





AI seo
Generative Engine Optimization Strategies (GEO) for 2026
Published: August 25, 2025
Share on LinkedIn Share on Twitter Share on Facebook Click to print Click to copy url

Generative Engine Optimization (GEO) strategies are the set of practices designed to make content retrievable, re-rankable, and reference-worthy within AI-generated search results, such as Google’s AI Overviews, AI Mode, or ChatGPT. Unlike traditional SEO, which aims to climb SERPs through keywords and technical factors, “GEO SEO” strategies are built around the way large language models (LLMs) fetch, filter, and synthesize information into answers. The goal is not just to appear in search, but to ensure your brand is cited, grounded, and trusted within the AI response itself.
Generative Engine Optimization (GEO) strategies focus on expanding a brand’s semantic footprint, improving fact-density, and enhancing structured data signals so that AI systems recognize and use the content as authoritative input. Ultimately, the aim is to increase AI-driven visibility and business impact, turning brand mentions inside AI conversations into measurable conversions.
Key Takeaways
- What gaps exist today in Generative Engine Optimization? Today, the most significant gap lies at the prompt level. Unlike traditional SEO, where keyword rankings and SERP impressions provide visibility, GEO lacks transparency into which queries surface your content in AI systems. This makes it difficult for enterprises to understand their true presence inside AI conversations. Until purpose-built GEO measurement tools emerge, companies must rely on log file analysis, semantic analysis, and AIO tracking to piece together visibility. These approaches help close the gap, but they also highlight the growing need for custom data solutions at the enterprise level.
- What are the top GEO strategies? The most impactful GEO strategies fall into three categories: expanding semantic footprint, increasing fact-density, and enhancing structured data. Expanding semantic footprint means publishing new content and optimizing existing pages to cover broader topic clusters and adjacencies. Fact-density expansion focuses on adding statistics, citations, and unique insights to ensure every page provides new, verifiable information. Finally, structured data expansion through Schema.org, merchant feeds, and entity datasets makes content easier for LLMs to parse and reuse. Together, these strategies ensure your brand is not just indexed, but consistently cited and grounded in AI-generated answers.
- Is Generative Engine Optimization going to change? GEO will evolve as search behavior shifts and AI adoption accelerates, but its foundations will remain steady. Users are already submitting longer, more complex, and task-oriented queries to AI systems, and while retrieval and reranking mechanisms may adapt, the requirement for semantic breadth, factual authority, and structured signals will not. In other words, the tactics may change, but enterprises that consistently invest in comprehensive, fact-dense, and entity-rich content will maintain visibility in AI-driven search.
Generative Engine Optimization Strategies
Unlike traditional SEO, where ranking would hinge on keywords, backlinks, and page authority (these strategies ending their effectiveness in 2019), Genereative Engine Optimization (GEO) is about making your content retrievable, re-rankable, and reference-worthy inside AI-generated answers. This requires aligning your strategy with how LLMs like Google’s AI Overviews, AI Mode, and ChatGPT actually fetch, filter, and ground responses.
| Strategy | What It Means | Why It Works (Patents & Findings) |
|---|---|---|
| Expansion of Semantic Footprint Through New Content | Publish content that covers topic clusters, related entities, and adjacent queries—not just single keywords. | AI uses query fan-out to expand user queries into multiple variations; broader semantic coverage increases visibility. Patent: US11769017B1 |
| Expansion of Semantic Footprint Through Page Optimizations | Enrich existing pages with FAQs, internal links, and detailed sections to grow semantic density at the passage level. | Rerankers and processors (e.g., ret-rr-skysight-v3) in ChatGPT reward comprehensive, authoritative passages, making them more likely to be cited. |
| Fact-Density Expansion Through Information Gain Analysis | Add statistics, citations, and unique insights to increase the factual depth of content. | AI prioritizes fact-rich, authoritative sources and rewards information gain over duplication. Patent: WO2024064249A1 |
| Expansion of Structured Data Through Merchant Feeds or Schema.org Data Sets | Implement schema markup, product feeds, and entity datasets to improve machine interpretability. | LLMs use vocabulary-aware search and structured data for grounding and parsing. Patent: US9449105B1; Google’s MUM initiative. |
1. Expansion of Semantic Footprint Through New Content
AI systems don’t stop at matching keywords—they expand queries into multiple variations through query fan-out, pulling in semantically adjacent concepts (Patent: US11769017B1). To be visible in this process, enterprises must publish content that covers topic clusters, related entities, and adjacent questions rather than just targeting one keyword per page. This builds a broader semantic footprint, ensuring your content is surfaced across more AI-generated query variations.
Determining What New Content Needs to Be Created
Expanding a site’s semantic footprint isn’t about guessing what topics might resonate, it’s about data-driven identification of topical gaps and demand clusters. By combining semantic analysis, log file insights, and competitive benchmarking, enterprises can precisely identify where new content is needed to capture AI-driven visibility.
Step-by-step method:
- Run Semantic Analysis with Screaming Frog
- Use ScreamingFrog’s semantic analysis tool to extract n-grams and bigrams from your current site.
- This provides a baseline of your existing semantic coverage.
- Benchmark Against Competitors
- Run the same semantic analysis on a top competitor with more traffic to identify n-grams you don’t currently cover.
- This highlights competitor topic density and semantic advantages.
- Leverage Log File Analysis & Ahrefs
- Analyze server logs for ChatGPT-User agent activity to see which of your pages are being surfaced in ChatGPT responses.
- Use Ahrefs to identify your top-performing pages in AI Overviews (AIO) as well as competitor pages with stronger AIO visibility.
- Export and Consolidate Data
- Export:
- Your site’s n-grams
- Competitor n-grams
- Ahrefs data on AIO coverage & keywords
- Competitor keywords and traffic from Ahrefs
- Combine everything into a multi-CSV ChatGPT project.
- Export:
- Cluster Topics and Adjacencies in ChatGPT
- Import the dataset into a ChatGPT project.
- Use ChatGPT to cluster n-grams and keywords into topic demand groups and expand them further via query fan-out (discovering adjacencies).
- Reverse Engineer Prompts & Assign Work
- Have ChatGPT generate likely user prompts based on the identified clusters.
- Analyze whether these prompts can be answered with existing pages or if new pages are required.
- Separate into two work buckets:
- Existing Pages → Optimize for expanded semantic coverage.
- New Pages → Create net-new content to fill topical gaps.
Don’t have ScreamingFrog? Try Go Fish Digital’s free n-gram analysis Chrome Extension.
Aligning Topics to Pages
The final step is to cross-compare your current sitemap (exporting URLs, Page Titles, and Meta Descriptions into a spreadsheet) against the clusters of user prompts and topical adjacencies. This allows you to:
- Map prompts to existing pages when alignment is strong.
- Identify content gaps where no current page can reasonably satisfy the prompt.
- Recommend new page creation when topic alignment is too distant from existing assets.
This alignment process, performed as a topic adjacency mapping exercise, ensures that every high-demand prompt is either assigned to an optimized page or earmarked for new content development.
To see how this is done, scroll to the bottom of this article for a more detailed how-to with accessible tools…
2. Expansion of Semantic Footprint Through Page Optimizations
It’s not enough to create new content, existing pages must also be enriched to maximize passage-level visibility. Recent findings in the industry show rerankers like ret-rr-skysight-v3 (used in ChatGPT) reward comprehensive, high-authority passages over shallow sections. By expanding FAQs, adding contextual internal links, and embedding structured explanations directly into pages, enterprises can grow their semantic density at the page level. This makes it easier for AI models to extract and reuse sections of your content as grounding material.
How-to: Map Topical Adjacencies to Existing Pages and Run a Page-by-Page Gap Analysis
Use the same inputs from your earlier workflow (site + competitor n-grams/bigrams via ScreamingFrog, ChatGPT-User log hits, Ahrefs AIO pages/keywords), then add two focused passes: (A) map adjacencies to your sitemap and (B) do a finer, page-level gap audit.
1) Consolidate inputs into a master sheet
- Columns:
Cluster / Adjacency,Representative Prompts,Entities,Intent,Your n-grams,Competitor n-grams,ChatGPT-User URLs,Ahrefs AIO Keywords/Pages. - Append a sitemap export with
URL, Page Title, Meta Description.
2) Form clusters & adjacencies (query fan-out)
- In ChatGPT, expand seed topics into sub-queries and variations (supports query fan-out in US11769017B1). Tag each with intent (US9449105B1) and entities/terms (vocabulary-aware retrieval; MUM).
3) Map adjacencies to the sitemap (URL alignment)
- For each cluster, match to 1–3 best-fit URLs using entity overlap, intent match, and title/meta signals.
- Label the mapping: Strong Match, Partial Match (optimize), No Match (net-new).
- This stage ensures you’re improving existing pages where alignment already exists.
4) Select pages for optimization (the “Partial” bucket)
- Prioritize pages with: ChatGPT-User hits, AIO impressions in Ahrefs, and competitive gaps.
- Rationale: rerankers like ret-rr-skysight-v3 reward comprehensive, authoritative passages; enrich pages that are close to qualifying.
5) Page-by-page “finer-tooth comb” gap analysis
For each Partial Match URL, build a quick coverage matrix:
- Inventory current passages: pull H2/H3s, FAQs, tables/snippets.
- Generate sub-queries (fan-out) for the page’s cluster; compare to what’s on the page.
- Score each sub-query as: Covered, Needs Depth/Facts, Missing.
- Actions per gap (opt for passage-level upgrades):
- Add/expand FAQs, definition boxes, step lists, comparison tables, pros/cons.
- Increase fact-density (unique stats, citations, examples) → supports information gain and stateful/freshness needs (WO2024064249A1).
- Improve vocabulary/terminology and add short glossaries (aligns to vocabulary-aware retrieval & MUM).
- Embed schema (FAQPage/HowTo/Product/Organization/Dataset) and anchor links for extractability.
- Add contextual internal links to adjacent entities/topics in the cluster.
- Freshness check: last updated, new data, revision note (helps dedicated freshness scoring).
6) Prioritize edits by “reranker survivability”
Weight recommended edits by: completeness, unique information gain, citation quality, entity coverage, structure (lists/tables/FAQ), freshness, and internal link support—i.e., the signals a reranker will likely reward before synthesis.
7) Implement structured data & feeds
- Expand Schema.org coverage and (for ecommerce) merchant/product feeds so LLMs can parse and extract reliably (improves grounding and CER).
8) Validate & measure
- Monitor ChatGPT-User hits to optimized URLs, Ahrefs AIO visibility, and GEO KPIs: AIGVR, Citation Rate, CER, Conversation-to-Conversion.
- Iterate: pages that move from Partial → Strong should show higher extraction/citation rates.
Suggested sheet columns for the mapping passCluster • Representative Prompt • Intent • Entities • Mapped URL • Match Strength (Strong/Partial/None) • Missing Sub-queries • Passage Actions • Schema Needed • Internal Links (To/From) • Last Updated • Evidence (Logs/AIO/Competitor)
This two-stage method turns your sitemap into a semantic optimization blueprint—mapping adjacencies to the right pages first, then closing exact, passage-level gaps that help pages survive retrieval → reranking → grounding and get cited in AI answers.
To see how this is done, scroll to the bottom of this article for a more detailed how-to with accessible tools…
3. Fact-Density Expansion Through Information Gain Analysis
Google’s patents and AI findings consistently highlight the importance of fact-rich, authoritative content (see WO2024064249A1). Models favor content that provides new, verifiable information, which Google has described as information gain. Enterprises should analyze where competitors’ content lacks depth and expand their own pages with statistics, citations, case studies, and unique insights. Increasing fact-density not only improves authority but also raises the likelihood that passages are extracted and cited as “grounding” sources in AI answers.
Performing Information Gain Analysis
One of the most consistent signals across Google’s patents and LLM findings is the value of information gain—providing users with new, verifiable, and fact-dense content rather than repeating what already exists. Patents such as WO2024064249A1 emphasize that content offering unique insights, citations, or supporting data is more likely to be selected as part of a stateful AI response. For enterprises, this means moving beyond surface-level coverage and ensuring every page contains statistical depth, authoritative references, and unique contributions.
How to identify and close information gain gaps:
- Analyze Missing Keyword & Topical Adjacencies (Page-Level)
- Run a semantic and keyword demand analysis on each target page.
- Identify queries or adjacencies that competitors cover but your page does not.
- These gaps represent “missing information gain opportunities”—places where adding a new data point, chart, or explanation improves factual depth.
- Compare Against Cited AI Overview Passages
- Use tools like Ahrefs or Go Fish Digital’s Barracuda to analyze AIO passages.
- Check whether your existing pages have equivalent passage-level answers. If not, expand content to mirror the structure and factual richness of those cited passages (e.g., concise definitions, stat-backed bullet points, or tables).
- Audit Competitor Fact-Density and External Grounding
- Review top competitors in GEO to see what sources they reference.
- High-authority citations—such as research studies, government publications, or .edu references—are strong grounding signals for AI models.
- Add similar or superior references to your content to increase trustworthiness and make it easier for rerankers to select your passages.
- Build Fact-Dense, Citation-Ready Passages
- Incorporate statistics, proprietary data, case studies, or expert quotes.
- Keep passages modular and extractable (lists, tables, FAQ-style blocks) so they can be reused directly by LLMs.
- Ensure every factual claim has a source—preferably high-authority domains—to strengthen grounding potential.
- Leverage Custom Tooling for Scalability
- Manual reviews alone won’t scale at the enterprise level.
- Use custom internal tools (or Barracuda by Go Fish Digital) to flag pages with low fact-density, identify missing adjacencies, and score competitor citations.
- This enables discretionary decisions about where adding unique facts vs. deeper references vs. fresh research will deliver the highest GEO ROI.
4. Expansion of Structured Data Through Merchant Feeds or Schema.org Data Sets
LLMs rely on structured data to interpret, extract, and present information reliably. Findings show systems like ChatGPT use vocabulary-aware search to prioritize content that’s clearly tagged and semantically contextualized. By expanding structured signals—through Schema.org markup, product feeds, and entity datasets, brands make it easier for AI models to parse and reuse their information. This aligns with patents around context-aware query classification (US9449105B1) and Google’s MUM initiative, which emphasizes multimodal, cross-domain grounding.
At its core, the strategy here is simple: feed the LLM as much structured data as possible. Imagery, business information, product SKUs, brand relationships, and entity references. The richer your structured footprint, the easier it is for AI systems to surface your content as a trusted reference.
How to expand structured data effectively:
- Audit Merchant & Business Feeds
- Review all merchant feeds (for ecommerce) and business location feeds (for local/multi-location enterprises).
- Ensure inclusion of: product imagery, pricing, SKUs, availability, business hours, addresses, and geocoordinates.
- Missing fields in feeds often result in AI blind spots where your content could otherwise have been extracted.
- Audit Schema.org Implementation
- Go beyond basic schema. Implement comprehensive Schema.org datasets for:
- Products (Product, Offer, Review)
- Organizations & Local Businesses (Organization, LocalBusiness, Place)
- Content (FAQPage, HowTo, Article, Dataset)
- Verify that markup is valid and machine-parseable at scale with tools like Google’s Rich Results Test.
- Go beyond basic schema. Implement comprehensive Schema.org datasets for:
- Prioritize Entity-Centered Structuring
- Keep all structured data aligned with knowledge graph entities that Google and other systems already recognize.
- Ensure consistent representation of:
- Business names
- Brand names
- Product categories and SKUs
- Locations and services
- This increases the likelihood that AI systems will recognize your data at the prompt level, grounding responses with your brand as the authoritative entity.
- Feed Multimodal Data
- Don’t stop at text: include images, videos, and multimedia references within feeds and schema.
- MUM’s multimodal grounding means structured visual content has equal potential to influence how AI answers user queries.
- Continuous Validation and Updates
- Structured data isn’t “set and forget.”
- Regularly audit for freshness—outdated SKUs, broken image links, or missing business details reduce your grounding potential.
- Align update cadences with freshness scoring signals already observed in ChatGPT and Google AI systems.
How To Perform Generative Engine Optimization (GEO) Gap Analysis
If you got to this point, you might want a tutorial on how I would do some of the analysis above. Let’s walk through exactly how I did that using some of the tools available on the market as well as an example website, the Go Fish Digital blog.
Disclosure:
- This is a demo using a small-scoped data set (blog vs. blog).
- This is a light demonstration of the methodology which can be transferred to large data-sets.
- This is a demo using smaller-scale initiatives vs. enterprise-level.
Step 1: Start a New ChatGPT Project
Since projects can contain larger data sets for reference (in CSV format). I started a ChatGPT project for this example.
Step 2: Start Exports of N-Gram Analysis
Store crawl as HTML and export 3-gram (4-gram is sometimes even better) analysis into spreadsheets of a given target and competitor gap. Currently using the Go Fish Digital blog to do this:
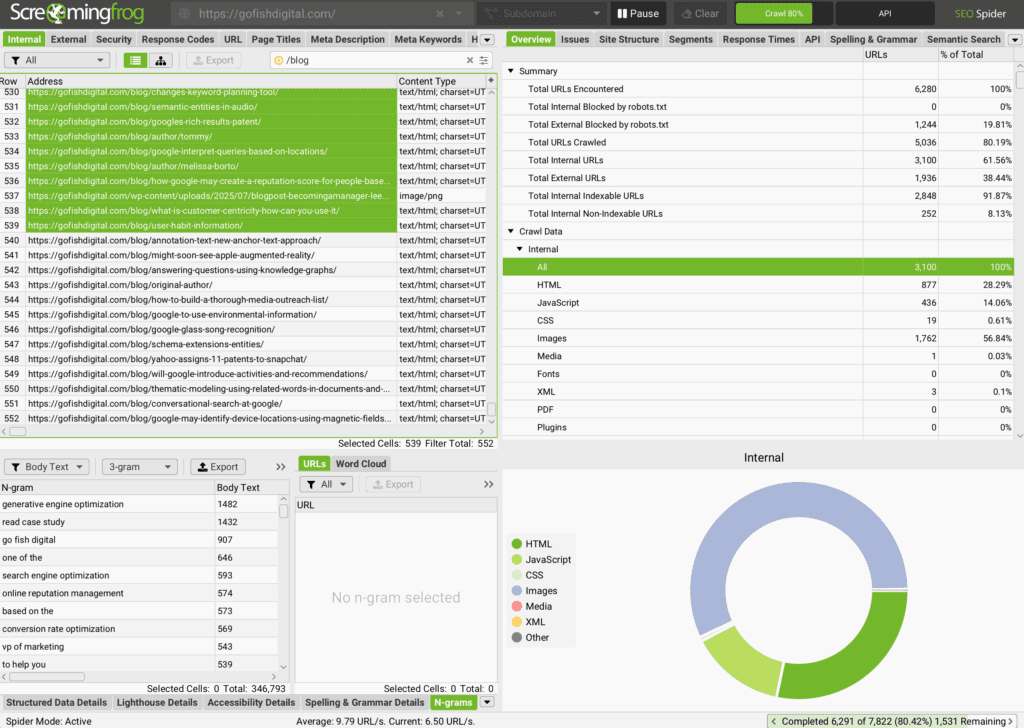
Bonus: Use the semantic analysis tool inside ScreamingFrog to take this process even further. For the demo, I’m keeping this simple (and can be done using a variety of techniques). To learn how to use the ScreamingFrog semantic analysis, watch this video by Taylor Scher.
Step 3: Upload Multiple CSV Assets Into Your ChatGPT5 Project
Since this is a light analysis for the purposes of the walk through. The more data that’s available the more you can process over the prompts in a type of “bash” way to get to what insights you’re looking for. A few spreadsheets were uploaded:
- Current sitemap, URLs, post titles, and more.
- N-gram analysis (from export) from the current website.
- N-gram analysis (from export) from a benchmarked competitor website.
- Bonus: Add in User agent (log file) analysis to highlight “current GPT” prompt coverage.
- Bonus: Add in keyword data to assist in highlight higher impact demand topics (keyword to recommended prompt topics).
- Bonus: Include timestamps in the sitemap to ensure that “freshness” is also a query that we can perform if we’re considering updating content for information gain and fact-density.
Step 5: Start to Build Core Topic Coverage
The core topic coverage will highlight some of the major areas missing in terms of semantic footprint before we get into topical adjacencies and the potential coverage of that.
Since the output of the CSV based on n-grams (3-grams) can be a little unclear, the discretionary analysis of this output is key. Taking the existing spreadsheet we can then remove some opportunities from the initial ideas list and create another upload into the project folder with the selected opportunities.
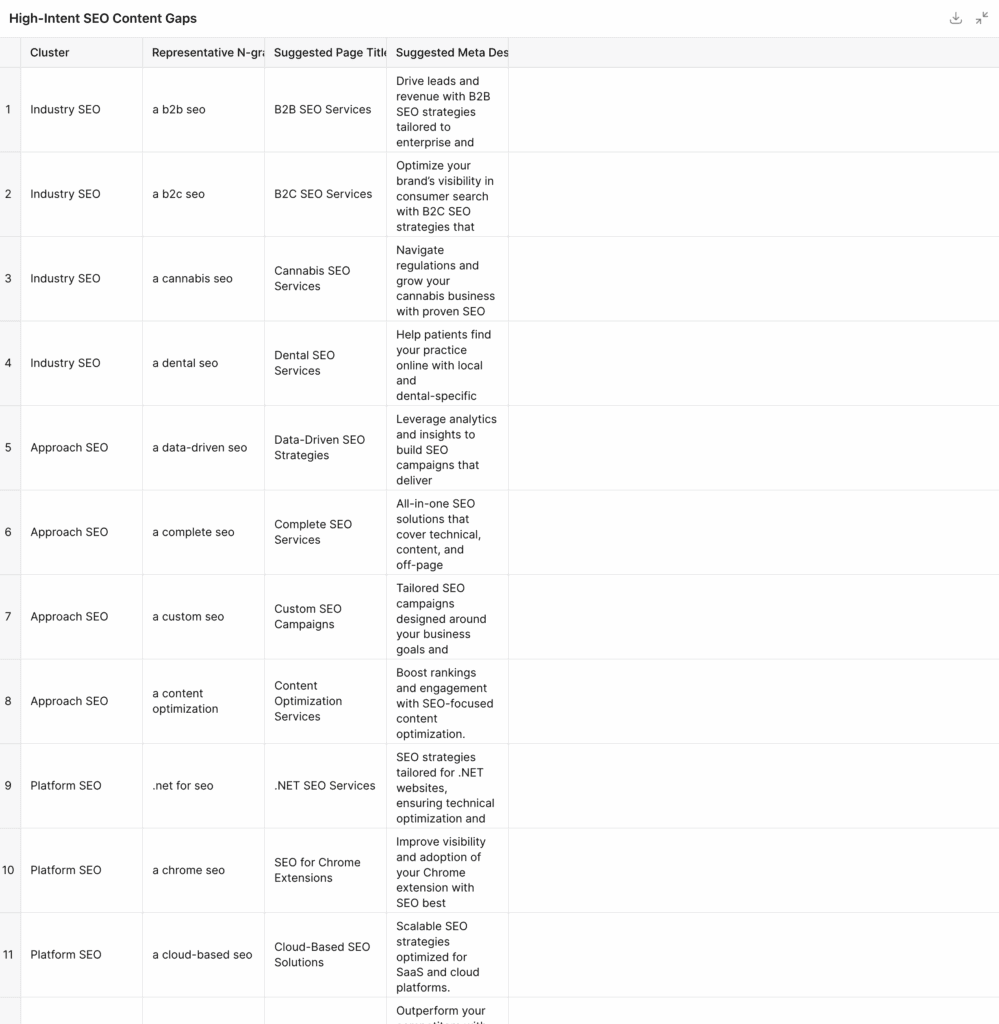
Right away, we can see some pillar topics that we are missing, which could add to our semantic footprint. Since we scoped this only to the blog, it’s not considering service pages that we already have available. So we’re going to refine this list to some target topics that we like. Key point is topics based on our ideal customer persona. That’s really the matrix we’re matching here with the analysis by hand.
Step 6: Start to Build Topic Adjacencies That Will Feed Into Accurate Prompt Examples
For the purposes of this “simpler” demo, I’m going to take the selected opportunities and then start building out topical adjacencies to these subjects, which will help to map out the most potential prompt coverage.
Remember: For larger websites (like in the enterprise-level), this same approach can be taken but needs to be done with larger data sets and should be done using a scripting language vs. ChatGPT. However, just for the illustration purposes of the method, I’m using ChatGPT5 here.
Now that I have my selected core topics, we want to build topical adjacencies for the best prompts that could surface in ChatGPT or AI Mode.
Note: It’s important that we fed in the data assets of the n-grams (and even other data assets) so that the reverse-prompt suggestions that we get will be accurate. Versus simply asking a GPT what questions might come up. It now has a lot more insights (and could have more if we feed it more data) on how to reverse engineer real questions.

Now we can continue to reduce here as we look at this. Since some of these adjacencies make a lot of sense and others don’t:
- Adjacencies that make sense: Cannabis SEO → Adjacent: Dispensary SEO, Local Cannabis Marketing, CBD SEO compliance, Cannabis Ecommerce SEO
- Adjacencies that don’t make sense: Shopify SEO → Adjacent: Ecommerce SEO, App integrations, Shopify speed optimization, Liquid theme SEO
Step 7: Example Question Prompt Coverage
As you can tell from this whole process, we’re using a data-informed way to determine target demand topics. However, not starting from keyword research. Starting from topic alignment and anticipated prompts (since Users are putting far more information into their “search” using AI tools).
We can ask ChatGPT to now dwindle-down all of the insights it has gathered to give us far more accurate recommendations. In addition, if we wanted to take this further, we could feed in page-level insights from competitors around those adjacencies.

From here we can see a lot of targeted insights that will helpful in determining which new pages or existing pages could be targeted. We could once again, go back and map semantic alignment to existing pages if we had them. But in short, since we are looking at new pages to create, this gives us a much better idea of coverage (semantic footprint) we need to produce in order to increase our citation chances.
Frequently Asked Questions About Generative Engine Optimization (GEO)
Common questions and answers from our experts:
What gaps exist today in Generative Engine Optimization?
The biggest gap is at the prompt level. While traditional SEO gives clear visibility through keyword rankings and SERP impressions, GEO lacks the same transparency—brands don’t always know which prompts their content appears for inside AI systems. Although inputs can be pieced together from log files, semantic analysis, and AIO tracking tools like Ahrefs, this creates a data analysis burden for enterprises. Until purpose-built GEO measurement tools emerge, organizations will need to invest in custom workflows and log-based analysis to close the gap.
Why is content so critical for Generative Engine Optimization?
LLMs are powered by information capture—they can only surface what has been published and structured for them to parse. This makes content the backbone of GEO. To increase visibility, brands must expand their semantic footprint: producing comprehensive, modular, and fact-dense content that answers the full spectrum of user queries. Unlike older SEO strategies where backlinks (these strategies ending in 2018) could compensate for thin content, GEO requires a rich layer of owned media that can serve as authoritative grounding material at every stage of the buyer journey.
Is Generative Engine Optimization going to change?
Yes, GEO will evolve as AI adoption and user search behavior shifts. Already, users are asking longer, deeper, and more task-oriented questions of AI systems. While the methods of retrieval and synthesis may change, the underlying requirement will remain: brands must provide semantically rich, fact-dense, and authoritative content at the domain level to be consistently surfaced. In other words, while the mechanics of GEO may adapt, the foundation of semantic breadth and factual authority will continue to define visibility in AI-driven search.
More on AI search from Go Fish Digital
- How to Find Pages on Your Site That ChatGPT May Be Hallucinating
- OpenAI’s Latest Patents Point Directly to Semantic SEO
- Everything an SEO Should Know About SearchGPT by OpenAI
- How to See When ChatGPT is Quoting Your Content By Analyzing Log Files
- How to Rank in ChatGPT and AI Overviews
- Top Generative Engine Optimization (GEO) Agencies
- What is Generative Engine Optimization (GEO)?
- GEO vs SEO: Differences, Similarities, and More