zero so that the model component initially does not influence the output of the language model.
Generating a language model score in this state would generate the output of the baseline model component alone, even when the model component is used.
Thus, before training the parameters of the domain-specific model components, the language model performs identically to the baseline model component.
The techniques for identifying n-grams, selecting a subset of n-grams, and establishing model parameters can be performed for each domain-specific model component, using its own corresponding corpus.
The n-gram features of each domain-specific model component are selected independently from different combinations of training data specific to each domain.
Through this process, a different set of n-grams can be selected for each domain.
As a result, each domain-specific model component can include weights for different n-gram features.
The n-gram features in each domain-specific model component are generally far fewer in number than the number of n-gram features of the baseline model component.
This allows the domain-specific model components to be trained with much less training data and also reduces the size of the resulting language model.
In stage (C), the computing system trains the domain-specific model components.
Each domain-specific model component can be trained separately using the examples in its corresponding corpus-710n.
For clarity, the training of a single model component is described.
The other domain-specific model components can be trained in the same manner.
The parameters of the domain-specific model component are trained using SGD, with the output of the language model being used to determine the gradient for SGD training.
The training examples used to train the model component are all from the corpus and match the model component’s New York City domain.
The baseline model component, which operates independent of non-linguistic domain information, is used to generate all outputs of the language model, regardless of which domain or domains the input information may be in. The domain-specific model component is also used to generate the output of the language model, but only when the non-linguistic context for the input to the model indicates that the corresponding domain is appropriate, e.g., when scoring language occurring in New York City.
When training domain-specific model components, the output of the language model, which is used as the gradient for SGD, is determined based on the features of the language context data and non-linguistic context data.
Thus, for a given training example, the gradient is based on the weights of the baseline model component and the weights of domain-specific model component(s) relevant to the training example, even though the weights of the baseline model component are fixed and not updated.
For each training example, the computing system can determine which domains are “triggered” by a match to the non-linguistic context of the training example.
When a domain is triggered or made active during training, the domain-specific model component for the domain is used to generate the scoring output by the language model used as the gradient for SGD.
Additionally, the domain-specific model component parameters for a triggered domain are updated through the SGD process.
On the other hand, domain-specific model components for not-triggered domains are not used to generate the output by the language model. Their weights are not updated based on the current training example.
During the training of domain-specific components, a single domain-specific model component is active and updated at a time.
For example, if a training example is labeled as corresponding to only one domain, the single domain-specific model component for that domain can generate the gradient and have its parameters updated based on the example.
Multiple domain-specific model components can be simultaneously used to generate the gradient and be updated based on the same example.
A particular training example may be labeled as the text of an utterance from a speaker located in New York City on the weekend, using a maps application.
Model components for three different domains may be used as a result (e.g., a New York City model component, a weekend model component, and a map application component.)
All three of these domain-specific components can be used to generate the gradient with the baseline model component. The parameters of one or all of the three domain-specific components can be updated based on the example.
Other training schemes are also possible.
For example, instead of training parameters of three triggered domains independently, an example that triggers three domains could be used to train each of the three domains separately.
While both the baseline model component and the domain-specific model component are used together to generate the output score of the language model, the parameters of the baseline model component are fixed. Therefore, they do not change while training the domain-specific model components.
Only the parameters of the domain-specific model component being trained are updated based on the domain-specific examples.
The baseline model component weights are used to compute the gradient in the SGD process, but the baseline model component weights are not adjusted in the SGD process.
In this manner, training data for specific domains or contexts do not improperly influence the baseline model component or decrease the accuracy for recognizing general, domain-independent speech.
Also, since the output of the language model always depends on the baseline model component, the various domain-specific model components learn to adapt or fine-tune the language model score in instances where domain information increases accuracy.
As training continues, the log-linear model weights of the domain-specific model component are adjusted, while the log-linear model weights of the baseline model component are not changed.
In some implementations, to improve training accuracy, the learning rate or size of the increment that parameters move during each training iteration can vary through training.
The learning rate may be gradually reduced during training, e.g., from 0.3 to 0.2, and then to 0.1 as training progresses.
This training approach provides several advantages.
The baseline model is not affected by the training for specific domains, so the accuracy of the language model does not degrade when used to evaluate data outside the adaptation domains.
There are a relatively small number of new features in each new adaptation domain, which results in small and computationally efficient domain-specific model components.
This allows a large number of domains to be served with the same language model.
The technique allows the language model to be easily extended to additional domains.
When adding a new domain-specific model component for a new domain, neither the baseline model component nor the existing domain-specific model components need to be altered.
Domain-specific model components can be easily and independently updated for the same reasons.
Further, a sample simultaneously belonging to multiple domains can be scored appropriately by the language model.
Although each domain-specific model component is trained separately, when an input belongs to multiple domains, the model components for multiple different domains can be used together to consider the simultaneous presence of multiple different domain-specific factors.
After training the language model, it can be used to generate scores for language sequences, e.g., to predict which language sequences are most likely.
Non-linguistic context information is used to select or “trigger” which domain-specific components should be active, e.g., used by the language model for scoring a particular language sequence.
Depending on the context information received, zero, one, or more different domains may be identified as matching the context.
Multiple domain-specific model components can be used simultaneously in the language model. For example, a user can be located in New York City and be using the Maps application.
In this instance, the New York City domain of the model component and the Maps application domain of the model component would be used simultaneously.
The domain-specific components for other domains not determined to be relevant would not be used.
Training a domain-specific model component
The process involves language models that include a baseline model component, a domain-specific model component, and a score generation module.
The process also involves a gradient analysis module and a parameter adjustment module.
The domain-specific model component is trained, while the baseline model component remains unchanged.
For clarity, a single iteration of training the domain-specific model component is illustrated.
Training generally involves many iterations using different training examples, and the same process can be used to train many different domain-specific model components of the language model.
Data indicating a training example is provided to the language model.
The training example indicates a language sequence and provides a linguistic context that can be used to determine which n-gram features should be made active to generate a language model score.
The training example also includes non-linguistic context information, e.g., indicating that the text was entered in New York City, which is the domain of the domain-specific model component.
The baseline model component can be general language models trained to predict language sequences based on linguistic context data, as discussed for the baseline model component.
The computing system’s baseline language model can be used to determine the likelihoods of language sequences based on the linguistic context data.
The baseline language model can be log-linear.
The domain-specific model component can also be a log-linear model.
The information about the training example is used to activate features of both the baseline model component and the domain-specific model component.
The language model uses the weights for n-gram features of both components that match the training example to generate a language model score.
For example, a score generation module of language models can use the weights of both components to determine the language model score, which can be provided to a gradient analysis module.
Only a single non-linguistic domain is triggered, and so only one domain-specific model component is used to generate the language model score.
When the non-linguistic context data for a training example matches multiple domains, then the domain-specific model component for each matching domain can be used to generate the language model score.
The gradient analysis module determines a gradient for SGD training using the language model score.
Information about the gradient is provided to a parameter adjustment module which determines weights of the domain-specific model component to adjust based on the gradient.
The parameter adjustment module may also determine the amount of adjustment, for example, by determining or setting an appropriate learning rate step for the adjustment.
While the weights of the baseline model component and the weights of the domain-specific model component are both used to generate the language model score and the gradient for SGD training, only the weights of the domain-specific model component are changed.
This preserves the accuracy of the baseline model component while training the domain-specific model component to adapt the output of the language model for a specific domain.
If multiple domains are triggered for a given example, then the parameters for the domain-specific model components of each of the triggered domains may be updated during the training iteration.
The same techniques can be used to train domain-specific model components for other domains.
For example, the domain-specific model component could alternatively correspond to a particular domain, such as the SMS application domain.
In the instance where the training data includes the phrase “hi Joe,” entered into an SMS application, the unigram feature of “hi” can be determined to be present by the computing system.
This unigram can be indicated to both the baseline model component and an SMS domain model component, and the output of both components can be used to determine a language model score.
The training process incrementally adjusts the value of weight for a particular feature based on the presence of the n-gram for the particular feature being present in the training example.
The parameter adjustment model can move the parameters toward the calculated gradient for each example corresponding to the particular feature.
A language model includes a baseline or background language model component and domain-specific model components for various domains.
The baseline or background language model component can have the features discussed above for baseline language model components.
The baseline language model component can be used to determine language model scores for all inputs, regardless of the non-linguistic context or domain involved.
One or more of the domain-specific model components may be selectively used with the background language model, depending on the non-linguistic context of an utterance.
Thus, the language model can determine whether each domain-specific model component should be used to adapt or adjust the output of the baseline model component, depending on whether the domains are currently relevant to the speaker’s situation whose utterance is being recognized.
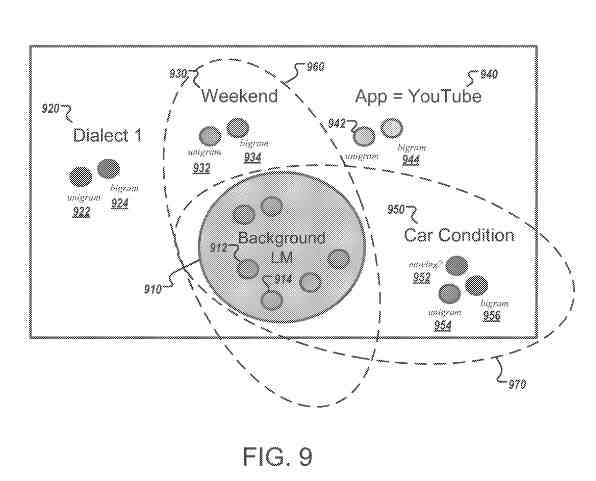
In some aspects, the language model includes domain-specific language models for:
- A dialect domain
- A weekend domain
- A YouTube application domain
- A car condition domain
The dialect domain represents the condition where a user speaks a particular dialect. The weekend domain represents the condition in which the user is speaking on the weekend. The YouTube application domain represents that the user is providing input to the YouTube application, and the car condition domain represents that the user is in a vehicle.
The domain-specific language models can include n-gram feature sets similar to the feature sets of the background language model.
Each domain-specific language model can have a unigram feature set and a bigram feature set.
For example, the dialect domain can include a unigram feature and a bigram feature.
The Weekend domain can include a unigram feature set and a bigram feature set.
The YouTube Application domain can include a unigram feature set and a bigram feature set.
The Car Condition domain can include a moving feature set, a unigram feature set, and a bigram feature set.
As such, the domain-specific language models can include multiple feature sets.
The language model can be used in an automated speech recognizer to recognize speech.
For example, the language model can be used to re-score a set of candidate transcriptions.
A first-pass language model (e.g., can provide data indicating candidate transcriptions.)
The first-pass language model may not consider a non-linguistic context, although, in other implementations, it may take into account non-linguistic context.
The first-pass language model may be a log-linear model or another type of model.
A subset of the candidate transcriptions, e.g., a particular of the most likely candidate transcriptions, such as the top 10, 20, 50, or another number, can be selected based on the language model scores first-pass model.
The language model can then be used as a second-pass model to generate a likelihood score for each candidate’s transcriptions in the subset.
Once the new language model scores are determined for the candidate transcriptions using the language model, a most likely transcription can be selected based on the scores.
For example, the candidate transcriptions may be ranked according to the likelihoods indicated by the scores from the language model, and the highest-ranked candidate transcription can be provided as a speech recognition result.
In some implementations, multiple candidate transcriptions are provided, e.g., the top three or five most likely candidate transcriptions, as determined from the language model scores.
The language model uses the baseline model component for each recognition.
The baseline model is adapted through the use of the domain-specific model components.
For a given utterance, zero, one, or more of the domain-specific model components are used, depending on the non-linguistic context that the utterance was spoken.
As discussed below, the scoring function changes, due to the combined use of different sets of model components, according to the domains considered to be active.
In general, the output score of the language model can be a probability score, such as the one given by the equation below.
P ( y | x ; w ) = exp ( wf ( x , y ) ) Z ##EQU00002##
This score gives the probability of a word, y, given a context, x, and the training state of the model, represented by weights w.
The numerator is a function of the weights, w, the context, x, and the word being predicted, y. The denominator, Z, represents a scaling factor, such as the sum of the values of all the weights, w, for all features in the model.
Each of the components of the language model may include one or more feature sets.
Each feature set represents a group of features having corresponding weights in the log-linear model.
For example, one feature set may represent unigram features. Another may represent bigram features. Another feature set may represent trigram features, and so on.
Still, other feature sets may represent backoff features, skip-gram features, or other types of features.
The baseline model component can include multiple feature sets and typically includes additional features that are not included in domain-specific model components.
The baseline model component may include unigram, bigram, trigram, and skip-gram feature sets, while domain-specific model components may include only unigram and bigram feature sets.
Feature sets of the baseline model component generally include many more features than corresponding feature sets of the domain-specific model components.
The unigram feature set for the baseline model may include many more features than the unigram feature set of a particular domain-specific model component (twice as many, or ten times as many, or more.)
When the non-linguistic context is not available, or if none of the domain-specific model components have a domain that matches the current non-linguistic context, then the baseline model component alone is used to generate the language model score.
The score, in this case, can be determined as indicated below.
P ( y | h ; w ) = exp ( w unigram ( y ) + w bigram ( y , h ) + w trigram ( y , h ) + + w skips ( y , h ) ) Z ##EQU00003##
The term h, represents linguistic context, such as prior words or surrounding words near the word, y.
This shows that the baseline model component uses only linguistic information, e.g., the word, y, being predicted and linguistic context, h.
Feature sets in the baseline model component are shown in the equation as different terms in the numerator, e.g., w.sub.unigram to represent the unigram feature set, w.sub.bigram representing the bigram feature set, w.sub.unigram representing the trigram feature set, and w.sub.skips representing a skip-gram feature set.
Other feature sets, or different combinations of feature sets, may be used.
For each feature set, the speech recognition system determines a feature vector based on the word, y, and the linguistic context, h.
The vectors can be binary vectors, with a value of “1” indicating that the feature is active and a value of “0” for not active features, e.g., not present.
Each feature vector is multiplied by the corresponding weight vector for the feature set.
Thus w.sub.bigram(y,h) represents the weights in the bigram feature set for the specific features active given y and h.
This process causes the numerator to include, in the exp ( ) function, the sum of all the weights for all active features over all of the baseline model feature sets.
The denominator Z represents the sum of all feature weights over all the feature sets for both active and non-active features.
The denominator thus represents the sum of all the weight values in the baseline model component.
When non-linguistic context data is available, the language model can dynamically alter the scoring technique based on which domains apply to the utterance being recognized.
For example, the map application model component can be used and the baseline model component if the user is providing voice input to a map application.
As another example, a New York City location model component can be used with the baseline model component if the utterance was entered in New York City.
Model components can be selected from among components for many different domains, such as:
- (i) regional dialect or accent domains, e.g., North African French, Canadian French, etc.
- (ii) time domains, e.g., weekend, weekday, daytime, nighttime, etc.
- (iii) location domains, e.g., New York City, Los Angeles, San Francisco, etc.
- (iv) movement status domains, e.g., user is walking, user is driving, user is stationary, etc.; (v) device domains, e.g., device characteristics or device status, such as whether the device receiving input is a smartphone, a wearable device, has a particular operating system, etc.
- (vi) user characteristic domains, e.g., user has a high-pitched voice, user is male, user is female, etc.
- (vii) ambient condition domains, e.g., high noise level, low noise level, etc.; and
- (viii) application domains, e.g., voice input provided to a map application, a media player application, a store application, a browser application, etc.
From among the different domain-specific model components, the speech recognition system determines which components correspond to the non-linguistic context for the utterance being recognized.
The baseline model component can be adapted using one or multiple of the domain-specific model components determined to be relevant to the utterance.
For example, GPS data or other location data may be used to determine that the utterance speaker is located in a particular city. Then the domain-specific model component for that city is selected to adapt the baseline model.
The language model score is then determined based on the linguistic context, h, and non-linguistic context, c, as shown below.
P ( y | h , c ; w ) = exp ( w unigram ( y ) + w bigram ( y , h ) + w trigram ( y , h ) + + w global 1 ( y , h , c ) + w global 2 ( y , h , c ) + ) Z ##EQU00004##
In this example, a domain-specific model component includes two feature sets, represented by w.sub.global1 and w.sub.global2.
A feature vector would be determined for each feature set and multiplied by the weight vector for each feature set.
This adds, within the exp( ) function, the weights from the feature sets of the adaptation domain and thus adjusts the overall likelihood determined for the word y relative to the likelihood that the baseline model component would indicate.
The feature sets of multiple domain-specific model components can be used together to simultaneously adapt the output of the baseline model component for multiple different domains. This technique uses the log-linear model weights of the selected domain-specific model component(s) in the same score calculation that the baseline model component log-linear weights are used.
The grouping shows the set of model components used when the weekend context is present, but other domains are not active.
The grouping shows the feature sets used when the user is determined to be in a vehicle, but the other domains are not active.
This shows how different model components are selected and incorporated into the scoring function discussed above, based on the non-linguistic context that has occurred.
In addition to using the feature sets and weights of the selected domain-specific model component(s), the denominator, Z, is also updated to reflect the addition of the domain-specific model component(s).
For example, rather than being a sum of all weights of the baseline model component only, the denominator can represent a sum of all weights over the baseline model component and all domain-specific model component(s) used.
Thus, over a series of utterances, as the non-linguistic context of the speaker changes, the domain-specific model components used and the scoring function of the language model also change.
The equation for P(y|h, c; w) discussed above can be used during the training of a domain-specific model component. However, in the SGD training process, the weights of the baseline model component feature sets, e.g., w.sub.unigram, w.sub.bigram, and w.sub.trigram, is held constant while the weights of the domain-specific model component feature sets, e.g., w.sub.global1 and w.sub.global2, are adjusted based on training example.
As discussed above, this maintains the integrity of the baseline model while learning adaptation parameters in the weights of the domain-specific feature sets.