


Answering Questions Using Knowledge Graphs
Published: October 14, 2019
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url
Knowledge Graphs are Becoming More Popular
I’m seeing several articles, and a patent about answering questions using Knowledge Graphs.
I’ll share the articles first, and then provide more details about the Google Patent that I mentioned in a presentation last week at Pubcon. I will also include my presentation from Pubcon in this post as well since it focuses upon the evolution of Question-Answering. The patent involving answering questions using knowledge graphs is the latest patent from Google in that evolution.
Related Content:
This article tells us more about the popularity of knowledge bases and knowledge graphs: Why Knowledge Bases Are The Next Big Thing
Krisztian Balog has been a visiting scholar at Google until recently, and he wrote an interesting paper that is worth spending time on: Personal Knowledge Graphs: A Research Agenda. He also wrote a book that is available at no cost which is highly recommended reading: Entity Oriented Search.
Knowledge graphs can be used to provide richer knowledge panels in search results and return answers to queries in search results. Still, a personal knowledge graph is different from most other knowledge graphs:
The figure illustrates three key aspects of PKGs that separate them from general KGs: (1) PKGs include entities of personal interest to the user; (2) PKGs have a distinctive shape (“spiderweb” layout), where the user is always in the center; (3) integration with external data sources is an inherent property of PKGs
On the Amazon Alexa Blog, we also see Teaching Computers to Answer Complex Questions. H/t to Nicolas Torzec for sharing a link to that on Twitter. This blog post starts by telling us:
In a way, our technique combines the two standard approaches. Based on the input question, we first do a text search, retrieving the 10 or so documents that the search algorithm ranks highest. Then, on the fly, we construct a knowledge graph that integrates data distributed across the documents
It then shows us how it tries to keep the highest confidence connections from the graph to work towards an answer (keep that in mind when looking at the Google patent, and a previous one from Google that discusses association scores between entities, attributes, and other related entities.)
The Evolution of Answering Questions at Google
Before providing more details on the Google approach to question answering using knowledge graphs, I am going to share my Pubcon presentation here:
Before I provide more details about the patent that uses knowledge graphs to answer questions, I ideally need to point out an earlier post that tells us about how Google extracts entities from pages on the web.
What makes the patent (Computerized systems and methods for extracting and storing information regarding entities) from that post interesting is that it tells us about association scores between those entities, and properties for them, and other entities that might be related to them.
Those association scores are confidence scores that the relationships between those entities and facts between them are likely to be correct (“An association score may reflect a likelihood or degree of confidence that an attribute, attribute value, relationship, class hierarchy, designated context class, or other such association is valid, correct, and/or legitimate”)
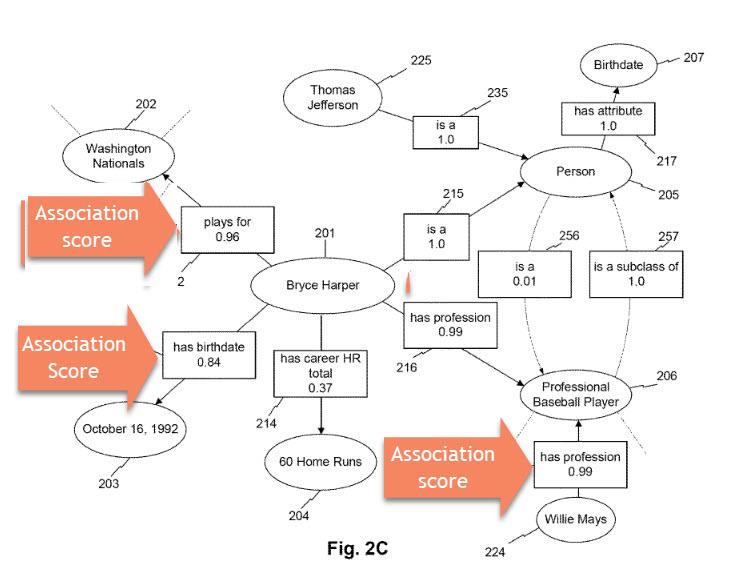
There are a number of different weights that association scores are based upon. These weight can indicate how much confidence Google may have in the facts that are being extracted:
- Temporal Weights
- Reliability Weights
- Popularity Weights
- Proximity Weights
Here’s the more technical language from the patent that tells us the details about association scores:
For example, as explained in greater detail below, a computing system (e.g., server 110) may determine association scores using factors and weights such as the reliability of the sources from which the association score is generated, the frequency or number of co-occurrences between two entities in content (e.g., as a function of total occurrences, the total number of documents containing one or both entities, etc.), the attributes of the entities themselves (e.g., whether an entity is a subclass of another), the recency of discovered relationships (e.g., by giving more weight to more recent or older associations), whether an attribute has a known propensity to fluctuate (e.g., periodically or sporadically), the relative number of instances between entity classes, the popularity of the entities as a pair, the average, median, statistical, and/or weighted proximity between two entities in analyzed documents, and/or any other process disclosed herein. In some aspects, the system may itself generate one or more association scores. In certain aspects, the system may preload one or more association scores based on pre-generated data structures (e.g., stored in databases 140 and/or 150).
When Google extracts entity information from Web pages, it also generates association scores involving those entities and their relationships with other entities, and with facts about them describing properties of those entities. Keep that in mind when you read about the next patent:
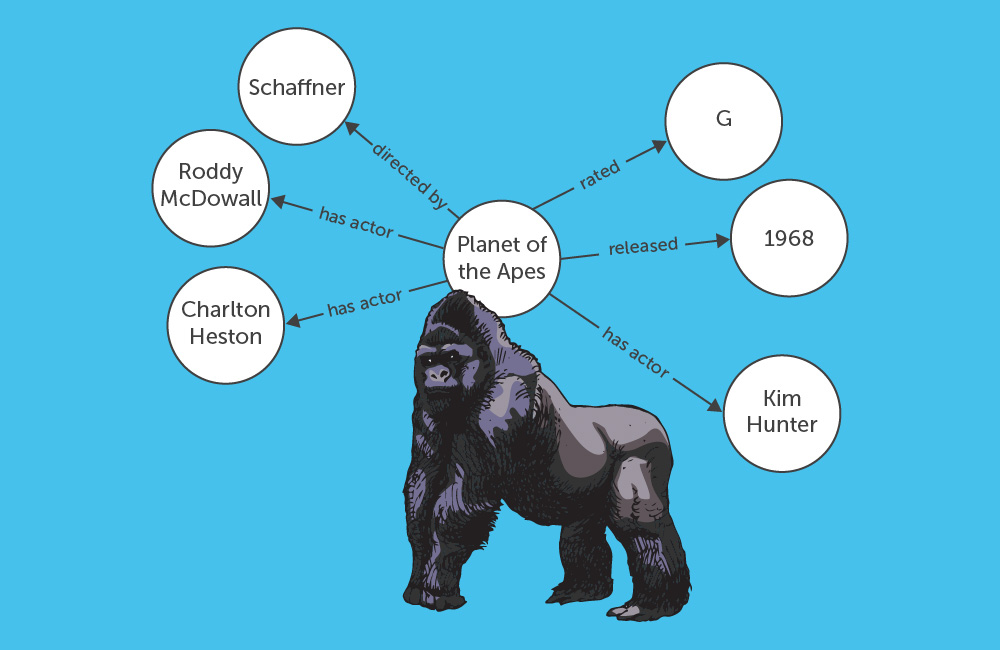
Knowledge Graph Question Answering
Google was granted a patent that shows how it might answer questions using knowledge graphs, using machine learning.
The steps involved include:
- Use a question as a Query
- Collect the SERPs from that Query
- Break Pages from those SERPs into tuples
- Generate Association Scores for those tuples
- Build a Knowledge Graph From those tuples
- Answer the Question
This patent tells us that “Natural Language Processing (NLP) can involve answering natural language questions based on information contained within natural language documents.”
To accurately answer such questions might require semantic parsing of natural language questions and the documents that might be used to answer those questions. In addition to the kind of entity extraction I wrote about previously, and the creation of association scores, it can also involve trying to understand the question being asked, which I detailed more in a post about providing semantic interpretations of questions and pages to interpret the intent behind those questions, as I described in How Google May Interpret An Ambiguous Query Using a Semantic Interpretation That post tells us about how ambiguous questions might be interpreted.
Answering such questions accurately can often require semantic parsing of both natural language questions and documents that might be used to answer those questions.
The reason for this newest patent is the difficulty in performing question-answering in an automated way. The patent tells us that:
Effective semantic parsing often relies on a human-curated knowledge base with the manually defined schema. This approach, however, can be labor-intensive, which can make it expensive to both develop and maintain.
The patent tells us that there are some advantages to using the knowledge graph question-answering process described in this patent that include:
-
- The process in the patent works by obtaining a natural language processing model that includes an encoder model, a decoder model, and a programmer model
- The encoder model can receive a natural language text body and, in response to receipt of the natural language text body, output a knowledge graph
- The decoder model can receive the knowledge graph and, in response to receipt of the knowledge graph, output a reconstruction of the natural language text body
- The programmer model can be trained to receive a natural language question, and, in response to receipt of the natural language question, output a program
- The computer-implemented method can include inputting, by computing devices, a training data set that comprises the natural language text body and the natural language question into the natural language processing model to receive an answer to the natural language question
- The computer-implemented method can include evaluating, by computing devices, a total objective function that comprises an autoencoder objective function and a question-answer objective function
- The autoencoder objective function can describe a reconstruction loss between the natural language text body and the reconstruction of the natural language text body
- The question-answer objective function can describe a reward that is based on a comparison of the answer and an expected answer included in the training data set
- The computer-implemented method can include training, by computing devices, the natural language processing model based on the total objective function
This natural language processing approach is described in the patent application at:
Natural Language Processing With An N-Gram Machine
Pub. No.: WO2019083519A1
Publication Date: May 2, 2019
International Filing Date: October 25, 2017
Inventors: Ni Lao, Jiazhong Nie, Fan Yang
Abstract:
The present disclosure provides systems and a method that performs machine-learned natural language processing. A computing system includes a machine-learned natural language processing model that includes an encoder model trained to receive a natural language text body and output a knowledge graph and a programmer model trained to receive a natural language question and output a program. The computing system includes a computer-readable medium storing instructions that, when executed, cause the processor to perform operations. The operations include obtaining the natural language text body, inputting the natural language text body into the encoder model, receiving, as an output of the encoder model, the knowledge graph, obtaining the natural language question, inputting the natural language question into the programmer model, receiving the program as an output of the programmer model, and executing the program on the knowledge graph to produce an answer to the natural language question.
How the Natural Language Processing knowledge graph patent works:
-
-
-
- This patent is about a natural language processing model that answers a natural language text question based on a natural language text body
- The natural language question can be a search query
- The natural language text body can be the web pages from search results in response to that search query
- A person performs the search, results are returned, and the natural language processing model looks as the pages returned from that query
- Or the natural language processing model might independently obtain the text body from an external source
- such as one or more websites related to the natural language question, such as a Wikipedia or an IMDB or other knowledge bases
- The text body can be provided to the natural language model to turn it into a knowledge graph
- The natural language question can then be provided to the natural language processing model
- The computing system can input the natural language question into the programmer model and receive the program
- The computing system can then execute the program on the knowledge graph to produce an answer to the natural language question
-
-
Among the advantages listed in the patent from using the process described in it, is one in which they tell us that they can use more than just web pages to get answers for questions. It says that they can use “a substantially larger field of natural language texts via the Internet, such as, for example, scientific research, medical research, news articles, etc.”