
Might Google Extract Keywords from Image Text?
A couple of years ago, I asked the question, Will Google Start Reading Text in Images on the Web Soon?
I was writing about a patent from Google that described how the search engine might identify documents that matched visual queries. In a slightly different approach, a newly granted patent from Google describes how the search engine might extract keywords from image text, and might retrieve images associated with such extracted text.
Related Content:
The patent tells us that images captured in many places might be able to tell us more about where those images were captured, such as street scenes that could show us “text as part of street signs, building names, address numbers, and window signs.” or logos on cars as well as on building signs.
How useful would a process such as this be towards capturing business information for something such as Google Maps or Google Search? The patent points out some difficulties that might be faced, and some of the opportunities that attempting to capture such information might bring:
The text within images can be difficult to automatically identify and recognize due both to problems with image quality and environmental factors associated with the image. Low image quality is produced, for example, by low resolution, image distortions, and compression artifacts. Environmental factors include, for example, text distance and size, shadowing and other contrast effects, foreground obstructions, and effects caused by inclement weather.
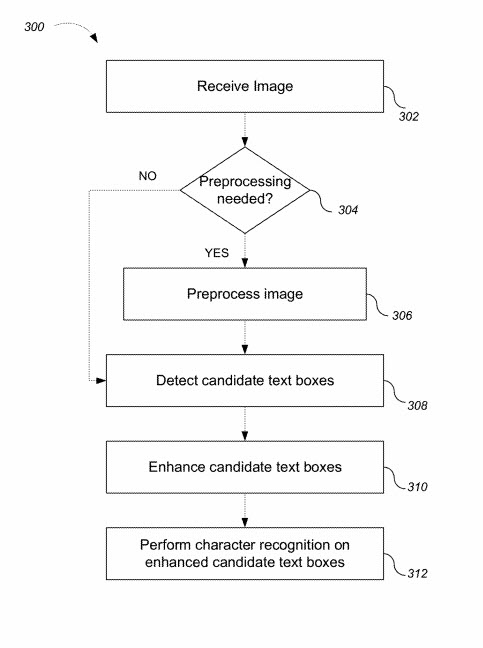
Systems, methods, and apparatus including computer program products for text identification and recognition in images are described. Text recognition and extraction from an image include preprocessing a received image, identifying candidate text regions within the image, enhancing the identified candidate text regions, and extracting text from the enhanced candidate text regions using a character recognition process. For an image showing an urban scene, such as a portion of a city block, the text recognition process is used to identify, for example, building addresses, street signs, business names, restaurant menus, and hours of operation.
The patent talks about attempting to identify regions on images that contain text and trying to use optical character recognition on those regions. This approach would then try to identify keywords from those images so that the images could be returned in response to keywords and presented to searchers.
The patent also describes another aspect of indexing words in images that might help improve it, by telling us that the extracted image text might be combined with location data (such as GPS data) and indexed to “improve and enhance location-based searching.” and the extracted text might provide keywords that can help identify particular locations and present images of those locations to a searcher.
For instance, a location might be extracted from an image such as this sign in front of the Batiquitos Lagoon, and GPS information associated with the image might be connected to it so that it could be returned on searches for that location (Batiquitos Lagoon).

The patent is:
Using extracted image text
Inventors: Luc Vincent and Adrian Ulges
Assignee: Google Inc.
United States Patent 9,542,612
Granted January 10, 2017
Filed: January 13, 2016
Abstract
Methods, systems, and apparatus including computer program products for using extracted image text are provided. In one implementation, a computer-implemented method is provided. The method includes receiving an input of one or more image search terms and identifying keywords from the received one or more image search terms. The method also includes searching a collection of keywords including keywords extracted from image text, retrieving an image associated with extracted image text corresponding to one or more of the image search terms, and presenting the image.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: