Table of Contents
The Automated Assistant Always Listens for Semantic Entities
I keep an eye out for Google publishing about entities in search, in patents or papers, or even tweets.
A new patent application covers something that many people with android phones might be familiar with, but may not have seen anything official from Google about it.
Related Content:
I am sometimes on podcasts and video conferences where I discuss SEO with others, and those conversations often include mentions of Google. Sometimes those mentions trigger a phone to respond and answer questions.
I also recently got a new android phone, using the Android 10 operating system, and it has been identifying songs playing in the background, whether on TV or the radio or my computer, and will identify who the song is from, and the name of the song.
It’s interesting seeing that song identification and it is useful. But it also raises questions such as, “Is this phone always listening to everything?” (Spoiler: It is “Always On.”)
Identifying Semantic Entities in Audio
Imagine having a phone call with someone, or listening to a TV Broadcast or a radio station or a podcast, and a person or a place is mentioned or a book or a movie. And your phone hears that mention and makes a note of it so that you can access more information about the person or place or thing mentioned.
That is what this new patent application is about – identifying Semantic Entities mentioned in audio that you may hear, and providing you with additional information about those entities.
The patent application starts off telling us:
The present disclosure relates generally to systems and methods for identifying semantic entities in audio signals.
In more detail, it says that it will use an approach that uses machine learning to identify semantic entities in audio signals that are heard by a user, to display those semantic entities to the user, and to provide additional information to the user about those semantic entities. These entities are more than just the people talking in audio signals.
Google knows that we listen to lots of different types of sounds from different sources on our phones (at least I do.)
For example, a person can listen to music and movies stored locally on their smartphones; stream movies, music, television shows, podcasts, and other content from a multitude of complementary and subscription-based services; access multimedia content available on the internet; etc.
And people use phones to communicate with each other, too.
They may even use their phones to provide translation services.
This patent identifies the problem it was intended to solve by telling us:
Thus, people may hear about certain topics of interest while using their mobile computing devices in a variety of environments and situations.
However, while a particular topic may be of interest to someone, often a person may not be in a position to interrupt a task they are performing to look up supplemental information on the particular topic.
So Google intends to listen in to our conversations and what we listen to so that it can assist us by providing more information about what we hear.
And that appears to start by being able to identify the semantic entities in audio signals that it may hear. In other words, entities that are mentioned in those audio signals.
This patent application can be found at:
Systens and Methods for Identifying and Providing Information about Semantic Entities in Audio Signals
Publication Number WO2020027771
Inventors: Tim Wantland, and Brandon Barbello
Publication Date February, 6, 2020
Applicants: Google LLC
Abstract
Systems and methods for determining identifying semantic entities in audio signals are provided. A method can include obtaining, by a computing device comprising one or more processors and one or more memory devices, an audio signal concurrently heard by a user. The method can further include analyzing, by a machine-learned model stored on the computing device, at least a portion of the audio signal in a background of the computing device to determine one or more semantic entities. The method can further include displaying the one or more semantic entities on a display screen of the computing device.
Hearing About Semantic Entities in Audio
The process described in the patent starts out by telling us that is in an “always-on operating mode” to enable it to “identify semantic entities that a user hears from a variety of audio signals”, such as:
- Media files playing on the computing device
- In-person conversations or other audio the user overhears in his/her environment
- Telephone conversations
- Etc.
These conversations may be about more than who is being listened to, but could also be about semantic entities mentioned. As the patent tells us, this approach can provide supplemental information about semantic entities mentioned in audio (regarding people, places, and things):
- A person listening to a podcast on their smartphone may be interested in learning more about a particular writer discussed in the podcast
- A person having a conversation with a tour guide speaking a foreign language may be interested in learning more about a particular tourist attraction discussed by the tour guide
- A person having a telephone conversation with a friend may be curious to see what is on the menu of a restaurant recommended by her friend
Providing Additional Information about Semantic Entities
In addition to identifying semantic entities (e.g., people, places, locations, etc.) in an audio signal heard by the user, a device could also display those semantic entities to the user, with a user interface displayed on a computing device.
That user could also then select that particular semantic entity, using the user interface to access supplemental information about the selected semantic entity.
Machine Learning In this Audio process
The patent tells us it may use a machine-learned model stored on the computing device to analyze an audio signal to determine one or more semantic entities.
One example is the use of a speech recognition machine-learned model that has been trained to recognize various people, places, things, dates/times, events, or other semantic entities in audio signals which include speech.
When this patent says that this process might be done “in a background,” they mean that the analysis of an audio signal on a computing device might be done at the same time as another task being performed on the computing device or while the computing device is in an idle state.
A person watching a movie on their smartphone may have the audio from the movie analyzed while they are watching the movie.
If semantic entities are mentioned during that movie, like particular people or places or things, the device could display those semantic entities on the display screen of the device using “text, icons, pictures, etc. which are indicative of the semantic entities.”
The user may then be able to select one of those entities and the computing device could provide additional supplemental information about a selected semantic entity.
Supplemental information options can include:
- Database entries (e.g., webref entries, Wikipedia entries, etc.)
- Search engine results (e.g., Google search results, etc.)
- Application interaction options (e.g., restaurant review applications, reservation applications, event ticket purchase applications, etc.)
Audio Signals May be Heard In Many Applications
Audio signals can be played via applications such as:
- Internet browser
- Music player
- Movie player
- Telephone call
- Speech to text dictation
Identifying Songs and Providing More Information about them
The process behind this patent includes a song recognition semantic entity identifier model trained to recognize songs (See the image below for the “Now Playing” notification.)
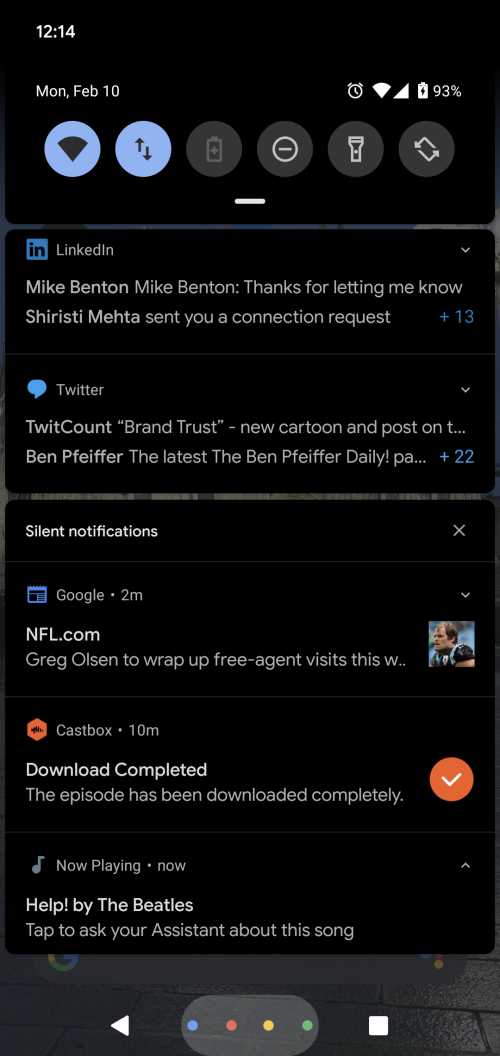
In addition to the notification at the bottom of that screen about the Song “Help” by the Beatles, and the interface that allows you to see if the automated assistant has more information about the semantic entity identified, Google also has a now playing history:
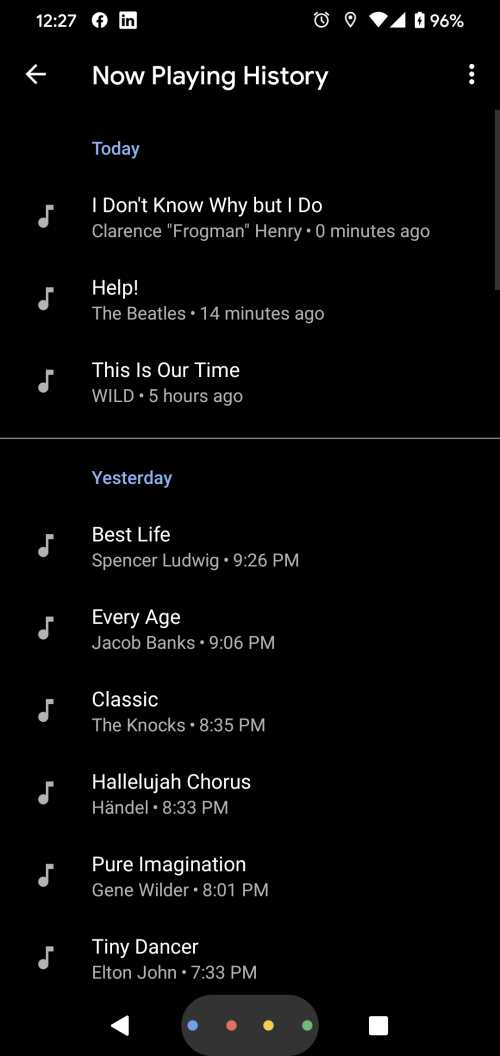
There is a now playing app in Android, which Google has announced which appears to be related to what is described in this patent. This “songs played” machine learning model is in addition to another machine learning model that identifies Semantic entities in other audio, and another model that listens during translations for mention of Semantic entities. The other parts of Semantic Entities Identification have not been announced yet.
Additional Features of this Listening for Semantic Entities Process
A Device using this process such as a smartphone would be in an “always-on” mode.
The user of a device would be able to revoke or modify consent to listening to with entities identified.
Personally, identifiable information could be protected under this process.
This system would be trained to recognize and/or translate various semantic entities in a foreign language.
This process can take place during times when a phone is engaged in a phone call.
Entities can be set up to be displayed when a device is in a locked or idle mode.
A Semantic Entity identified during audio can be added to a clipboard and displayed for a user’s review.
A Semantic Entity might be displayed in a “live tile” as an icon and a rolling list of those entities could be displayed.
An associated peripheral device such as a computing device like a smartphone might display semantic entity information for an audio device like a smart speaker.
The semantic entities could be announced on an audio device, such as a smart speaker.
Semantic Entities that have been identified could be logged and accessed at a later time.
A Book mentioned in a podcast may include supplemental information such as a link to the author’s website, and the option to buy the book, directions to a nearby library.
A Movie mentioned in a podcast might include a link to a trailer for the movie, an option to buy a movie ticket, the ability to see showtimes at a nearby theatre, directions to that theatre.
Analysis of audio in the background of other applications running means that semantic entities can be identified and presented without interrupting other tasks on a device.
Takeaways
The song identification machine learning model described in this patent is working already and provides a way to find out additional information about songs that you may hear. The machine learning models which listen for semantic entities during audio and during translations don’t appear to be implemented yet. This is still a patent application, and it may take some time before all aspects of this patent are implemented.
I can see it being useful having people or places or things mentioned in audio referred to the same way songs are now, and having a chance to see more information about those semantic entities, regardless of whether those are mentioned in conversations, phone calls, radio or TV stations, or in apps on a phone.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: