


Entity Clustering in Google Search Results
Published: December 31, 2019
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

A patent granted to Google at the start of this month is about making search results more diverse, by engaging in entity clustering for those search results.
This diversification isn’t done by efforts such as 2019’s domain clustering or category diversity as we saw with a patent involving local search results recently.
Entity Clustering in Search Results
This new patent is about clustering involving entities.
I wrote about another patent on clustering search results by the entities in them. That one was about when someone selected results about one type of entity, and the search engine would then remove other results about other entities. The post I wrote was Clustered Entities in Google’s Search Results. That blog post told us about a patent in a search for “Penguins” in which the search engine might recognize that there is a hockey team named the Pittsburgh Penguins, a publisher named Penguin, and the types of birds known as Penguins. If a searcher chose to look at results about the birds, Google might remove results involving the hockey team and the publishing house.
Related Content:
That type of clustering and removal isn’t how the process in this new patent about entity clustering works.
Instead, this patent tells us about what it calls “an improved system for clustering search results.”
It may use entities in a knowledge base to form clusters of similar responsive search items. These entities may be classified in an entity ontology, which would mean that parent-child and synonym relationships are known between entities.
Items in search results could then be mapped to one or more of the entities. Search for a Jaguar, and Google may think you mean either a cat-like animal, a type of car, or a member of an American Football team from Florida.
Google may determine which search result is related to which entity and then how it might cluster the results around specific entities together to display them in search results to a searcher. It may decide to show all of the Jaguar Car results, and then the Jaguar Cat results, and then the Jaguar Football results.
As a first step search items that are responsive to a query could then be clustered by entity so that each cluster is about responsive search items that are associated with one particular entity.
This search system may next merge those clusters based on an entity ontology, where the entities are:
- Synonyms for each other
- A parent-child
- Siblings
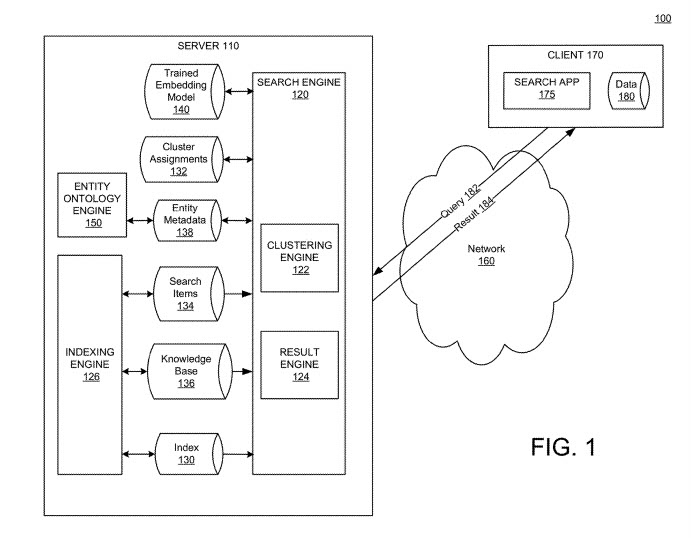
A search result entity clustering system
The system in the patent may be used to generate an entity ontology and use the entity ontology to cluster search results before presentation to a searcher.
The example in the patent is described as a system for searching for applications in a web store, but it can be applied wider than that. The search items may be any:
- Products sold in a marketplace
- Documents available over a network
- Songs in an online music store
- Images in a gallery
- Etc.

The patent goes on to tell us about the different features that may be involved in entity clustering.
It starts by telling us that the entities that may be searched for can be any items in a collection.
These can include:
- Documents available over the Internet
- Documents available on an Intranet
- Mobile applications
- Web applications
- Plugins via a web store
- Songs in an online music store
- Items for sale via an online marketplace
- Etc.
Google’s indexing engine may use the knowledge base to associate search items with entities in the knowledge base.
Those search items may include:
- Annotations
- Descriptions
- Other text associated with a search item
- The item may itself include text (e.g., when the item is a document)
That mapping may be stored in the index, in entity metadata, or as cluster assignments.
Each search item in search items may map to one or more entities in the knowledge base.
Only a predefined number of entities may be mapped to a search item, (possibly 5 at the most)
That mapping could be based on a relevance score, indicating the relevance of the entity to the search item and only the most relevant entities (e.g., those with a relevance score meeting a threshold) are mapped to the search item.
Entity Clustering Scores – Similarity
For example, the system may give all entities related to a search item via text a score ranging from 0 to 1, with 1 representing the highest relevance between the search item and the entity. (This sounds like an entity salience score.)
The system may then use a machine-learning algorithm to generate an embedding for the search item using these scores.
The embedding space is represented by a trained embedding model.
In the embedding space, each search item and entity is represented as a point in high-dimension space.
The system may use this embedding space (trained embedding model) to determine the similarity between search items or entities by using the distance between points.
The distance refers to how closely related two objects (search items or entities) are.
A Knowledge Base in the Entity Clustering System
The search result clustering system may include a knowledge base.
That knowledge base conventionally stores information (facts) about entities.
Those entities may represent a:
- Person
- Place
- Item
- Idea
- Topic
- Abstract concept
- Concrete element
- Other suitable thing
- Any combination of these
Each of those entities may be represented by a node in the knowledge base.
Relationships between Entities in the Knowledge Base
Entities in the knowledge base may be related to each other by edges (which connect them.)
Those edges may represent relationships between entities, i.e., facts about entities.
As an example, the data graph that the knowledge base is showing off may have an entity that corresponds to the actor Humphrey Bogart and it may show the relationship between the Humphrey Bogart entity and other entities representing movies that Humphrey Bogart has acted in.
Those facts may also be stored in a tuple, such as .
The knowledge base may also store some facts about an entity as attributes of the entity.
As an example, the knowledge base may include a birth date for the entity Humphrey Bogart.
Attributes may also be considered labeled relationships for the entity, linking the entity to an attribute value.
So knowledge about an entity could be represented as labeled relationships between entities and labeled relationships for an entity.
A knowledge base with a large number of entities and even a limited number of relationships could have billions of connections.
Not all of the entities represented in the knowledge base may relate to the search items.
An Entity Ontology Engine
An entity ontology is a set of relationships that link entities as either synonyms or as parent-child.
In an entity ontology, an entity may be related to one or more other entities as a synonym or a hypernym, i.e., as the parent of the other entity, or as a child of the other entity.
The entity ontology may be stored as named relationships in the knowledge base (e.g., an edge representing a synonym, ontologic child, or ontologic parent between entities.)
The entity ontology may be stored in entity metadata.
The entity ontology, or in other words the synonym and parent/child relationships, maybe curated by hand.
The system may include an entity ontology engine that proposes relationships that may be verified by hand.
That verification may take the form of crowdsourcing.
The entity ontology engine may be provided with a subset of entities from the knowledge base that is relevant to the search items.
In a small knowledge base, the subset may be all entities, but in a large knowledge base (e.g., millions of entities), the subset may represent entities that are mapped to the search items in search items.
The subset may be the entities mapped most often to search items, e.g., entities mapped to a plurality of search items may be selected over those that map to only one search item.
A system such as Mechanical Turk might be used to do crowdsourcing to verify the relationships between candidate entities. It may be used to label a candidate pair as a synonym of a parent/child/sibling. The first entity is a co-hypernym of the second entity when the first entity and the second entity have the same parent.
Why Cluster Entities using a system like Described in this patent?
Clustering the responsive search items improves the user experience by providing a natural logical structure within the responsive search items to maintain and display diversity represented by responsive items.
Using entity ontological relationships to cluster the search items improves the clustering by better simulating nuanced search item similarity not captured in conventional hierarchical clustering methods.
Thus, the clustering engine may cluster responsive search items using entity ontological relationships.
A search item may be mapped to one or more entities, e.g., via entity metadata or as metadata in the search items.
The clustering engine may use the mapping to generate the first-level clusters.
Because a search item may be mapped to more than one entity, the search item may be included in more than one first-level cluster. As indicated earlier, each first-level cluster includes responsive search items mapped to an entity that represents the cluster.
Advantages of Using this Clustering Approach Based Upon Entities
- The system provides a similarity metric, evaluation criteria, and a clustering method suited for searching applications in a web store, although searching in other domains can also benefit from this disclosure
- Provide coherent clusters of search results, providing a logical structure within the results, enabling the query requestor to easily explore the search items responsive to the query, and ensuring variety is apparent to the requestor/li>
- Implementations easily scale to large search systems because the assignment to categories does not rely on manual assignment or clustering/li>
- May provide a flexible, optimization-based framework running multiple ontology-based clustering algorithms to provide an optimal output/li>
This patent can be found at:
Clustering search results
Inventors: Jilin Chen, Peng Dai, Lichan Hong, Tianjiao Zhang, Huazhong Ning, and Ed Huai-Hsin Chi
Assignee: GOOGLE LLC
US Patent: 10,496,691
Granted: December 3, 2019
Filed: September 8, 2015
Abstract
Implementations provide an improved system for presenting search results based on entity associations of the search items. An example method includes generating first-level clusters of items responsive to a query, each cluster representing an entity in a knowledge base and including items mapped to the entity, merging the first-level clusters based on entity ontology relationships, applying hierarchical clustering to the merged clusters, producing final clusters, and initiating display of the items according to the final clusters. Another example method includes generating first-level clusters from items responsive to a query, each cluster representing an entity in a knowledge base and including items mapped to the entity, producing final clusters by merging the first-level clusters based on an entity ontology and an embedding space that is generated from an embedding model that uses the mapping, and initiating display of the items responsive to the query according to the final clusters.
Entity Cluster Evaluation Metrics
The patent tells us about several factors that might be used to determine cluster evaluation metrics.
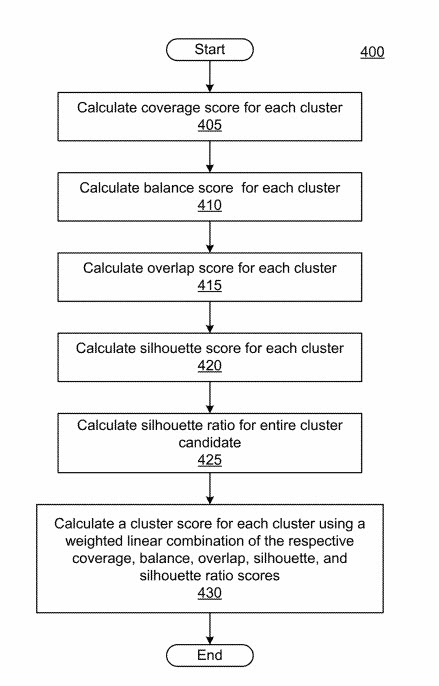
Coverage Score
A coverage score measures the percentage of top-ranked, popular, or relevant search items that the clusters cover.
There are several ways to determine whether a cluster-based upon an entity might be top-ranked or popular.
- Search items that are applications in a web store may be top-ranked or popular when they are installed after appearing in search results for a search.
- Items in a marketplace or songs available for purchase, the top-ranked or popular items may also be those items purchased after a search.
- A document in a repository (e.g., webpage, image, or video) may be top-ranked or popular when it is selected from a search result presented to the user.
- An item may also be considered popular based on indicators from social media.
The search records may keep statistics and metadata about queries and responsive search items submitted to the search engine without storing any personally identifying information or may anonymize such information, for example by storing a city or zip code for the query information only. A higher percentage of conversion or in other words the more popular/top-ranked search items the clusters include, the higher the coverage score for that cluster.
Balance Score
A high balance score means the clusters are of equal or similar size.
High balance indicates the most popular/top-ranked search items appear fairly evenly across the clusters.
Overlap Score
An overlap score measures how many duplicate search items are included in different clusters. A search item may be included in more than one first-level cluster (e.g., a cluster for an entity). As the clusters are merged through one or more rounds, the search item may still appear in more than one cluster. A high overlap score, e.g., indicating a high number of search items in more than one cluster, is undesirable.
Silhouette Score
A silhouette score measures how coherent and separate a cluster is. The clustering engine may thus calculate a silhouette score for each cluster.
A silhouette score of a single cluster has two components: first, a self-similarity among the search items within the cluster; and second a similarity between search items from the cluster to the nearest neighbor cluster.
The nearest neighbor is understood to be another cluster that is most similar to the cluster, usually determined by a similarity score (e.g., embedding similarity or other similarity scores).
For a cluster score to be high (e.g., desirable or of high quality), a cluster should be highly self-similar but not similar to its nearest neighbor.
In other words, a cluster should be coherent (self-similar) and separate (not very similar to its nearest neighbor).
Silhouette Ratio Score
A silhouette ratio score measures the coherence and separation of the overall clustering result. The silhouette ratio score represents the percentage of clusters in the clustering result with a silhouette score above a predefined threshold. The higher the percentage, the better quality the overall clustering result, e.g., the clusters for the current round or level.
Overall Cluster Score
The cluster score for a cluster may be a combination of one or more of the five metrics outlined above. The cluster score for a cluster may be a regression of the five metrics. The weight may be implementation-dependent, reflecting how important any one metric is to the overall quality of the clustering result.
Entity Clustering Takeaways
The patent provides several additional details regarding which entity clusters might be shown and when.
I was reminded by this patent about how images are being categorized by Google, and clustered using ontology information, which I wrote about in Google Image Search Labels Becoming More Semantic?
If you want a good example of how search results (in the form of images) can be clustered and organized using an entity ontology, looking at the categories Google uses in image search is an example worth looking at.
See the Google image search categories organized in an ontology for an entity such as [SEO].

At present, it isn’t very clear that Google is using an entity clustering approach in organic web search results (though a search for [jaguar] and you will see mostly car-based results and a search for [jaguars] and you will see mostly NFL Football results, with some Jaguar Cats results mixed into Search Results for both.)
It may be worth studying search results to see how entities with similar names appear in search results at Google, to tell how much clustering might be taking place.