Table of Contents
SEO has constantly been marketing in the framework of the Web. In SEO, pages rank highly in search results based on information retrieval scores using relevance and authority signals from backlinks from other pages and sites. Semantic SEO introduces site owners to consumers to make communication easier about the goods and services offered. Semantic SEO also focuses more on indexing real-world objects such as entities and facts and attributes associated with those entities. Because of this, consumers can find information easier and become customers easier, and learn more about those offers.
Related Content:
What is Semantic SEO?
Semantic SEO is the process of using related topics and entities to help search engines better understand content. Semantic SEO helps provide search engines with more context about a particular page and makes the content more comprehensive. A Semantic SEO search results page can include:
- Knowledge panels
- Search carousels filled with entities
- Featured snippets that may answer questions about the entities in a query
- Related questions (“People also ask” questions that may be like the featured snippet answers)
- Related entities,
- More
There is a lot of variety in Semantic SEO SERPs pages like there is in universal search SERPs pages in SEO.
When Did Semantic SEO Start at Google?
I found a copy of what appears to be the second patent filed at Google. Like Lawrence Page’s Provisional PageRank patent, Sergy Brin filed a provisional patent in 1999 for another algorithm he coined “Dual Iterative Pattern Relation Expansion.” In the post, I wrote about the patent, Google’s First Semantic Search Invention was Patented in 1999. This image is from Sergey Brin’s Patent: 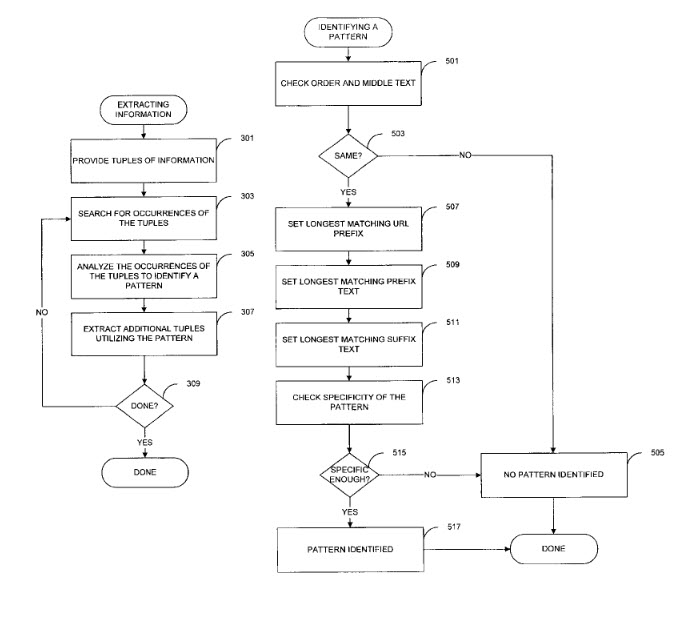 This provisional patent was filed at Google less than a year after the PageRank Algorithm. It would lead to Google starting the Framework Annotation Project, which saw many patents filed at Google, including one on a Browseable Fact Repository, which was managed in-house at Google, until it acquired MetaWeb and its volunteer-run knowledge base, Freebase.
This provisional patent was filed at Google less than a year after the PageRank Algorithm. It would lead to Google starting the Framework Annotation Project, which saw many patents filed at Google, including one on a Browseable Fact Repository, which was managed in-house at Google, until it acquired MetaWeb and its volunteer-run knowledge base, Freebase.
Entities and Semantic SEO
Focusing on Entities can make a lot of sense. For example, a website about the City of Baltimore might contain information about the people who lived there, and it can also look at monuments left behind in their memories. It can also tell you about the famous churches and schools in the city and well-known buildings, places, and businesses. I started doing entity Optimization in 2005 and wrote about my efforts towards that in the post Entity Optimization: How I Came to Love Entities. Closely related is a more recent post that tells us that Google focuses more on entities in search results in a post about Clustering Entities in Google SERPs Updated. If you write about Baltimore, you would want to dig into the city’s history. You would pay attention to people and places that visitors might be most interested in finding out more details. Learn about the past that brought America its national anthem. Instead of optimizing a page for terms or phrases, write about the actual people, places, and things that tell visitors the information they might be most interested in. Let them know about facts associated with those entities. In the mid-2000s, Google had engineers working on a project known as the Annotation Framework. This project was from Andrew Hogue, who was also responsible for managing the acquisition of MetaWeb, with the volunteer directory Freebase. If Google could not build the technology behind entities, they could acquire it. You can learn more about those efforts by reading the Resume of Andrew Hogue. It includes information about what he was doing at Google during his career. He also created a Google Tech Talk video about what Google was doing at the time that is worth watching: The Structured Search Engine.
More Facts in Search Results Using Semantic SEO
Another aspect of Semantic SEO at Google is moving away from 10 blue links to search results filled with rich results, initially described in a Google Blog post by Ramanathan Guha. Also covered in the post Introducing Rich Snippets by Kavi Goel, Ramanathan V. Guha, and Othar Hansson. In 2012 Google expanded the information found in Freebase and gave us search results that provided more information about entities that appear in queries, or at least the entities that Google knows about and may have included in the knowledge graph. (See: How Google’s Knowledge Graph works) We can see more information about entities in knowledge panels, often following knowledge templates based on the type of entity those cover. We will often see sentiment-based reviews about those businesses for local business entities, and we may see query revisions related to the entities displayed in the panels. Knowledge panels often tell us query log information about other entities that “people also search for.”
Providing More Information about Entities by Site Owners Using Schema
In 2011, Google joined with other search engines to provide machine-readable information about entities that appear on pages on the Schema.org website. This way of sharing between search engines was like when they developed XML sitemaps earlier. Schema is a rapidly growing area of Semantic SEO, and more effort has gotten undertaken to update Schema with new Releases. It is possible to get involved in discussions about new and developing Schema by subscribing to the public-schemaorg@w3.org Mail Archives. SEOs can learn about Schema these days as part of Semantic SEO and study developing aspects of Schema. For example, showing stars in search results for products can increase clicks and are worth learning more about. I also keep an eye on new emails from the schema mailing group and recent revisions to the Schema as they come out.
Knowledge Growing On the Web in Semantic SEO?
Sergey Brin filed an early patent from Google in 1999 after Lawrence Page filed the PageRank patent a year earlier. In the post-Google’s First Semantic Search Invention, I wrote about Patented in 1999. This patent was about the DIPRE algorithm after “Dual Iterative Pattern Relation Expansion.” You can use it to find sites with information about specific books and attributes of those books, such as publications, which the publishers were, how many pages each had, and more. If a site had all of the books from the seed set in the patent, the algorithm told it to collect information about the other books it contained. At the start of last year (2020), Google filed a continuation patent to collect information about books to display in search results. This continuation patent is about all kinds of entities and not only books anymore. My post about this patent is Rich Results Patent from Google Moves on from Only Books, and it provides more details about collecting facts about entities than the 2009 Google blog post about rich results.
Google is Focusing on Learning Directly from Pages on the Web
Google patents also tell us how Google might collect information about entities directly from the Web. One of the most detailed about using natural language processing to collect speech information and entity recognition to build triples (Subject/Verb/Object) about those entities. For more details on how Google may do that, see: Entity Extractions for Knowledge Graphs at Google Besides the entity extraction approach described in that patent, another extraction approach uses data wrappers. Google has been doing with name, address, and phone information for local search as long as Google Maps has been around. This approach gets used for sites that collect data about different entities. Examples are television episodes and songs from musical artists and business addresses. This is another way that Google uses Semantic SEO to better learn about facts that it might show as answers to queries from searchers. I wrote about this in the post Extracting Entities with Automated Data Wrappers.
Expanding Meanings for Answers by Rewriting Queries
SEOs have been doing Semantic SEO for almost as long as there has been SEO. We don’t just optimize pages for keywords. We optimize pages for meanings because the search engines can understand that we create pages related to the definitions in a query that a searcher might perform. In 2003 Google started rewriting queries by replacing synonyms for words. Google develops more sophisticated ways of substituting synonyms using the Hummingbird approach, which I wrote about when it came out in the post: The Google Hummingbird Update and the Likely Patent Behind Hummingbird. That patent came out a few weeks before Google announced it on Google’s 15th Birthday.
Semantic SEO Uses New Technology, Such as Language Models
Understanding Semantic SEO means knowing Google’s technologies and approaches to extract entity information from the Web. It also means building knowledge graphs using that technology. Google acquired Wavii in 2013, which used an open domain information extraction process they described in videos and papers. I wrote about it in With Wavii, Did Google Acquire the Future of Web Search? Since then, we have seen Google crawling the Web, trying to learn about everything it can. This effort has used Word Vectors and natural language Processing language models such as BERT and MUM. Google later told us about using an artificial language approach that used a Word Vectors Approach to rewrite ambiguous queries and expand them with missing words in those queries. These queries could capture missing meanings and answers to queries that Google had had difficulties with before. I linked citations behind the Word Vectors Approach in the post Citations behind the Google Brain Word Vectors Approach. Google has also expanded Natural Language Processing using pre-training language models such as BERT in several papers from Google in the past few years. I wrote about how a Word Vector approach (like in Rankbrain) was used for question-answering in the post Question Answering Using Text Spans With Word Vectors. Here is an example of a search result where Hummingbird is replacing the word “place” with the word “restaurant: “replacing the word “place” with the word “restaurant:” 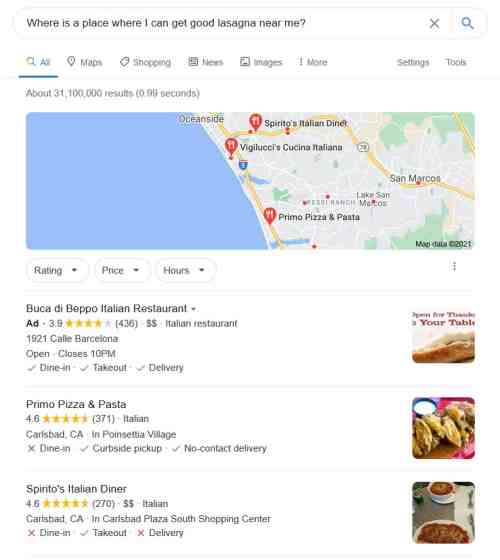 This result is an example of real-world entities and understanding the meaning behind the words in a query. It is about how SEO is becoming Semantic SEO.
This result is an example of real-world entities and understanding the meaning behind the words in a query. It is about how SEO is becoming Semantic SEO.
SERPs Augmented with Knowledge Results
A few years ago, Google Paul Haahr presented at SMX West in How Google Works: A Google Ranking Engineer’s Story: A Google patent that came out after that presentation told us that Google would look in queries for entities, as Paul Haahr told us. And, if Google finds an entity in that query, it may decide to augment the search results with knowledge-based results. Again, a Semantic SEO approach to search. I wrote about this patent in Augmented Search Queries Using Knowledge Graph Information. This can cause a search result for a query to show a knowledge panel for the entity in the query. Related questions about similar entities may be asked and answered in the search results for that query, and associated entities may be shown in those results as well. This is a relatively common site in Semantic SEO, where we are moving away from search results that are filled with ten blue links and see much more colorful and clickable SERPs.
See People Also Ask Queries and Ontologies in Image Search Labels
So again, Google shows us that Semantic SEO focuses on finding real-world objects in queries that searchers perform. Knowledge results can include featured snippets, answering many people’s questions about those entities. Those results can also have other questions, often referred to as “related questions” or “people also ask” questions. They may find those related questions to crowdsource them by looking in query logs for related questions in a question graph. I wrote about those in Google Related Questions now use a Question Graph. I pointed out the labels that Google uses for categories to my co-workers. Google tells us in a blog post that they associate machine ID numbers with entities in image search. This is at Improving Photo Search: A Step Across the Semantic Gap Categories in image search show related entities and concepts in an ontology-based on your search terms. I detailed this in Google Image Search Labels Becoming More Semantic? If you are doing keyword research for pages and want to better understand related entities and concepts, search for those terms on Google Image search. Labels can tell you about entities and terms related to people, places, and things.
Learn About Entities and Personalized Knowledge Graphs from Google
An open-access book (free) by a computer scientist who worked as a visiting scholar at Google. I highly recommend reading it. The author is Krisztian Balrog, and his book is Entity-Oriented Search. It covers the use of entities at Google quite well. He also wrote a paper on entities for a conference worth looking at, Personal Knowledge Graphs: A Research Agenda. The idea of personalized knowledge graphs was exciting. I ran across a couple of Google patents that covered that area and wrote about them. These are those posts:
- 11/25/19 – User-Specific Knowledge Graphs to Support Queries and Predictions
- 8/31/20 – A Personalized Entity Repository in the Knowledge Graph
Semantic Topic Models in Semantic SEO
In 2006, I wrote about Anna Lynn Patterson’s Phrase-Based Indexing in Move over PageRank: Google is Using Phrase-Based Searching?. I expanded on this many times over the years. Google has around 20 related patents on different aspects of phrase-based indexing. I added a post called Thematic Modeling Using Related Words in Documents and Anchor Text, which shows off how frequently reappearing co-occurring phrases tend to be very predictive about the pages those are about. A couple of years later, I wrote about a continuation patent for Phrase-based indexing that turned it from a reranking approach to a direct ranking approach: Google Phrase-Based Indexing Updated. This can make phrase-based indexing very valuable.
Answering Queries using Knowledge Graphs
In Answering Questions Using Knowledge Graphs, I wrote about association scores giving different weights to tuples about entities, and they use their sources to provide them with significance. I also write about how Google might receive a query and create a knowledge graph to provide answers. This is in the patent application Natural Language Processing With An N-Gram Machine. I provide several examples of search carousels. Those show entities that answer queries like that patent application in the post Ranked Entities in Search Results at Google. A search carousel with ranked entities appears in SERPs for a query at Google, such as “Best Science Fiction Books 2020.” 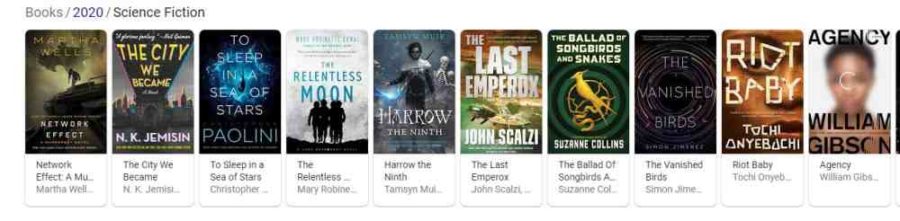 These books are from query results filled with entities shown in a carousel in a ranked order. Knowledge graphs can show personalized results for people and answer questions. I covered that in the post-User-Specific Knowledge Graphs to Support Queries and Predictions.
These books are from query results filled with entities shown in a carousel in a ranked order. Knowledge graphs can show personalized results for people and answer questions. I covered that in the post-User-Specific Knowledge Graphs to Support Queries and Predictions. 
Answering Questions Using Automated Assistants
One of the newest technologies to come from Google is The MultiTask Unified Model, or MUM. Google published a patent that describes the interactions between humans and its automated assistant using the MUM Technology, which I wrote about in Google MUM Update. MUM is supposedly 100)X More Powerful than BERT. And is at the heart f answering questions at Google.
Semantic Keywords in Semantic SEO and No LSI Keywords
Under Semantic SEO, the search will collect real-world information about you and answer relevant questions. Semantic SEO brings us to a world that includes intelligent devices during the internet of things. This can mean more brilliant cars and kitchen devices and email connections with many others worldwide. I recently wrote about semantic keywords and the possibility of a new tool from Google that suggests such keywords. More about keywords and that new tool in this post: Semantic Relevance of Keywords. In that post, I mention LSI Keywords and how they likely are not used by search engines such as Google. I researched LSI to learn about where it came from and whether or not Google was using Latent Semantic indexing. After finding the Bell Labs patent behind LSI and that there was no sign of LSI Keywords from the people who invented LSI, I wrote Does Google Use Latent Semantic Indexing (LSI)? The answer is that it is unlikely that Google uses LSI at all and never used LSI Keywords either. In 2021, I wrote about how users of mobile devices could have their queries rewritten following a user-specified knowledge graph built from application data on that device in a way that may even be transparent to those searchers. It could better use that data and provide answers that take advantage of more personalized results. That post is at Rewritten Queries and User-Specific Knowledge Graphs.
The Web Becoming Ready for Semantic SEO?
In 2001, Tim Berners-Lee, James Hendler, and Ora Lassila wrote the Semantic Web for Scientific American. The sharing of information and data collection described in that paper tells us about the future of Semantic SEO that many places such as Google work towards. A more semantic web doesn’t stuff pages with synonyms or semantically relevant words. It is, as Tim Berners-Lee wrote:
The Semantic Web is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better-enabling computers and people to work in cooperation.
I am coming across more semantic indexing of locations in places such as Google Maps, which I wrote about in An Image Content Analysis And A Geo-Semantic Index For Recommendation,s and in the post-Detecting Brand Penetration Over Geographic Locations; both of these shows a much stronger level of image analysis that can tell searchers more about the places that surround them. I thought it was worth sharing some of the things I have seen from the patent office, also on the pages of Google about search becoming more semantic. Most pages ranking in Google for terms such as “Semantic SEO” are filled with synonyms and a lack of understanding about how semantic technology might work. They also mention technology from the 1980s and fail to cover knowledge graphs or Schema. That is a problem that those don’t cover those topics. Last Updated: 1/10/2022
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: