Table of Contents
Where did Rich Results come from at Google?
Google introduced us to the concept of rich snippets with a blog post in 2009 from Ramanathan Guha, titled Introducing Rich Snippets. Guha went in to later co-write a paper in 2015 which tells us more about the start of schema.org, and how rich snippets were related to them, in Schema.org: Evolution of Structured Data on the Web
In the years after that blog post came out, I tried to find a patent or paper that provided more information about rich snippets. It wasn’t until 2018 when I wrote about a patent application in the post, How Rich Results May be Chosen and Created (Granted). To see the kinds of rich results that Google now offers, you can find out more on their developer pages about enabling search result features on your site, which includes a section specifically about rich results.
Related Content:
The first Google Patent on Rich Results was About Books
Originally, that patent I wrote about was about rich results for search queries about books, but this version of the patent appears to update it to be about a wider range of rich results. The books aspect of the patent has been removed from the updated patent’s claims, but those are still in the description of the patent. It is a continuation patent, updated for the second time. Unlike a lot of continuation patents, the title of the patent changed, as did the abstract for the patent. It originally had the title “Rich results relevant to user search queries for books” and the new title removed the last two words in that title to “Rich results relevant to user search queries.”
It is worth looking at how the first claim has evolved in this patent to be originally about books, and now covers a much wider range of results.
The first claim for the first version of this patent, which was granted November 5, 2013 – Rich results relevant to user search queries for books Tells us that it is about searching a corpus of digital book resources:
1. A computer-implemented method comprising: receiving a query requesting a publication search, the publication search being a search of a corpus of digital book resources that each relate to a respective particular book; obtaining publication search results responsive to the query from the corpus of digital book resources, each publication search result identifying a respective resource previously identified as relating specifically to books, each publication search result identifying a respective digital book resource in the corpus of digital book resources; determining that a score for a first publication search result ranked first in a ranked order of publication search results satisfies a threshold relative to respective scores of other publication search results, wherein a rich result is provided for the first publication search result if the score satisfies the threshold, and wherein a rich result is not provided for the first publication search result if the score does not satisfy the threshold, and wherein the first publication search result is associated with a book; in response to determining that a score for a first publication search result ranked first in a ranked order of publication search results satisfies a threshold relative to respective scores of other publication search results, searching a corpus of web resources using data associated with the first publication search result to obtain one or more web resources that refer to the book; generating a rich result for the first publication search result, where the rich result comprises data from the first publication search result and data from the one or more web resources, wherein the data from the one or more web resources comprises one or more of price information for the book, a link to a website related to the book, a snippet of the book, or data identifying one or more authors of the book; and providing the rich result with one or more other publication search results.
The Second Google Patent on Rich Results was Also About Books
The first claim for the Second version of this patent, granted July 28, 2015 – Rich results relevant to user search queries for books (This is the third time it has been updated) focuses upon how it applies to books:
1. A computer-implemented method comprising: receiving a query; obtaining search results including publication search results responsive to the query, wherein each publication search result refers to a respective book; determining that a score for a highest-ranked publication search result satisfies a threshold relative to respective scores of one or more other publication search results to be provided in response to the query, wherein the highest-ranked publication search result refers to a book; in response to determining that the score for the highest-ranked publication search result satisfies the threshold relative to respective scores of the other publication search results, wherein the score for the highest ranked publication search result satisfies the threshold if the score is at least a threshold multiple of a second score for a second publication search result ranked second in a ranked order of the publication search results, generating a rich result for the highest-ranked publication search result, wherein the rich result for the highest-ranked publication search result comprises more elements of data than any of the other publication search results to be provided in response to the query, wherein the rich result for the highest-ranked publication search result comprises data from one or more web resources that refer to the book, and wherein the elements of data for the rich result comprise a title of the book, an author of the book, and a link to a website related to the book; and providing the rich result and the one or more other publication search results in response to the query.
The Newest Version of this Patent on Rich Results is no longer about just books
The Title of the patent and the abstract have changed as well as the first claim in this third and newest granted version of the patent, Rich results relevant to user search queries (granted December 17, 2019):
1. A computer-implemented method comprising: receiving a query requesting a search of a first corpus of resources; obtaining first search results responsive to the query from the first corpus of resources, the first search results including a first-ranked result; determining whether a score for the first-ranked result satisfies a threshold, the threshold is determined based on a respective score of at least one of the remaining results in the first search results; and responsive to the score satisfying the threshold: searching a second corpus of resources using data associated, in the first corpus, with the first-ranked result to obtain, from the second corpus, one or more resources that refer to the first-ranked result, generating a rich result for the first-ranked result, where the rich result comprises data from the first-ranked result and data obtained from the one or more resources in the second corpus and providing the rich result as a response to the query the rich result enhancing the first-ranked result in the first search results.
The description of the patent and the drawings that accompany it are still about books, as can be seen in this image from the latest version of the patent:
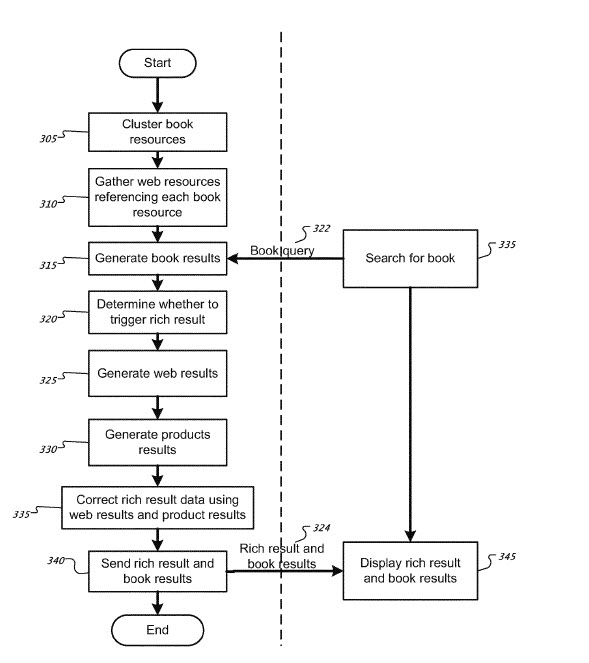
This latest version of the patent has a new (shorter title) and a new abstract, but the description of the patent is very similar to the first two versions of the patent, and there doesn’t seem to be a lot to learn about rich results that are new other than what is contained in the claims of the newest version of the patents.
Rich results relevant to user search queries
Inventors: Matthew K. Gray, Gregory H. Plesur, and Garrett H. Rooney
Assignee: GOOGLE LLC
US Patent: 10,509,830
Granted: December 17, 2019
Filed: May 8, 2018
Abstract
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for triggering rich results in response to queries. In one aspect, a method includes receiving a query. One or more search results are obtained from a first corpus. A rich result is triggered based on a score of the first-ranked search result if it meets a threshold relative to other search results. The rich result is populated with additional metadata about the first-ranked search result obtained from a second corpus. The rich result is provided in response to the query.
Takeaways About this Rich Results Patent
The best source of information about Rich Results that I am presently seeing at Google appears to be the information on the Google Developer pages that I linked to above regarding search feature enhancements. This update of the rich results patent removed “Books” from the first claim, but still refers to them later in the claims, with this line:
4. The method of claim 1, wherein the first corpus is a book corpus and the second corpus is a web-based corpus.
I suspect that there was an intention to remove all references to books from the claims in this patent and am hoping that Google updates this patent again with another continuation patent to let us know more about the processes behind the use of rich results and the sources of information that those rich results use.
Because they are likely using more than just a book corpus for rich results that Google will show that are described on this developer’s page in their Search Gallery.
At this point, the claims used in the newest version aren’t very good at describing the process behind the patent that Google is trying to protect. Hopefully, they will provide an update that tells us more.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: