





Identifying Entity Attribute Relations
Published: March 02, 2022
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

This patent, granted March 1, 2022, is about identifying entity-attribute relationships in bodies of text.
Search applications, like search engines and knowledge bases, try to meet a searcher’s informational needs and show the most advantageous resources to the searcher.
Structured Data May Help With Identifying Attribute Relationships Better
Identifying attributes entity relationships gets done in structured search results.
Structured search results present a list of attributes with answers for an entity specified in a user request, such as a query.
So, the structured search results for “Kevin Durant” may include attributes such as salary, team, birth year, family, etc., along with answers that provide information about these attributes.
Related Content:
- Technical SEO Agency
- Ecommerce SEO Agency
- Shopify SEO Services
- Franchise SEO Agency
- Enterprise SEO Services
Constructing such structured search results can need identifying entity-attribute relations.
An entity-attribute relation is a particular case of a text relation between a pair of terms.
The first term in the pair of terms is an entity, a person, place, organization, or concept.
The second term is an attribute or a string that describes an aspect of the entity.
Examples include:
- “Date of birth” of a person
- “Population” of a country
- “Salary” of the athlete
- “CEO” of an organization
Providing more information in content and schema (and structured data) about entities gives a search engine more information to explore better information about the specific entities, to test and collect data, disambiguate what it knows, and have more and better confidence about the entities that it is aware of.
Entity-Attribute Candidate Pairs
This patent obtains an entity-attribute candidate pair to define an entity and an attribute, where the attribute is a candidate attribute of the entity. In addition to learning from facts about entities in structured data, Google can use information by looking at the context of that information and learn from vectors and co-occurrence of other words and facts about those entities too.
Take a look at the word vectors patent to get a sense of how a search engine may now get a better sense of the meanings and context of words and information about entities. (This is a chance to learn from patent exploration about how Google is now doing some of the things it is doing.) Google collects facts and data about the things it indexes and may learn about the entities that it has in its index, and the attributes it knows about them.
It does this in:
- Determining, with sentences that include the entity and attribute, whether the attribute is an actual attribute of the entity in the entity-attribute candidate pair
- Generating embeddings for words in the set of sentences that include the entity and the attribute
- Creating, with known entity-attribute pairs, a distributional attribute embedding for the entity, where the distributional attribute embedding for the entity specifies an embedding for the entity based on other attributes associated with the entity from the known entity-attribute pairs
- Based on embeddings for words in the sentences, the distributional attribute embedding for the entity, and for the attribute, whether the entity-attribute candidate pair is an essential attribute of the entity in the entity-attribute candidate pair.
Embeddings For Words Get Made Of Sentences With The Entity And The Attribute
Building a first vector representation specifying the first embedding of words between the entity and the point in the set of sentences
- Making a second vector representation defining a double embedding for the entity based on the set of sentences
- Constructing a third vector representation for a third embedding for the attribute based on the set of sentences
- Picking, with a known entity attribute, combines a distributional attribute embedding for the entity, means making a fourth vector representation, using available entity-attribute pairs, specifying the distributional attribute embedding for the entity.
- Building a distributional attribute embedding with those known entity-attribute pairs means developing a fifth vector representation with available entity-attribute teams and the distributional attribute embedding for the attribute.
- Deciding, based on the embeddings for words in the set of sentences, the distributional attribute embedding for the entity, and the distributional attribute embedding for the attribute, whether the attribute in the entity-attribute candidate pair is an essential attribute of the entity in the entity-attribute candidate pair
- Determining, based on the first vector representation, the second vector representation, the third vector representation, the fourth vector representation, and the fifth vector representation, whether the attribute in the entity-attribute candidate pair is an essential attribute of the entity in the entity-attribute candidate pair
- Choosing, from the first vector representation, the second vector representation, the third vector representation, the fourth vector representation, and the fifth vector representation, whether the attribute in the entity-attribute candidate pair is an essential attribute of the entity in the entity-attribute candidate pair, get performed using a feedforward network.
- Picking, based on the first vector representation, the second vector representation, the third vector representation, the fourth vector representation, and the fifth vector representation, whether the attribute in the entity-attribute candidate pair is an essential attribute of the entity in the entity-attribute candidate pair, comprises:
- Generating a single vector representation by concatenating the first vector representation, the second vector representation, the third vector representation, the fourth vector representation, and the fifth vector representation; inputting the single vector representation into the feedforward network
- Determining, by the feedforward network and using the single vector representation, whether the attribute in the entity-attribute candidate pair is an essential attribute of the entity in the entity-attribute candidate pair
Making a fourth vector representation, with known entity-attribute pairs, specifying the distributional attribute embedding for the entity comprises:
- Identifying a set of attributes associated with the entity in the known entity-attribute teams, wherein the set of attributes omits the attribute
- Generating a distributional attribute embedding for the entity by computing a weighted sum of characteristics in the set of attributes
Choosing a fifth vector representation, with known entity-attribute pairs, specifying the distributional attribute embedding for the attribute comprises
- Identifying, using the attribute, a set of entities from among the known entity-attribute couples; for each entity in the collection of entities
- Determining a set of features associated with the entity, where the location of attributes does not include the attribute
- Generating a distributional attribute embedding for the entity by computing a weighted sum of characteristics in the collection of attributes
The Advantage Of More Accurate Entity-Attribute Relations Over Prior Art Model-Based Entity-Attribute Identification
Earlier art entity-attribute identification techniques used model-based approaches such as natural language processing (NLP) features, distant supervision, and traditional machine learning models, which identify entity-attribute relations by representing entities and attributes based on data sentences. These terms appear.
In contrast, the innovations described in this specification identify entity-attribute relations in datasets by using information about how entities and attributes get expressed in the data within which these terms appear and by representing entities and attributes using other features that get known to get associated with these terms. This enables representing entities and attributes with details shared by similar entities, improving the accuracy of identifying entity-attribute relations that otherwise cannot be discerned by considering the sentences within which these terms appear.
For example, consider a scenario in which the dataset includes sentences that have two entities, “Ronaldo” and “Messi,” getting described using a “record” attribute, and a penalty where the entity “Messi” gets escribed using a “goals” attribute. In such a scenario, the prior art techniques may identify the following entity attribute pairs: (Ronaldo, record), (Messi, log), and (Messi, goals). The innovations described in this specification go beyond these prior art approaches by identifying entity-attribute relations that might not be discerned by how these terms get used in the dataset.
Using the above example, the innovation described in this specification determines that “Ronaldo” and “Messi” are similar entities because they share the “record” attribute and then represent the “record” attribute using the “goals” attribute. In this way, the innovations described in this specification, for example, can enable identifying entity-attribute relations, e.g., (Cristiano, Goals), even though such a relationship may not be discernible from the dataset.
The Identifying Attribute Relationships Patent
Inventors: Dan Iter, Xiao Yu, and Fangtao Li
Assignee: Google LLC
US Patent: 11,263,400
Granted: March 1, 2022
Filed: July 5, 2019
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, that ease identifying entity-attribute relationships in text corpora.
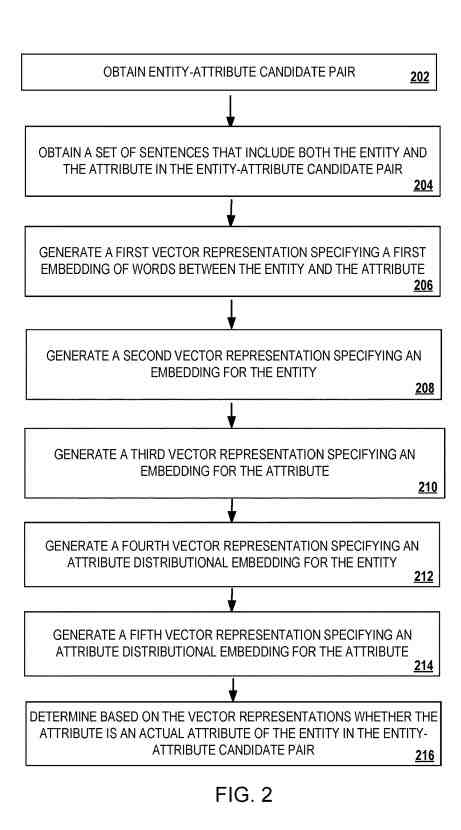
Methods include determining whether an attribute in a candidate entity-attribute pair is an actual attribute of the entity in the entity-attribute candidate pair.
This includes generating embeddings for words in the set of sentences that include the entity and the attribute and generating, using known entity-attribute pairs.
This also includes generating an attribute distributional embedding for the entity based on other attributes associated with the entity from the known entity-attribute pairs, and generating an attribute distributional embedding for the attribute based on known attributes associated with known entities of the attribute in the known entity-attribute pairs.
Based on these embeddings, a feedforward network determines whether the attribute in the entity-attribute candidate pair is an actual attribute of the entity in the entity-attribute candidate pair.
Identifying Entity Attribute Relationships In Text
A candidate entity-attribute pair (where the attribute is a candidate attribute of entity) is input to a classification model. The classification model uses a path embedding engine, a distributional representation engine, attribute engine, and a feedforward network. It determines whether the attribute in the candidate entity-attribute pair is an essential entity in the candidate entity-attribute pair.
The path embedding engine generates a vector representing an embedding of the paths or the words that connect the everyday occurrences of the entity and the attribute in a set of sentences (e.g., 30 or more sentences) of a dataset. The distributional representation engine generates vectors representing an embedding for the entity and attributes terms based on the context within which these terms appear in the set of sentences. The distributional attribute engine generates a vector representing an embedding for the entity and another vector representing an embedding for the attribute.
The attribute distributional engine’s embedding for the entity gets based on other features (i.e., attributes other than the candidate attribute) known to get associated with the entity in the dataset. The detailed distributional engine’s embedding for the quality gets based on different features associated with known entities of the candidate attribute.
The classification model concatenates the vector representations from the path embedding engine, the distributional representation engine, and the distributional attribute engine into a single vector representation. The classification model then inputs the single vector representation into a feedforward network that determines, using the single vector representation, whether the attribute in the candidate entity-attribute pair is an essential attribute of the entity in the candidate entity-attribute pair.
Suppose the feedforward network determines that the point in the candidate entity-attribute pair is necessary for the entity in the candidate entity-attribute pair. In that case, the candidate entity-attribute pair gets stored in the knowledge base along with other known/actual entity-attribute pairs.
Extracting Entity Attribute Relations
The environment includes a classification model that, for candidate entity-attribute pairs in a knowledge base, determines whether an attribute in a candidate entity-attribute pair is an essential attribute of the entity in the candidate pair. The classification model is a neural network model, and the components get described below. The classification model can also be used using other supervised and unsupervised machine learning models.
The knowledge base, which can include databases (or other appropriate data storage structures) stored in non-transitory data storage media (e.g., hard drive(s), flash memory, etc.), holds a set of candidate entity-attribute pairs. The candidate entity-attribute pairs get obtained using a set of content in text documents, such as webpages and news articles, obtained from a data source. The Data Source can include any source of content, such as a news website, a data aggregator platform, a social media platform, etc.
The data source obtains news articles from a data aggregator platform. The data source can use a model. The supervised or unsupervised machine learning model (a natural language processing model) generates a set of candidate entity-attribute pairs by extracting sentences from the articles and tokenizing and labeling the extracted sentences, e.g., as entities and attributes, using part-of-speech and dependency parse tree tags.
The data source can input the extracted sentences into a machine learning model. For example, it can get trained using a set of training sentences and their associated entity-attribute pairs. Such a machine learning model can then output the candidate entity-attribute teams for the input extracted sentences.
In the knowledge base, the data source stores the candidate entity-attribute pairs and the sentences extracted by the data source that include the words of the candidate entity-attribute pairs. The candidate entity-attribute pairs are only stored in the knowledge base if the number of sentences in which the entity and attribute are present satisfies (e.g., meets or exceeds) a threshold number of sentences (e.g., 30 sentences).
A classification model determines whether the attribute in a candidate entity-attribute pair (stored in the knowledge base) is an actual attribute of the entity in the candidate entity-attribute pair. The classification model includes a path embedding engine 106, a distributional representation source, an attribute engine, and a feedforward network. As used herein, the term engine refers to a data processing apparatus that performs a set of tasks. The operations of these engines of the classification model in determining whether the attribute in a candidate entity-attribute pair is an essential attribute of the entity.
An Example Process For Identifying Entity Attribute Relations
Operations of the process are described below as being performed by the system’s components, and functions of the process are described below for illustration purposes only. Operations of the process can get accomplished by any appropriate device or system, e.g., any applicable data processing apparatus. Functions of the process can also get implemented as instructions stored on a non-transitory computer-readable medium. Execution of the instructions causes data processing apparatus to perform operations of the process.
The knowledge base obtains an entity-attribute candidate pair from the data source.
The knowledge base obtains a set of sentences from the data source that include the words of the entity and the attribute in the candidate entity-attribute pair.
Based on the set of sentences and the candidate entity-attribute pair, the classification model determines whether the candidate attribute is an actual attribute of the candidate entity. The set of penalties can be a large number of sentences, e.g., 30 or more sentences.
The Classification Model Performing The Following Operations
- Embeddings for words in the set of sentences that include the entity and the attribute get described in greater detail below concerning the process below
- Created using known entity-attribute pairs, a distributional attribute embedding for the entity, which gets described in greater detail below concerning operation
- Building, using the known entity-attribute pairs and distributional attribute embedding for the attribute, which gets described in greater detail below concerning operation
- Choosing, based on the embeddings for words in the set of sentences, the distributional attribute embedding for the entity, and the distributional attribute embedding for the attribute, whether the attribute in the entity-attribute candidate pair is an essential attribute of the entity in the entity-attribute candidate pair, which gets described in greater detail below concerning operation.
The path embedding engine generates a first vector representation specifying the first words embedding between the entity and the attribute in the sentences. The path embedding engine detects relationships between candidate entity-attribute terms by embedding the paths or the words that connect the everyday occurrences of these terms in the set of sentences.
For the phrase “snake is a reptile,” the path embedding engine generates an embedding for the track “is a,” which can get used to detect, e.g., genus-species relationships, that can then get used to identifying other entity-attribute pairs.
Generating The Words Between the Entity And The Attribute
The path embedding engine does the following to generate words between the entity and the attribute in the sentences. For each sentence in the set of sentences, the path embedding engine first extracts the dependency path (which specifies a group of words) between the entity and the attribute. The path embedding engine converts the sentence from a string to a list, where the first term is the entity, and the last term is the attribute (or, the first term is the attribute and the previous term is the entity).
Each term (which is also referred to as an edge) in the dependency path gets represented using the following features: the lemma of the term, a part-of-speech tag, the dependency label, and the direction of the dependency path (left, right or root). Each of these features gets embedded and concatenated to produce a vector representation for the term or edge (V.sub.e), which comprises a sequence of vectors (V.sub.l, V.sub.pos, V.sub.dep, V.sub.dir), as shown by the below equation: {right arrow over (v)}.sub.e=[{right arrow over (v)}.sub.l,{right arrow over (v)}.sub.pos,{right arrow over (v)}.sub.dep,{right arrow over (v)}.sub.dir]
The path embedding engine then inputs the sequence of vectors for the terms or edges in each path into an long short-term memory (LSTM) network, which produces a single vector representation for the sentence (V.sub.s), as shown by the below equation: {right arrow over (v)}.sub.s=LSTM({right arrow over (v)}.sub.e.sup.(1). . . {right arrow over (v)}.sub.e.sup.(k))
Finally, the path embedding engine inputs the single vector representation for all sentences in the set of sentences into an attention mechanism, which determines a weighted mean of the sentence representations (V.sub.sents(e,a)), as shown by the below equation: {right arrow over (v)}.sub.sents(e,a)=ATTN({right arrow over (v)}.sub.s.sup.(1). . . {right arrow over (v)}.sub.s.sup.(n))
The distributional representational model generates a second vector representation for the entity and a third vector representation for the attribute based on the sentences. The distributional representation engine detects relationships between candidate entity-attribute terms based on the context within which point and the entity of the candidate entity-attribute pair occur in the set of sentences. For example, the distributional representation engine may determine that the entity “New York” gets used in the collection of sentences in a way that suggests that this entity refers to a city or state in the United States.
As another example, the distributional representation engine may determine that the attribute “capital” gets used in the set of sentences in a way that suggests that this attribute refers to a significant city within a state or country. Thus, the distributional representation engine generates a vector representation specifying an embedding for the entity (V.sub.e) using the context (i.e., the set of sentences) within which the entity appears. The distributional representation engine generates a vector representation (V.sub.a) specifying an embedding for the attribute using the set of sentences in which the feature appears.
The distributional attribute engine generates a fourth vector representation specifying a distributional attribute embedding for the entity using known entity-attribute pairs. The known entity-attribute pairs, which get stored in the knowledge base, are entity-attribute pairs for which it has gotten confirmed (e.g., using prior processing by the classification model or based on a human evaluation) that each attribute in the entity-attribute pair is an essential attribute of the entity in the entity-attribute couple.
The distributional attribute engine performs the following operations to determine a distributional attribute embedding that specifies an embedding for the entity using some (e.g., the most common) or all the other known attributes among the known entity-attribute pairs with which that entity gets associated.
Identifying Other Attributes For Entities
For entities in the entity-attribute candidate pair, the distributional attribute engine identifies attributes other than those included in the entity-attribute candidate pair associated with the entity in the known entity-attribute teams.
For an entity “Michael Jordan” in the candidate entity-attribute pair (Michael Jordan, famous), the attribute distributional engine can use the known entity-attribute pairs for Michael Jordan, such as (Michael Jordan, wealthy) and (Michael Jordan, record), to identify attributes such as affluent and description.
The attribute distributional engine then generates an embedding for the entity by computing a weighted sum of the identified known attributes (as described in the preceding paragraph), where the weights get learned using through an attention mechanism, as shown in the below equation: {right arrow over (v)}.sub.e=ATTN(.epsilon.(.alpha..sub.1) . . . .epsilon.(.alpha..sub.m))
The distributional attribute engine generates a fifth vector representation specifying a distributional attribute embedding for the attribute using the known entity-attribute pairs. The distributional attribute engine performs the following operations to determine a model based on some (whether the most common) or all of the known attributes associated with known entities of the candidate attribute.
For the point in the entity-attribute candidate pair, the distributional attribute engine identifies the known entities among the known entity-attribute couples that have the quality.
For each identified known entity, the distributional attribute engine identifies other attributes (i.e., attributes other than the one included in the entity-attribute candidate pair) associated with the entity in the known entity-attribute teams. The distributional attribute engine can identify a subset of attributes from among the identified attributes by:
(1) Ranking attributes based on the number of known entities associated with each entity, such as assigning a higher rank to attributes associated with a higher number of entities than those associated with fewer entities)