Table of Contents
Earlier this year, I wrote a post called Author Vectors: Google Knows Who Wrote Which Articles which was about a patent from Google that told us about Google’s potential ability to identify who the author of content on the web might be.
Google has been analyzing content from authors for a while, which can be seen in the Google Books N-gram Viewer There are a lot of features that you can use to explore the Books corpus of the many books that Google has scanned, and you can learn about the search features of the Google Books N-gram Viewer. This is because Google has carefully indexed the content of all the books in the project.
This patent made me wonder what the status of the Google Book Scanning Project might be. I found an article with a title that asked something similar: What Happened to Google’s Effort to Scan Millions of University Library Books? It appears that there are some other projects in addition to the N-gram viewer where information from the Google Books Project is being used.
Related Content:
The Author Vectors patent I wrote about showed that Google has been learning a lot about authors on the Web and possibly in the Google Books project. I searched for the authors of the Author vectors patent to see what else they had written and noticed that Brian Strope was the inventor on another patent about authors. That other patent showed how much they might know about other authors and what they could do with the author’s information. The Author vectors patent was supposed to help identify the authors of the content and make searches for content by those authors easier. This new patent shows confidence in how well they understand how specific authors might write.
I also want to point out a post that I collaborated with Lily Ray on about E-A-T, where we discussed how Google might learn to understand who the authors are of content that they might find on the Web, even in the absence of author bylines for that content. That post is The Mechanics of E-A-T: How Google Patents Can Help Explain How E-A-T Works
What Does this Author-Based Patent Cover?
Imagine that you would like to transform something you had written into another author’s style, such as William Shakespeare or Ernest Hemingway, or Stephen King?
This patent describes being about to do just that.
It could transform and classify text based on the analysis of training texts from particular authors. And Google has access to a lot of training data from over 25 million books, with the many scanned books in the Google Books Project. And there are many authors on the Web whom Google could study as well.
The patent could work with text authoring applications such as
- Word processors
- Email clients
- Web browsers
- Other applications
These applications accept text from users with keyboards or other input devices.
Some of those applications may analyze input text to identify common errors involving spelling, grammar, or formatting.
This patent covers technologies that can be used to rewrite the text in a requested linguistic style.
Advantages in following the process described in the patent
1.By letting someone transform input text to the style of a particular author, the input text may be changed to use words and phrases common for a particular type of writing associated with the target author, which may make it more likely that the text will be understood by an audience expecting that type of writing.
2. Input text may be transformed into a style expected by the audience for the text, making it more likely that the audience will well receive the text. For example, the input text could be transformed into a style used by an intended recipient of an email containing the input text based on email messages previously sent by the intended recipient.
3. An author of an input text may be able to improve the quality of the input text by transforming it to the style of a respected author, for example, in the case of an input text author who is not a native speaker of the language of the input text.
The patent about transforming text to different author styles is:
Text classification and transformation based on author
Inventors: Brian Patrick Strope and Matthew Steedman Henderson
Assignee: Google LLC
US Patent: 10,083,157
Granted: September 25, 2018
Filed: August 5, 2016
Abstract
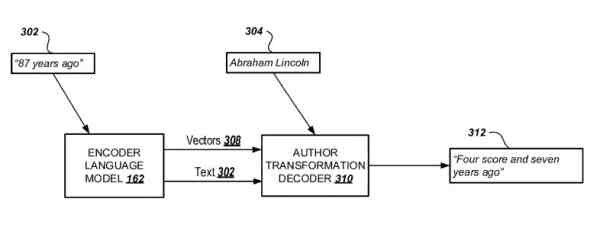
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for transforming and classifying text based on analysis of training texts from particular authors. One of the methods includes receiving an input text including one or more words and a requested author; generating a vector stream representing the input text based on an encoder language model and including one or more multi-dimensional vectors associated with associated words of the input text and representing a distribution of contexts in which the associated words occurred in a plurality of training texts; and producing an output text representing a particular transformation of the input text-based at least in part on a decoder language model, the generated vector stream, and the requested author.
Transforming Text to Shakespeare
This patent is about techniques using language models that have been trained with text from different authors to rewrite the text.
As an example, text provided by a user may be transformed into output text in the style of a particular author requested by the user.
That transformation could be performed using language models that have previously analyzed texts written by the particular author that models the words the author used in the context of those texts.
The language models could predict the most likely words the selected author would use in the input text and produce output text reflecting these predictions.
The output text is considered a transformation of the input text in the linguistic style of the particular author.
As an example, if you were given input text of “what is that light in the window,” and a requested author of “William Shakespeare,” the input text could be transformed into output text representing how William Shakespeare would have written the input text based on language models from analysis of his work.
The input text of “what is that light in the window” might be transformed into “what light through yonder window breaks.”
Transforming Text From Shakespeare
The patent provides another example, showing the opposite transformation (e.g., from “what light through yonder window breaks” to “what is that light in the window”) could be performed.
Such a transformation may be performed by using the William Shakespeare text as input text (with Shakespeare identified as the author of the input text) and by specifying the person requesting the transformation as the requested author.
The text would be transformed into the person’s style requesting the transformation based on previously analyzed and modeled text written by the person (e.g., emails, articles, etc.).
Other Author Style Transformations
As an example, someone may request input text be transformed into an author style that is common to a particular group of authors. This could be based on:
- Text produced by employees of a particular company
- Text by authors writing in a particular field
- Text by authors published in a particular journal
- Or other groups
In addition to using language models that have been trained with text from different authors, there are other potential results.
Input text using a particular author style could be classified as either “satire” or “non-satire.”
Or input text could be classified according to the most likely author to have written the input text.
Author Style Takeaways
This patent provides more details on how language models might be created from content created by other authors using some of the natural language processing approaches that Google has been developing. I shared this patent because I wanted to show off how comfortable Google has become with the idea that they could effectively transform content into content that uses an author style of a selected author or content that appears to have been written by someone from a specific company or who works in a specific field, or writes for a journal for a specific discipline. Google’s ability to use language models that can emulate specific authors or authors from specific niches or industries or with a certain level of expertise tells us about their comfort in building language models based on training content.
I wonder how Google might classify the content that I write or the content that others I know write. On the other hand, they do seem to understand authors fairly well now.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: