
You may recognize the names of one of the inventors of the patent I am writing a post about. He had one of the most talked-about Google Updates named after him. It is known as Panda.
Related Content:
A Google Blog post about Panda refers to it as the “high-quality sites” update; this patent talks about replacing high ranking search results from low-quality sites with high ranking search results from high-quality sites. One of the best blog posts about the Panda Update is this one from Amit Singhal:
More guidance on building high-quality sites
It is good that the blog post details a lot about what is a high-quality website because the patent doesn’t tell us how to distinguish between low quality and a high-quality site. Even more insights into how Google may identify low quality and high-quality sites are explained in this Wired interview with Matt Cutts and Amit Singhal:
TED 2011: The ‘Panda’ That Hates Farms: A Q&A With Google’s Top Search Engineers
This patent is interesting because it provides a glimpse behind the Panda Update to give us an idea of what was happening to searchers instead of site owners when they performed searches and didn’t end up on the content farm sites that the Panda Update was supposed to divert them from. As the patent says, it “focuses upon improving search results by replacing low-quality web sites with sites that have been identified as high-quality sites.”
This was a problem that had been identified in a few places and noted in prominent places, such as the New York Times, which noticed Google’s Panda Update:
Google Tweaks Algorithm to Push Down Low-Quality Sites
This patent identifies pages that rank well for certain queries and looks at the quality of those pages. If a threshold amount of those ranking pages are low-quality pages, the search engine might use an alternative query to find the second set of search results that include pages from high-quality sites. Those search results from the first query might then be merged with the results from the alternative query, with the pages from the low-quality sites removed so that the search results include a greater percentage of pages from high-quality sites.
The positive aspect of this result is that results that have a high threshold of results from low-quality sites disappear, and are replaced with results that include higher-quality sites. Google’s search results end up looking better.
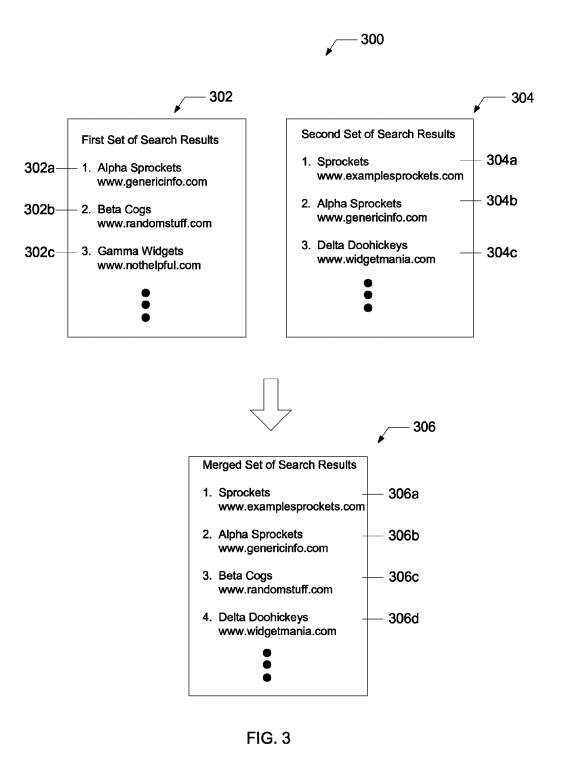
Merged Search Results
The patent doesn’t define what a high quality or a low-quality site is for us. The blog post from Amit Singhal does a better job of providing “guidance” on what those terms mean.
The patent doesn’t discuss the loss of traffic to the low-quality sites that are removed from search results. We heard from people who were impacted by Panda how much traffic they were losing to their sites.
The patent is:
Selectively generating alternative queries
Inventors Navneet Panda, April R. Lehman, Trystan G. Upstill
Original Assignee Google Inc.
Publication number US9135307 B1
Publication type Grant
Application number US 13/728,851
Publication date Sep 15, 2015
Filing date Dec 27, 2012
Abstract:
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for obtaining search results from high-quality sites. One of the methods includes receiving data identifying first resources that are responsive to a first query. If at least a first threshold number N of top-ranked first resources are located on sites previously identified as low-quality sites, a second query and data identifying second resources that are responsive to the second query are obtained, wherein at least a second threshold number M of top-ranked second resources are located on sites previously identified as being high-quality sites. Search results are provided in response to the first query, wherein the search results identify one or more of the first resources and also identify a particular second resource of the second resources.
How a “site” is defined within this patent is interesting, and these are the alternatives provided:
(1) a collection of resources that are hosted on a particular server.
(2) The resources in a domain, e.g., “example.com,” where the resources in the domain, e.g., “host.example.com/resource1,” “www.example.com/folder/resource2,” or “example.com/resource3,” are in the site.
(3) The resources in a subdomain, e.g., “en.example.com,” where the resources in the subdomain, e.g., “en.example.com/resource1” or “en.example.com/folder/resource2,” are in the site.
(4) The resources in a subdirectory, e.g., “example.com/subdirectory,” where the resources in the subdirectory, e.g., “example.com/subdirectory/resource.html,” are in the site.
There is a mention of site quality scores, but not how they are determined. The patent does tell us that the search engine might use a white list of high-quality sites and a blacklist of low-quality sites prepared manually or by some other method offline.
We are also told that information about queries might be collected over some time. If a certain amount of the top-ranking pages for the initial query are on low-quality sites, a second query based upon that first query might be used. The patent tells us that one way it might do this is to use a database that “includes substitute query terms and can generate an alternative query by substituting a substitute query term for one of the query terms in the first query.” This reminded me of some posts I have written about Google patents covering substitute query terms like I wrote about in:
- How Google May Substitute Query Terms with Co-Occurrence
- How Search Engines May Substitute Other Search Terms for Yours
- Investigating Google RankBrain and Query Term Substitutions
As an alternative, the patent tells us that the search engine might build “a conceptual graph of queries and traverse the graph to obtain one or more alternative queries.” That, “each node in the graph is defined by a query and a set of top-ranked search results obtained for the query. Links between nodes in the graph can indicate that the queries are related or that one query is an alternative query for another query.”
That would be very different from the link graphs that we think about when it comes to Google, but an interesting way of thinking about how alternative queries might be found. The patent builds upon this graph approach, and it sounds like it might be a method that they used.
This search system might evaluate more than one possible alternative query before selecting one with the highest measure of confidence.
If the set of results that includes a merged threshold amount of high-quality sites, it might try to accrue more alternative query results from high-quality sites.
Conclusion
This may be the original patent from the Panda Update. Google’s Navneet Panda is one of the inventors on the patent, as was disclosed in the Wired interview with Cutts and Singhal. And this patent does target content farm sites, which is what the original Panda Update was most known for. The patent itself doesn’t disclose differences between low quality and high-quality sites, and we learned in the Wired Interview that it was the search engineer named Panda who came up with some of the initial questions identifying the differences between the two.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: