


How SEOs Can Identify Low-Quality Pages with Python & Compression Ratios
Published: July 25, 2025
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url
In our SEO efforts, we’re always on the lookout for innovative ways to assess page quality. Recently, an article on Search Engine Journal got us thinking about a unique approach: using compression ratios as a signal for low-quality content. Inspired by this concept, as well as a 2006 research paper on spam detection, we decided to explore whether page compressibility could reveal potential quality issues on our own site.
To test this out, we drafted a Python script to analyze a page’s compression ratio. The basic idea is that pages with redundant or low-value content tend to compress more than high-quality, informative pages. This redundant or low-value content often shows up in spammy pages or low-quality SEO content.
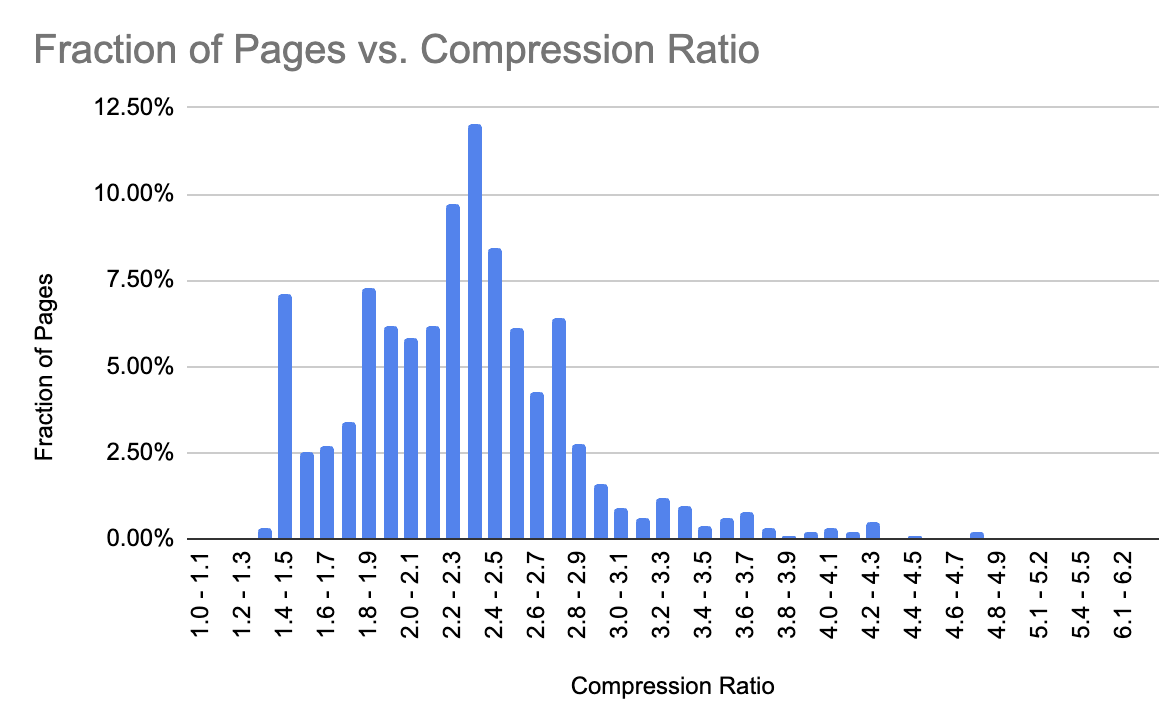
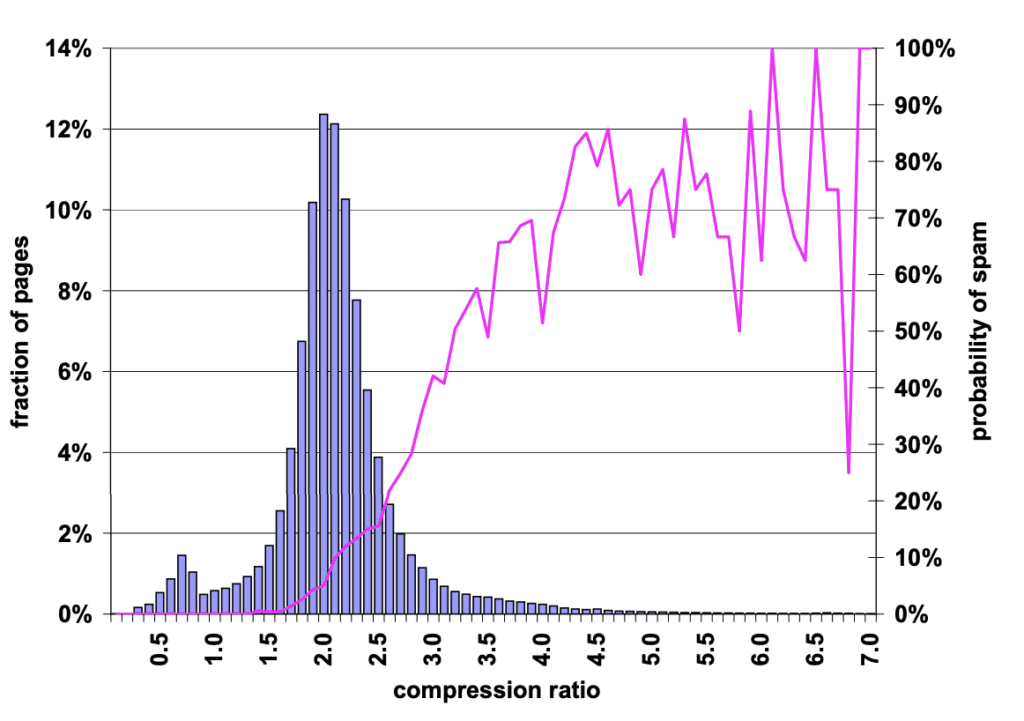
We ran this on every page of Go Fish Digital’s website. The results show that we have 157 pages on our site that score above a 4.0 – the threshold at which the study suggests the likelihood of a page being low quality is greater than 50%. Below, we’ll walk through the script we created to help score a webpage and explain each part so you can use it to analyze your own pages.

Interesting in scoring your entire site to identify content quality issues, we can help.
Understanding Compression Ratios as a Quality Metric
The theory is simple: compression algorithms like gzip reduce file sizes by eliminating redundant data. If a page compresses significantly, it likely has a lot of repetitive or boilerplate content. According to the research we reviewed, high compression ratios can indicate lower-quality or spammy pages, as they often contain repeated phrases, excessive keywords, or general “filler” content. By measuring this ratio, we can identify pages that might be impacting the overall quality of a site.
The Python Code: Analyzing Page Compression Ratios
We drafted python code that fetches a page, extracts its main content, compresses it, and then calculates the compression ratio. Below, we’ll break down each function and provide the code for the full script below.
Breaking Down the Code
Let’s take a closer look at each function and explain how they work. We’ll walk through the python modules needed, how we request a page and extract the text, calculate the compression ration, and print the results. Finally, we’ll share the entire script at the end.
Step 1: Import the needed python modules
To get started we’ll want to use requests, BeautifulSoup, and gzip. We added these to the top of our script.
import requests
from bs4 import BeautifulSoup
import gzip
Step 2: Fetch and Parse the Webpage
We then created a fetch_and_pars function that sends a request to the URL and parses the HTML content using BeautifulSoup. We also remove unnecessary tags (<head> <header>, <footer>, <script>,<style>, and <meta>) to focus on the main body of the content. Removing these tags helps us avoid compressing unrelated HTML or scripts, allowing us to analyze only the visible text content.
# Function to fetch and parse a webpage with headers to mimic a browser
def fetch_and_parse(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# Use a session to reuse the connection
with requests.Session() as session:
response = session.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
# Remove head, header, and footer sections
for tag in soup(['head', 'header', 'footer', 'script', 'style', 'meta']):
tag.decompose() # Remove the tag and its contents
return soup
Step 3: Extract the Text Content
Next, the extract_text_selectively function extracts the main text content from specific tags (<p>, <li>, <h1>, <h2>, <h3>) that are typically used for visible text. We concatenate the text from these tags into a single string. This way, we avoid compressing empty or non-text content that could skew the ratio.
# Function to extract text from a soup object with selective combining
def extract_text_selectively(soup):
individual_tags = {'p', 'li', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'table', 'tr'}
container_tags = {'div', 'section', 'article', 'main'}
excluded_tags = {'style', 'script', 'meta', 'body', 'html', '[document]', 'button'}
inline_tags = {'a', 'strong', 'b', 'i', 'em', 'span'}
text_lines = []
processed_elements = set()
for element in soup.find_all(True, recursive=True):
if element in processed_elements or element.name in excluded_tags:
continue
# Handle table rows () and their child elements
if element.name == 'tr':
row_text = []
for cell in element.find_all(['th', 'td']):
cell_text = format_cell_text(cell)
if cell_text:
row_text.append(cell_text)
if row_text:
combined_row_text = ', '.join(row_text)
text_lines.append(('tr', combined_row_text))
for descendant in element.descendants:
processed_elements.add(descendant)
processed_elements.add(element)
continue
elif element.name in individual_tags:
if element.name == 'p' and element.find_parent('td') and element.find_parent('tr'):
continue
if element.parent in processed_elements:
continue
inline_text = ''
if any(element.find(tag) for tag in inline_tags):
inline_text = ' '.join(element.stripped_strings)
else:
inline_text = ' '.join(element.find_all(text=True, recursive=False)).strip()
if inline_text and element not in processed_elements:
text_lines.append((element.name, inline_text))
processed_elements.add(element)
elif element.name in container_tags:
if element.parent in processed_elements:
continue
direct_text = ' '.join([t for t in element.find_all(text=True, recursive=False) if t.strip()]).strip()
if direct_text and element not in processed_elements:
text_lines.append((element.name, direct_text))
processed_elements.add(element)
combined_text = ' '.join(line for _, line in text_lines)
return combined_text
Step 4: Calculate the Compression Ratio
With the extracted text, we now calculate the compression ratio using the calculate_compression_ratio function. Here, we:
- Measure the original size of the text in bytes.
- Compress the text using gzip and get the compressed size.
- Divide the original size by the compressed size to obtain the compression ratio.
A higher compression ratio indicates that the text was more compressible, potentially hinting at repetitive or low-quality content.
def calculate_compression_ratio(text):
original_size = len(text.encode('utf-8'))
compressed_data = gzip.compress(text.encode('utf-8'))
compressed_size = len(compressed_data)
compression_ratio = original_size / compressed_size
return compression_ratio
Step 5: User Input, Calling Functions, Printing Results
Now that we have the functions we need, we can pull everything together by asking the user to enter the URL, fetching it with our functions, compressing the text, and showing the compression ratio for the URL.
# Prompt the user to enter the URL
url = input("Please enter the URL: ")
# Fetch, parse, and extract text
soup = fetch_and_parse(url)
combined_text = extract_text_selectively(soup)
# Print extracted text
print(f"\nExtracted text from the page:\n{combined_text}\n")
# Inform that compression is about to start
print("Compressing text...")
# Calculate and print the compression ratio
compression_ratio = calculate_compression_ratio(combined_text)
print(f"\nCompression ratio for {url}: {compression_ratio:.2f}")
Full Python Script for Calculating Compression Ratio
Here is the full script you can run or modify locally to get the compression ratio for pages on your site.
import requests
from bs4 import BeautifulSoup
import gzip
# Function to fetch and parse a webpage with headers to mimic a browser
def fetch_and_parse(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# Use a session to reuse the connection
with requests.Session() as session:
response = session.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
# Remove head, header, and footer sections
for tag in soup(['head', 'header', 'footer', 'script', 'style', 'meta']):
tag.decompose() # Remove the tag and its contents
return soup
# Function to properly format cell content by ensuring spaces between header and value
def format_cell_text(cell):
text = cell.get_text(separator=' ', strip=True)
parts = text.split()
formatted_text = ' '.join(parts)
return formatted_text
# Function to extract text from a soup object with selective combining
def extract_text_selectively(soup):
individual_tags = {'p', 'li', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'table', 'tr'}
container_tags = {'div', 'section', 'article', 'main'}
excluded_tags = {'style', 'script', 'meta', 'body', 'html', '[document]', 'button'}
inline_tags = {'a', 'strong', 'b', 'i', 'em', 'span'}
text_lines = []
processed_elements = set()
for element in soup.find_all(True, recursive=True):
if element in processed_elements or element.name in excluded_tags:
continue
# Handle table rows () and their child elements
if element.name == 'tr':
row_text = []
for cell in element.find_all(['th', 'td']):
cell_text = format_cell_text(cell)
if cell_text:
row_text.append(cell_text)
if row_text:
combined_row_text = ', '.join(row_text)
text_lines.append(('tr', combined_row_text))
for descendant in element.descendants:
processed_elements.add(descendant)
processed_elements.add(element)
continue
elif element.name in individual_tags:
if element.name == 'p' and element.find_parent('td') and element.find_parent('tr'):
continue
if element.parent in processed_elements:
continue
inline_text = ''
if any(element.find(tag) for tag in inline_tags):
inline_text = ' '.join(element.stripped_strings)
else:
inline_text = ' '.join(element.find_all(text=True, recursive=False)).strip()
if inline_text and element not in processed_elements:
text_lines.append((element.name, inline_text))
processed_elements.add(element)
elif element.name in container_tags:
if element.parent in processed_elements:
continue
direct_text = ' '.join([t for t in element.find_all(text=True, recursive=False) if t.strip()]).strip()
if direct_text and element not in processed_elements:
text_lines.append((element.name, direct_text))
processed_elements.add(element)
combined_text = ' '.join(line for _, line in text_lines)
return combined_text
# New function to compress text and calculate compression ratio
def calculate_compression_ratio(text):
original_size = len(text.encode('utf-8'))
compressed_data = gzip.compress(text.encode('utf-8'))
compressed_size = len(compressed_data)
compression_ratio = original_size / compressed_size
return compression_ratio
# Prompt the user to enter the URL
url = input("Please enter the URL: ")
# Fetch, parse, and extract text
soup = fetch_and_parse(url)
combined_text = extract_text_selectively(soup)
# Print extracted text
print(f"\nExtracted text from the page:\n{combined_text}\n")
# Inform that compression is about to start
print("Compressing text...")
# Calculate and print the compression ratio
compression_ratio = calculate_compression_ratio(combined_text)
print(f"\nCompression ratio for {url}: {compression_ratio:.2f}")
Running the Script and Interpreting the Results
To use the script, you’ll need to save a python file with the code provided. Next run the python file on your computer through terminal or command line and then simply enter a URL when prompted. The script will display the extracted text, inform you that it’s compressing the text, and then show the compression ratio. A high ratio could indicate low-quality content, though it’s helpful to establish a baseline by analyzing a variety of pages on your site.

Interpreting and Applying Compression Ratios for SEO
After running this script across several pages, you’ll start to see patterns in the compression ratio of your pages. According to Search Engine Journal and the 2006 research paper, pages with high compression ratios often correlate with spammy or low-quality content. While there’s no universal threshold, if you see pages with significantly higher ratios than others, it may be worth reviewing those pages for redundant or keyword-stuffed content.
Limitations and Final Thoughts
Compression ratio analysis shouldn’t be used in isolation, as it’s just one indicator of quality. However, it’s a quick, data-driven way to identify potential issues, especially on large sites where manual review of every page isn’t feasible. By using this technique alongside traditional SEO audits, you can identify opportunities to enhance your site’s overall content quality and possibly improve rankings by identifying and refining lower-quality pages.
Try running the script across pages on your site and see what insights you discover. Or if you want help reviewing the content quality of your entire site, we can help – contact us and let us know you’re interested in content quality assessment.