Table of Contents

From Keywords to Ontologies Using Query Patterns
When we ask Google, “How tall is Barack Obama,” we aren’t searching for pages that match certain keywords, but instead factual information about the person who was the 44th US President. The types of searches we are performing, and the ways that search engines are collecting information and indexing it, and returning answers with it are changing. This transformation is an ongoing process, and Google is still matching keywords in queries to keywords in web documents; so doing keyword research continues to make sense. But understanding how this change is taking place enables us to plan for the future, and where search engines may be going.
Related Content:
We’ve seen patents from Google that tell us about things such as How Knowledge Base Entities can be Used in Searches. When Google introduced its knowledge graph in 2012, it told us that it was starting to focus on things instead of strings. Those strings are strings of text, as in the keywords entered into a search box being matched on documents. A transformation of search focusing upon things means that a search engine would crawl web pages collecting information about the attributes and properties of entities. It would find more importance upon things such as an ontology, which is defined like this:
An Ontology is a formal naming and definition of the types, properties, and interrelationships of the entities that exist in a particular domain of discourse.
Query Patterns
We see Google using question graphs to display related questions in search results, and that pays attention to how entities in those questions might be connected. I wrote about those in, Related Questions are Joined by ‘People Also Search For’ Refinements; Now Using a Question Graph.
A recently granted Google Patent describes how queries might be created about specific entities that answer questions that searchers may have, and understand query patterns that may lead to answering more questions. As the summary of the patent tells us:
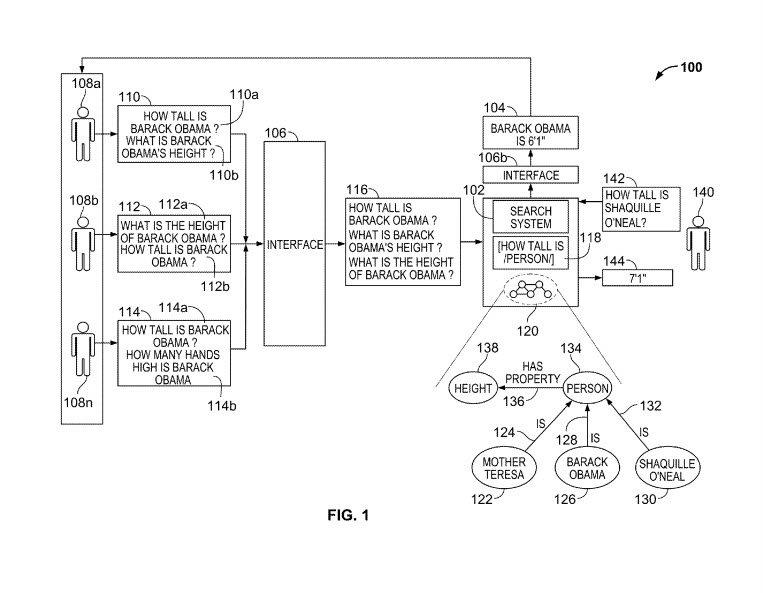
In general, one innovative aspect of the subject matter described in this specification can be embodied in methods that include crowdsourcing the generation of one or more textual query patterns relating to one or more facts about a particular person, place, or thing. For instance, users of an Internet-based system can receive a statement that states a fact about a particular thing, such as “Barack Obama is 6’1”.” In response, the users of the Internet-based system can generate and send one or more queries that could be used to retrieve the fact, such as the question “How tall is Barack Obama?” or a query that includes the query terms “Barack Obama height.”
Biperpedia: An Approach to Building an Ontology Based upon Query Streams
There was a Google paper that covers some of this territory called Biperpedia: An Ontology for Search Applications, which is highly recommended that you spend time with. Ideas from this patent appear to be guidelines for how the Biperpedia Ontology was developed. The focus of the Biperpedia ontology is to help build an ontology that can be used to help return search results. We see that described in the summary to the patent here:
The queries can be rated by other users of the Internet-based system to remove queries that include poor grammar, use awkward sentence structure, are not directed to the fact provided in the statement, or are otherwise less useful than other queries at soliciting the particular fact. The remaining queries can be normalized into query patterns, e.g., by removing punctuation from each query, correcting misspellings, converting the query terms in each query to a lower-case representation, removing the so-called “stop-words” from each query, and using other normalization techniques.
The query patterns can be generalized into generalized query patterns that can be associated with one or more facts stored by a search system. These associations can be used later when a user submits a query that solicits a fact from the search system. For example, the query “How tall is Barack Obama?” can be stored as the query pattern [how tall is Barack Obama], which can be generalized into the generalized query pattern [how tall is/Person/] and associated with each height value for each person that is stored by the search system. Then, when the search system receives the query “How tall is Abraham Lincoln?” the search system can obtain the answer by matching the terms of the query to the generalized query pattern. For example, the query terms can be normalized to [how tall is Abraham Lincoln] and matched to a generalized query pattern [how tall is/Person/].
The patent tells us that it looks for query patterns in user queries to see if it recognizes any. Most patents are created to solve particular problems. This one states exactly why it exists in these terms:
Particular embodiments of the subject matter described in this specification can be implemented to realize one or more of the following advantages. Data and computational efficiencies can be realized because a relatively large number of facts can be identified about a wide range of topics by receiving a relatively small number of query patterns. The query patterns received can be validated or otherwise filtered before being associated with facts or topics, improving the overall accuracy of the facts that can be provided by the system in response to a question.
Understanding query patterns that might be asked about particular types of entities is the path to answering factual queries posed by a searcher. The query patterns patent granted last month is:
Factual query pattern learning
Inventors: Junli Xian, Engin Cinar Sahin, John Blitzer, and Emma S. Persky
Assignee: Google Inc.
US Patent: 9,898,512
Granted: February 20, 2018
Filed: May 13, 2015
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for providing a statement that references a particular attribute of a particular topic, in response to providing the statement, obtaining one or more query patterns that each include one or more query terms that are used in queries submitted to a search system in obtaining a value for the particular attribute of the particular topic, generalizing one or more of the query patterns, and associating the one or more generalized query patterns with one or more other topics that include the particular attribute.
Take Aways
Anticipating what questions your targeted audience might have about what your pages cover may be an exercise worth undertaking. If you know the entities your pages are about, and you make them the stars of your pages, and answer questions about them that people may have, and become the authoritative sources for information about them, it is likely the path towards succeeding under an ontology-based approach that benefits from query patterns and a query stream-based ontology. Which I wrote about more at: 3 Ways Query Stream Ontologies Change Search
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: