





Query Pattern Generation at Google
Published: November 13, 2019
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

How Queries May Determine Intent Classifiers
When someone is searching for something, they will type a few keywords into a search box at a search engine.
Google has recently been granted a patent involving the patterns that queries might be seen in searches.
Normally the keywords used in a search can indicate an intent behind a search, and can “indicate the extent of the information desired by the user and can be captured using a classifier to capture a context for one or more actions performed by the user.”
Related Content:
That is the focus of this new patent.
It tells us more about that Classifier, and how it might be inferred by a search engine such as Google, to better understand the purpose there was for a search, and to “assign a context to the search using the classifier.”
The patent provides an example of this. It tells us that the intent (e.g., classifier) can tell it more about one or more topics which a searcher may wish to see displayed in response to the query in search results, and something about how specific that information might be on those topics.
In other words, Google would look at user input regarding the search to decide upon topic categories to answer a query.
Examples of Queries and Intent
A couple of related examples of search queries in the patent: [Barack Obama] and [Obama 2004 convention speech]. Those queries show off a need for information about Barack Obama covering slightly different topics with different levels of specificity.
Google will look at the query to decide what the intent is behind it. It will then assign a classifier based on that intent.
This patent work to analyze search queries, query patterns, and query documents in order to generate additional queries, query patterns, and query graphs that can be useful for providing search content that matches one or more intents indicated by users entering search queries.
We are told that search queries and search documents can have different resolutions of user intent. Google can look at the documents that might be returned for a query to get a sense of what the user intent might be in response to that query.
The patent tells us that the benefit of looking at those documents is:
In this way, the algorithms can be used that leverage exactly the intent separation implied by the documents, and the intent can be projected onto the queries using the classifier. This mapping can be used to generate and match query patterns, which can be used to match search results to user-entered search queries.
Patent Takeaway
Thinking about this approach, it suggests to me, that if you are performing keyword research you should search for the keywords that you are considering optimizing for, and look carefully at the documents that Google is returning in response to it, to get an idea of what intent Google is determining those keywords are suggesting.
Automated Query Pattern Generation
Beyond being able to determine intent, this seems to be the focus of the process behind this patent:
… the systems and methods described herein can detect a query pattern associated with a user-entered search query and automatically generate similar query patterns based on the detected query pattern. In particular, the systems and methods described herein can access search documents that match a detected query pattern to generate one or more query patterns that can be used to find documents similar to the accessed search documents. Using search documents to determine intent in a query can provide the advantage of leveraging the intents and/or sub-intents implied by the documents and projecting those intents and/or sub-intents onto the received search queries.
So in addition to better understanding the intent behind a query, Google may work to identify patterns behind queries. The patent points out some examples:
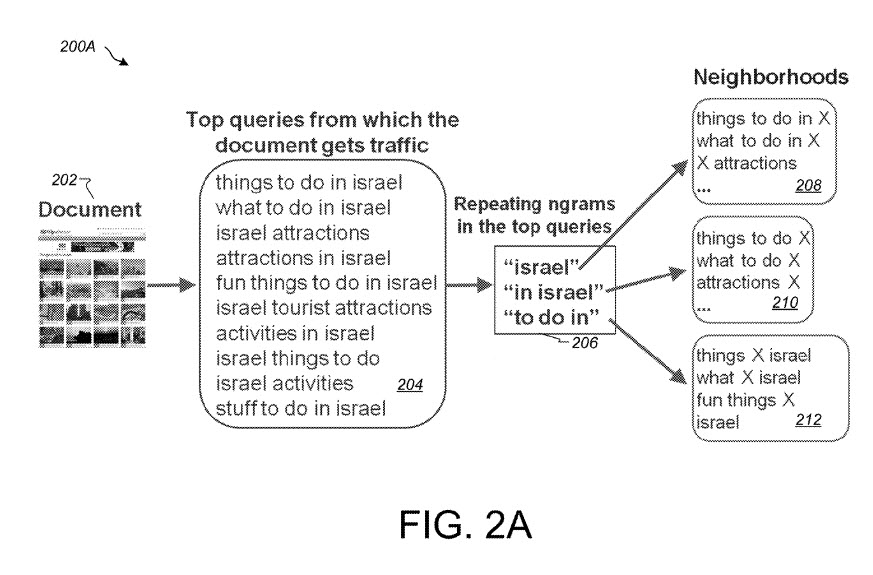
As used herein, a query template represents a query phrase that includes query portions (e.g., sub-phrases) and support to specify substitution portions. For example, the query template [weather in X] can be used to represent queries such as [weather in Paris], [weather in NYC], and [NYC weather]. The “X” represents substitution portions, while the terms “weather”, “NYC”, and “Paris” represent query portions.
So, a query pattern that may have multiple examples, could be said to be a query template. A query pattern such as [weather in X] can represent all queries that include the term “weather” and a term that identifies a geographic location, such as [weather in Paris], [weather in NYC], [weather in the east coast], and [weather near me].
A query pattern can include:
- One or more predefined rules for matching a received query and interpreting the matched query
- A language identifier (e.g., French)
- A country or domain (e.g., France)
- Stopwords (which may be ignored)
- A connector
- A confidence value
- A query splits filter strategy
A Query annotator may also be used in Query Pattern Generation.
A Query annotator determines which entities appear in a given query, where each of those entities have a canonical representation that is independent of the language, for example, applying a query annotator on the query “weather in Paris” may annotate the string “Paris” with a unique identifier (e.g., “/m/05qtj”) that represents the canonical representation of “Paris,” the capital city of France. You may note that the unique identifier from the patent is a machine ID number, from Freebase, which Google has used elsewhere in search to identify entities (See: Image Search and Trends in Google Search Using FreeBase Entity Numbers)
Using such query templates, query patterns, and query annotators, Google could find or generate other query patterns that likely express the same user intent.
For example, A query pattern such as [weather in X] also includes:
[X weather]
[what is the weather in X]
[what’s the weather like in X]
[what’s the temperature in X]
[is it raining in X]
etc.
This is because someone searching for [weather in Paris] and someone else searching for [Paris weather] likely have a similar intent to see the same type of information.
The Scale of Automatic Query Pattern Generation
Upon reading a patent like this, you may wonder how often it might be used. Sometimes we are fortunate enough to be given statements like the following one in a patent (note the “billions of Web Documents” described here:
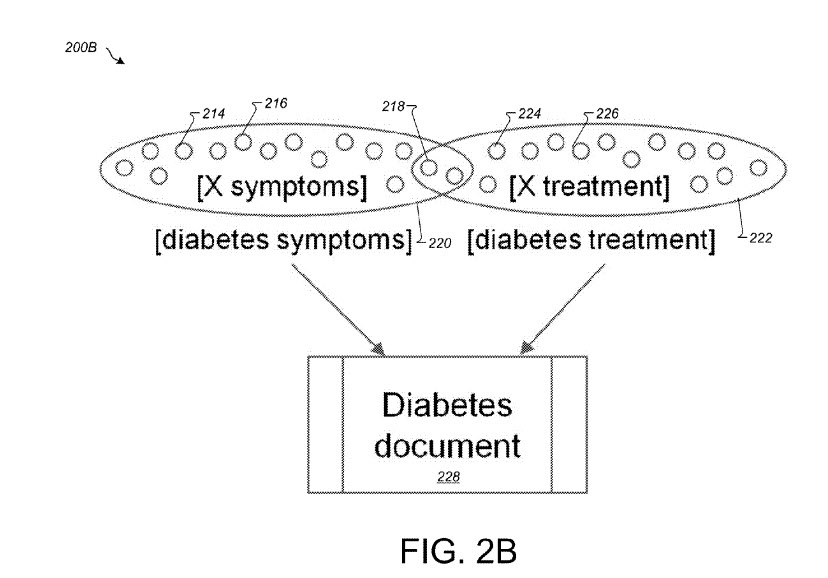
The pattern generator can be configured to convert a set of similar search queries to a set of patterns, using repeating sub-phrases from the search queries. The set of patterns can be aggregated into a pattern graph based on billions of web documents available on the Intranet. In general, every document on the Internet may contribute several pairs of query patterns that may be similar. These pairs are the basis of the aggregated pattern graph. In the aggregated pattern graph, each query pattern represents a node and every two similar nodes are connected on an edge of the graph. The similarity between two connected nodes can be quantified by a similarity score for the edge that connects the two nodes. A pair of similar nodes can be known as similar neighbors. The use of similar neighbors to filter off-topic candidate patterns can provide the advantage of lessening the occurrence of a user receiving inaccurate search results in examples in which two patterns are considered similar based on the two patterns returning similar search results, even though the user intent of the two patterns actually is not similar (e.g., for the query patterns [X treatment] and [X symptoms]). This is because many documents get traffic from both patterns. Using similar neighbors criteria, the algorithms used in system 100 can determine that particular patterns are not actually similar even if related documents show up in the same search results.
We have seen patents that describe query templates for featured snippets too. I wrote about one in the post Featured Snippets – Natural Language Search Results for Intent Queries. That one tries to identify query patterns that might ideally be answered with featured snippets. I’m not seeing the phrase “featured snippets” in this patent, but it does have a number of examples of query patterns.
For instance, documents that are associated with the topic of “things to do in California” may be provided and selected by searchers who use queries such as:
(a) “things to do in california”
(b) “what to do in california”
(c) “California attractions”
(d) “best things to do california”
etc.
Similar queries may exchange the entity “California” with one such as “Ohio.”
Takeaways From the Automatic Query Pattern Generation Patent
Working through this patent, I was reminded of keyword research that I have done in the past finding query patterns and templates and adding query annotators to them using a concatenation fuction in Excel.
Often when writing about intent in queries, we see people mention navigational, informational, and transactional queries. One of the last times I wrote about intent in queries was in the post How Google May Identify Navigational Queries and Resources. This patent that looks at query patterns to better understand the intent behind a query can provide more precise information regarding the intent of a search than just whether a search is informational, navigational or transactional.
in 2014 Google had the Biperpedia project running, which used query log information to build a search ontology, which included canonical queries – like you might want to collect information about if you decided to do things with query patterns and query templates. We’ve seen the entity machine IDs referred to in this patent for freebase numbers like might be found in Google’s knowledge graph. So sources like Biperpedia and the knowledge graph would be places where information about query templates might be gathered, to be used to respond to queries having different intents.
This Automatic Query Pattern Generation patent can be found at:
Automatic query pattern generation
Inventors: Tomer Shmiel, Dvir Keysar and Vered Cohen
Assignee: GOOGLE LLC
US Patent: 10,467,256
Granted: November 5, 2019
Filed: August 3, 2016
Abstract
One general aspect is described that includes a computer implemented method for generating a pattern graph. The method may include accessing data pertaining to a corpus of web documents. The data may include a plurality of query-document pairs. The method may also include identifying at least one query pattern in the plurality of query-document pairs and the query pattern may be associated with a portion of web documents in the corpus. The method may also include identifying a plurality of sub-phrases in the at least one query pattern, determining, in the corpus of web documents, a plurality of other query patterns that include at least one of the plurality of sub-phrases, and assigning an classifier to the at least one query pattern and each of the plurality of other query patterns that include at least one of the sub-phrases.