





How Might Google Extract Entity Relationship Information from Q&A Pages?
Published: October 29, 2019
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url
How helpful might question and answer websites be in providing a search engine with information about entities, and entity-relationship information about those entities and other entities and properties of entities?
A recently granted patent from Google looks at such potential sources of information and tells us more.
One of the inventors of this patent, Evgeniy Gabrilovich, worked on Google’s knowledge vault project which talks about things such as extracting relationship information from text on the web about entities. It’s worth looking at a presentation that was prepared during the development of the knowledge vault project to see what it says about extracting entity-relationship information from the Web. That can be found at: Constructing and Mining Web-scale Knowledge Graphs
Related Content:
Candidate Relationships Between Entities
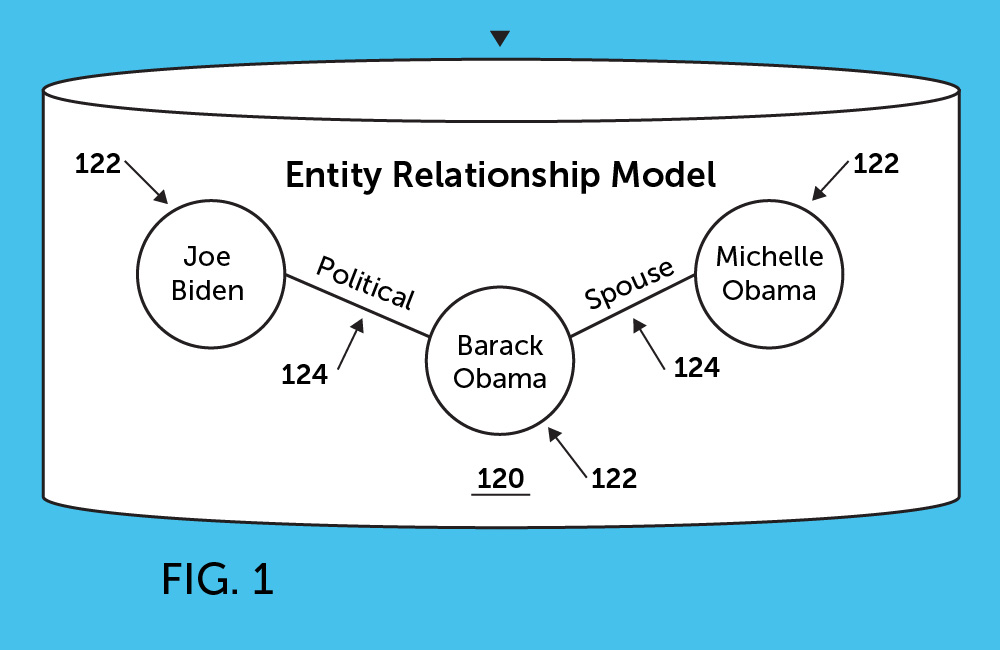
That patent, granted to Google October 22, 2019, tells us about how such sites can be used as resources to provide information about relationships between entities, such as “Who is Barack Obama married to?” That page may also include the answer, “Michelle Obama,” on it as well.
The patent points out that such pages may identify entity relationships by looking at the question involved:
A relationship type is determined based on the question text, for example, by determining that the terms “married to” in the question text likely indicate a spousal relationship between an entity indicated in the question text and an entity indicated in the answer text. Entities are also identified from the question text and the answer text. For example, the computer system can identify the entity “Barack Obama” from the question text, and the entity “Michelle Obama” from the answer text.
Having identified a relationship type and the two entities identified by the question and answer text, a candidate relationship is determined. For example, the determined candidate relationship may be a spousal relationship between the entities “Barack Obama” and “Michelle Obama.”
Moving from Possible Answers to Candidate Answers
The patent tells us that a Q&A site may possibly indicate a number of potential answers to a question about a spousal relationship with Barack Obama, which could include “Michelle Obama,” “Hillary Clinton,” or “Laura Bush.”
How might Google Decide which candidate answer is most likely?
Google may score each of the candidate relationships based upon a “frequency with which the candidate relationship was determined from the webpages of Q&A Websites. The patent tells us that:
The candidate relationship having the highest score is selected as the most likely valid relationship for the particular relationship type and entity. For example, based on determining that the candidate spousal relationship between “Barack Obama” and “Michelle Obama” is the most frequently occurring spousal relationship for the entity “Barack Obama,” the computer system determines that a spousal relationship exists between “Barack Obama” and “Michelle Obama.” The computer system can then establish, in an entity-relationship model, a spousal relationship between the entity “Barack Obama” and the entity “Michelle Obama.”
What is innovative about the process described in this patent? It tells us that these steps are:
- It involves the actions of obtaining a resource
- Identifying the first portion of text of the resource that is characterized as a question
- The second part of text of the resource that is characterized as an answer to the question
- Identifying an entity that is referenced by one or more terms of the first portion of text that is characterized as the question
- A relationship type that is referenced by one or more other terms of the first portion of the text that is characterized as the question
- An entity that is referenced by the second portion of text that is characterized as the answer to the question
- Adjusting a score associated with a relationship of the relationship type for the entity that is referenced by the one or more terms of the first portion of text that is characterized as the question and the entity that is referenced by the second portion of text that is characterized as the answer to the question
This process uses question and answer (Q&A) websites
It looks at questions as templates to identify the first entity and the relationship type displayed in the question, which each template on the Q&A site may be associated with a particular relationship type.
This entity relationship information patent can be found at:
Information extraction from question and answer websites
Inventors: Wei Lwun Lu, Denis Savenkov, Amarnag Subramanya, Jeffrey Dalton, Evgeniy Gabrilovich, Eugene Agichtein
Assignee: Google LLC
US Patent: 10,452,694
Granted: October 22, 2019
Filed: December 20, 2017
Abstract
Methods, systems, and apparatus for obtaining a resource, identifying a first portion of text of the resource that is characterized as a question, and a second part of text of the resource that is characterized as an answer to the question, identifying an entity that is referenced by one or more terms of the text that is characterized as the question, a relationship type that is referenced by one or more other terms of the text that is characterized as the question, and an entity that is referenced by the text that is characterized as the answer to the question, and adjusting a score for a relationship of the relationship type for the entity that is referenced by the one or more terms of the text that is characterized as the question and the entity that is referenced by the text that is characterized as the answer to the question.
Entity Relationship Information Models
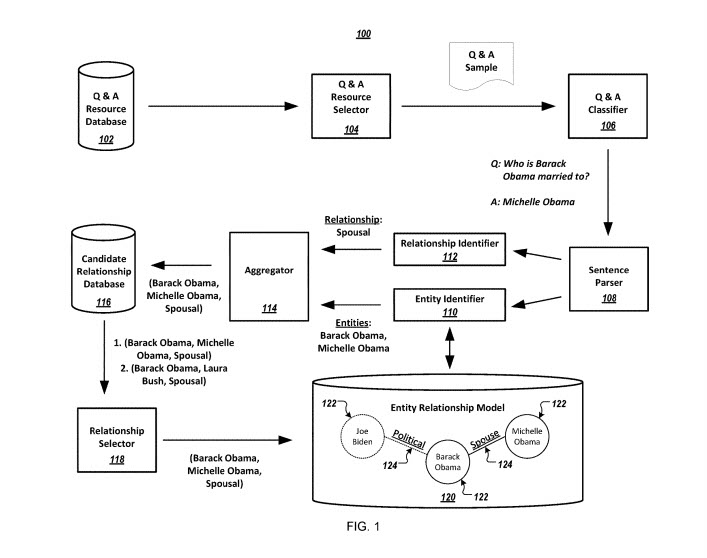
The focus of this patent is upon building an entity-relationship model that specifying relationships that are determined Q&A website resources.
This system includes:
A Q&A resource database
A Q&A resource selector
A Q&A classifier
A sentence parser
An entity identifier
A relationship identifier
An aggregator
A database of candidate relationships
A relationship selector
An entity-relationship model.
Entities represented in the entity-relationship model may be represented as nodes, with relationships between entities being represented as edges. The confidence scores about the entity relationships are an indication of a likely accuracy of those relationships being true.
When extracting entity-relationship information from Q&A website resources, this system may look at a Q&A resource database that includes multiple resources from Q&A websites.
Those resources can include:
- A number of webpages from Q&A websites0, such as archived versions of the webpages from Q&A websites
- Metadata relating to webpages of Q&A websites
- Documents accessible at Q&A websites
- Images accessible at Q&A websites
- Videos accessible at Q&A websites
- Audio accessible at Q&A websites
- Other resources associated with or accessible at Q&A websites
The Q&A resource database can also include resources from sources other than Q&A websites, such as:
- One or more resources from forum websites
- Social network platforms
- Frequently asked questions (FAQ) websites or FAQ webpages
- Informational websites
- Other sources where questions and answers are available
When this question identifier is looking for questions and answers that identity entities and relationships between them, it may start parsing text on a Q&A page to find the presence of certain characters or strings of characters, such as a question mark. It may also look for words or questions that indicate question text such as:
- “I was wondering”
- “I am asking”
- “question”
- “who”
- “what”
- “where”
- “when”
- “why”
- “how”
- etc.
In the same way, When answers are looked for, text on pages may be parsed to find words that might indicate answer text, such as:
- “I know”
- “I believe”
- “I think”
- “The answer is”
- “answer”
- etc.
The part of this process that involves parsing text on a page on a natural language processing approach that tags parts of speech:
As an example, the sentence parser may receive the question text, “Who is Barack Obama married to?” and may annotate the question text as “WHO/pronoun IS/verb BARACK OBAMA/noun MARRIED/adjective TO/verb?” Similarly, the sentence parser may receive the answer text “Michelle Obama” and may annotate the answer text as “MICHELLE OBAMA/noun.” The sentence parser may further determine a class or hypernym of one or more grammatical units in the annotated texts, for example, to determine that the terms “Barack Obama” constitute a “person” noun class and that the terms “Michelle Obama” also constitute a “person” noun class.
Having parsed the question and answer texts, the sentence parser provides the annotated question and answer texts to the entity identifier and relationship identifier. In alternate implementations, the question text and/or answer text may be provided to the entity identifier and relationship identifier without processing by the sentence parser. In such implementations, the entity identifier and/or relationship identifier may perform operations similar to those performed by the sentence parser or may identify entities or relationships from the question text and/or answer text without the question text or answer text being annotated. In such instances, the Q&A classifier can provide the question and answer texts to the entity identifier and relationship identifier.
The question text and the answer text that are identified can identify the type of entity-relationship being asked about and answered on a Q&A page.
Another example of how an answer might be parsed from question text and answer text:
For example, the entity identifier may receive the question text “Who is Barack Obama married to?” and identify the entity “Barack Obama,” and may receive the answer text “He lives with his wife Michelle Obama at the White House” and identify the entities “Michelle Obama” and “White House.” The entity identifier may determine that the entities “Barack Obama” and “Michelle Obama” are each of a “person” noun class and that the entity “White House” is of a “place” noun class. The entity identifier may select the entities “Barack Obama” and “Michelle Obama” as potentially related entities based on both entities being of the “person” noun class, and therefore being more likely to be related in some way than a particular person is to be related to a particular place.
What other kinds of entity-relationship information may be found using an approach like this?
- Spousal relationships
- Familial relationships
- Political relationships
- Business relationships
- Ownership relationships
- Residence relationships
- Birth place relationships
- Employee/employer relationships
- Occupational relationships
- Other relationships between people, places, or things
Some other types of Entity Relationship Information
Between particular entities and numerical values or dates. Such numerical values may include:
- A person’s age
- Net worth
- Jersey number
- Height
- Date of birth
- Marriage date
- Date of death
- Date of founding a Business
- City with a population size
- etc.
A “matcher” may determine if a particular question fits with a particular template accessible by the relationship identifier, making a template such as, “Who is [PERSON] married to?” a relationship to collect information about.
The patent tries to make a point telling us that these templates would try to match the right types of entities with templates, so an entity that may indicate a place might not work with a relationship identifier that determines a spousal relationship type, by providing the example: “Who is America married to?”
So I tried that Query, and got an unexpected answer:

Conclusion
Google just announced that it was using a natural language processing approach called BERT. I mentioned that approach when I wrote the post Semantic Frames and Word Embeddings at Google back in May. This patent provides a good example of how natural language processing might be used to understand questions and answers on Q&A pages, and whether those fit some known templates to identify relationships between entities and properties of entities.
The patent does provide some additional examples of how it might try to gain more of a sense of confidence about the relationships between entities or properties of those entities. But this patent is fairly descriptive of how entity-relationship information may be extracted from Q&A websites.