





Google queries Real-time seo twitter
Google Gets Real Time Search Results Patent
Published: May 28, 2015
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

Google has partnered with Twitter to bring back real-time search results, to Google, with tweets from Twitter’s Fire-hose of data. Interestingly, a Google patent was granted this week at the US Patent and Trademark Office on Real-Time Search Results. It specifically refers to Status Updates of the type generated in Tweets from Twitter as a major source of real-time search results.
The patent tells us that the part of it that is innovative is in its decision to include real-time results in response to some queries, and providing those results. The patent also describes more information about how it may choose what to display as real-time results.
Related Content:
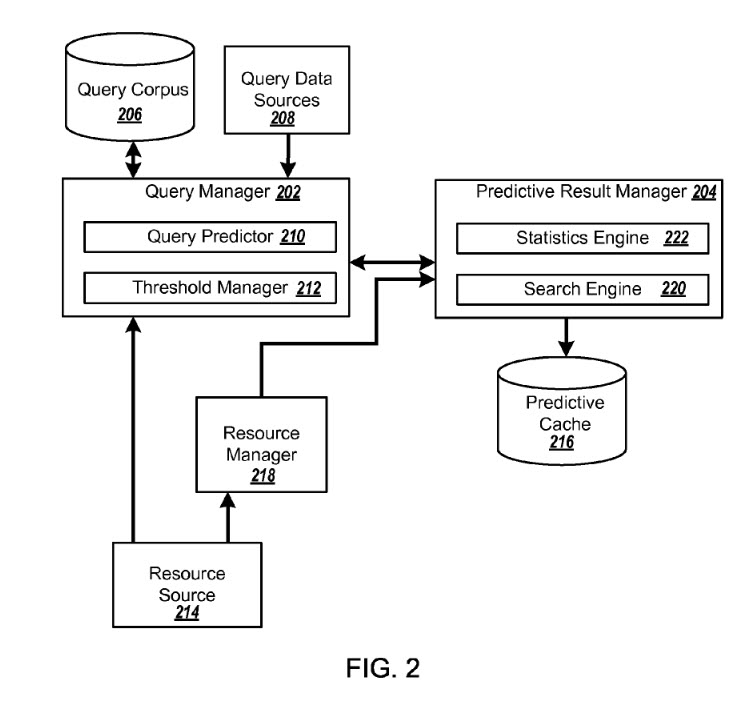
An image from the patent displaying part of the analysis of what to include in real time results
When Might Real Time Results Be Returned?
The patent starts by telling us that determining whether real-time search results should be included in a user interface document responsive to the search query includes:
- Receiving data for the search query;
- Generating one or more scores from the data; and
- Determining that each of the scores satisfies a respective threshold for the score.
The patent goes on to describe these in a little more detail, beginning with telling us that the data received for a query includes:
- A rate with which new documents responsive to the query are identified (a trend)
- One or more counts of common terms shared between resources responsive to the query(words that appear commonly mean something is up).
- Whether the query includes one or more terms that indicate a desire for real-time search results. (The data includes trend data on how often the query is submitted by users.)
- A number of terms in the query.
- A number of real-time search results responsive to the query.
Non-real-time search results may also be returned to a searcher
Query results may have a time-token attached to them that can indicate how new they are.
Google may have a cache in place for queries that might be responsive to queries to provide real-time search results, which might be retrieved from this cache. Results may be filtered within the cache to avoid duplicate results.
The patent refers to tweets as “status updates.”
Relevance of Real-Time Results
I’m trying to remember how relevant tweets were that were returned for searches when Google and Twitter originally teamed up back in 2009 to show tweets in real-time in response to queries. Usually, they seemed relevant, but not as in-depth detailed as non-real time documents returned in response to a query.
The patent tells us that providing real-time results may involve the creation of some scores to determine what should be shown. These could include:
- The actions of obtaining data for a status update
- The data including data indicating the quality of a user who submitted the status update
- A quality of the status update itself, and
- The relevance of the status update to a query
- Generating a query-specific score for the status update and the query from the obtained data
- Determining whether the status update is responsive to the query according to the query-specific score; and
- Associating the status update with the query when the status update is determined to be responsive to the query
The data that estimates the quality of a user who submitted the status update is data that can indicate whether the user is a spammer.
When the status update includes a reference, data might be looked at to estimate the quality of the status update by looking at a count of other status updates that include the same reference.
The patent tells us that the data estimating the quality of the status update is based upon some predefined rules that “define a high-quality status update.” These pre-defined rules can include:
- Good grammar,
- No strange characters, and
- No empty hash tags
Some additional steps involve determining whether a status update is responsive to a query according to the query-specific score can include comparing that score to a query-specific threshold.
These are steps that might be taken:
- The actions of identifying a search result that includes a status update comprising text;
- Identifying a reference to a web page in the text of the status update;
- Resolving the reference to the web page(for URLs that are shortened ones)
- Determining a title of the web page; and
- Presenting the text of a status update with the reference in the text of the status update replaced with the title of the web page.
We are told that when search results are presented, references that are URLs in those may be replaced with “the title of the web page and the domain of the web page.”
Advantages of the Process According to the Patent
The patent points these out as advantages to using the process described within it:
- Searchers may be presented with real-time search results – giving them the most up to date information on their queries.
- References in status updates may include URLs that are displayed as the title of a page linked to by the reference, providing more useful information.
- Short references, like those hosted by a URL shortening service such as bit.ly, can be resolved into more meaningful information.
- This system may filter out undesirable web pages such as pages that contain malware, pornography, or spam.
The patent is:
Generating real-time search results
Inventors: Brendan D. Burns, Lorenz Huelsbergen, Laramie Leavitt , Addy Ngan, Jack Menzel, Kumar Mayur Thakur, Vinod Ramachandran Marur, Adam Berenzweig
Assigned to: Google
US Patent 9,043,319
Granted May 26, 2015
Filed: December 3, 2010
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for generating real-time search results. In one aspect, a method includes: Receiving a search query from a client;
Determining that real-time search results should be included in a user interface document responsive to the search query;
Generating the user interface document, including client software to cause the client to present real-time search results for the query; and
Sending the user interface document to the client.
This system may keep potential answers to real-time queries within a cache where their duration of stay may be limited. A “query predictor” may be used to “identify potential queries from one or more query data sources and resource sources.” Potential query results may come from:
- Query logs
- Query trend data
- News articles
- Web documents, and
- Status updates
News Articles
These may involve recent or ongoing events, making them timely and good candidates to display information about. The patent has a large number of things it might score these upon in deciding to include them as real-time results. I’ve listed many of those below. A good number of them reminded me of Google’s patent on ranking articles for Google News.
Web Documents
I couldn’t help but think about the “In the News” results that Google sometimes shows these days in search results when I got to this part of the patent. Google does label and display some blog posts and articles as if they are newsworthy sources of information, and timely as well. The patent describes these potential real-time sources as:
For example, if at a point in time a news-worthy event occurs, such as an airline crash, a presidential election, or a final score of a football game, new incoming resources will generally include terms related to the event(s) in question. The query predictor can then compare terms across several different resources and formulate new queries that contain terms common to multiple resources. For example, in the example mentioned above regarding an airline crash, the query predictor can observe a frequent occurrence of the relevant flight number, a location of the crash, or other relevant information. The query predictor can then formulate predictive queries based on this information
Status Updates
The patent does describe some features that they look might look for in determining whether a tweet might be worth returning in real-time. It can involve looking at query logs for things people are searching for a lot, and Google trend data. Some other things could involve something like the name of a very famous person (it would need to be appearing very frequently to be triggered). Mentions like that might also trigger certain resources showing up if they come from specific reliable “trust resource sources”, we are told that these can include: “particular news organizations, blogs, forums, social networking sites, or other domains.”
Likewise, there may be some untrusted resource sources that result from might be filtered out of real-time results.
Queries Looking for Real-Time Results
The patent does discuss more information about scoring potential sources of real-time results, but it also discusses the characteristics of queries that might call forth such results. It tells us that those may look for certain signals that may trigger results that are responsive to them.
Do the queries include “signals of intent” for real-time results?
This could involve including the word “Twitter” in the query, of showing a “#” or a “@” or terms such as “latest” or “breaking”
Are the queries ones that are fresh?
If there are a lot of searches for a term or the trends data shows that it’s a topic that interests a lot of people it may be seen as a query that is fresh and should be served by real-time results.
Quality of News and Blog Sources
The patent also discusses the quality of News Articles and Blogs as sources for real-time results, in addition to status updates.
Some news sources might be considered a top tier resource, such as CNN, The New York Times, and the LA Times. or a second-tier source for lesser-known news sources, and even under a third-tier category such as local news organizations. Some other signals that might be used for news sources include:
Other example qualities listed in the patent for news sources include:
- Awards received by the source
- Third-party ratings of the source
- One or more of the number of articles published during the news source during a particular time period
- An average length of the articles published by the news source during a particular time period
- An amount of coverage of important topics that the news source provides
- The breadth of coverage of the news source
- The number of original named entities in articles published by the news source
- An amount of network traffic to the news source’s web site
- The number of countries from which the network traffic to the news source’s web site originates
- Circulation statistics for the news source
- A size of the staff of the news source
- The number of bureaus of the news source.
The first source to report on a topic, as determined by time stamps, may be rated higher. The originality of a source may also be ranked higher (are other’s copying that source?)
Some signals of quality for blogs may also be viewed to score those. These can include:
- How frequently the blog is selected as a result for any queries, or for the query looking for real-time results.
- How popular is the blog? Does it have many blogrolls linking to it? Does it link to well known or trusted blogs?
- Whether other sources link to the blog such as emails or chat documents.
- Short blog length – “an indicator of poor blog quality.”
- Tags used to categorize blog posts – “a positive indication of the quality of the blog.”
Third party ratings might be used also that could rate a blog upon things such as:
- The quality of the website,
- The originality of the content of the blog,
- The information available on the blog,
- The layout of the blog,
- The correctness of grammar or spelling used,
- Whether obscene or inappropriate material is presented, and
- Whether blank or incomplete pages are present.
Those rankings might be for either “individual pages of the blog, or for the blog as a whole.”
A high level of subscriptions to a blog” RSS feed could also be used as another metric, or as the patent says, “High blog subscription can be a signal of blog quality.”
The patent also tells us that rating might be done based upon certain aspects of the blog, such as:
- The frequency of new posts on the blog document,
- The content of posts in the blog document,
- The size of the posts in the blog document,
- The link distribution in the blog document, and
- The presence of ads in the blog document.
Quality of Status Updates
These might include information about the people submitting those updates, and the updates themselves.
Some signals might indicate that the person posting them is a spammer, such as:
- How often the user posts status updates,
- The pattern with which the user posts status updates over time, or
- The content of status updates posted by the user over time.
Do they make posts at a frequency that exceeds a certain threshold? Do they have a pattern of posting status updates in spurts? Do they make a habit of posting using commercial terms or other terms that tend to be associated with spam, such as the term “Viagra?” the system can consider the user a likely spammer. Do they use certain terms more than a pre-determined amount of time in a certain period?
If the person tends to point to a particular reference, over a certain threshold number of times, that could be an indication that they have an interest in that reference and might be seen as a positive thing.
Status updates that refer to a particular web page, might look at the quality score for the page being linked to and those updates might be given a higher score.
Or, an overall score might be given for status updates that measure their overall quality on certain predefined rules such as:
- They do not contain strange characters.
- They are written using good grammar.
- They do not contain any empty hashtags.
I will be keeping an eye on real-time search results and trying to determine if this patent does a good job of describing the kinds of things Google might show as realtime results in responses to queries. I’ll also be keeping an eye on the queries that trigger real-time response, to try to understand why they might. If you have any thoughts about Google’s real-time search results, please let us know.