Table of Contents
How Are Author Scores Generated by Google?
Google’s patent covers ways to recommend posts in a messaging service to searchers who do not subscribe to posts and generates author scores.
Interestingly, this patent refers to author scores and refers to AuthorRank a few times. I first wrote about Agentrank in 2007, and over time it got referred to as both AgentRank and AuthorRank and Author Scores.
Situations change, and Google has lost its personal social network. We learn from the patent about messaging systems. The messages are from a micro-blogging application, where people can follow authors or subscribe to follow them. That would be at a place such as Twitter or Google+, and the writers are authors of posts.
Related Content:
- Technical SEO Agency
- Ecommerce SEO Agency
- Shopify SEO Services
- Franchise SEO Agency
- Enterprise SEO Services
The Author scores in Agentrank were for all content on web pages and not only on Micro-blogging platforms. This patent focuses on micro-blog content but think about it in blog posts and articles, too, because aspects of it may cover both.
The patent tells us:
This document generally describes recommending posts to non-subscribing searchers of a messaging service and scoring authors of posts.
Other Recent Patents About Authors
I have seen some other patents that tell us of authors followed and scored by Google at places such as blog posts and articles. I wrote about those in:
- February 21, 2020 – Google Using Website Representation Vectors to Classify with Expertise and Authority
- March 30, 2020 – Author Vectors: Google Knows Who Wrote Which Articles
- Jun 15 2020 – Ranking Search Results based on Information Gain Scores
- July 5, 2021 –Original Content and Original Authors Identified by Google
A messaging system can enable searchers of the messaging system to subscribe to posts from other searchers. This is so that when the other searchers submit posts (e.g., textual or multimedia messages), the posts go to a server system by the subscribing searchers. Each subscribing searcher may view a stream of posts, where the stream includes:
- (i) Posts from any subscribed authors
- (ii) Posts recommended by the messaging system for the subscribing searcher, even though the searcher has not subscribed to the post’s authors.
I haven’t seen this author scores patent implemented, or I would be using it. It’s good to keep an eye out for.
Why Posts Get Recommended
Recommended posts can include a short note or icon that identifies the post as a non-subscribed post. It may also include a reason that the post got recommended. It could also include an option that enables a searcher to revise recommendation settings associated with the reason for the recommendation.
A post can get recommended based on author scores of posts. Example signals used in scoring a post can include:
- Reputation of the post’s author
- Substantive post content
- Geographic location of the post’s author at a time of posting
- Number of comments on the post
- The Content of the comments
- Number of searcher-supplied indications of favorable searcher opinion of the post. These could be many searcher selections of a “like” interface element
The score of the post can get computed upon its posting and recomputed with every comment and like.
The Relationship Between Author and Searcher Might Determine Whether there is a Recommendation
In a social network graph, and author of the post and a searcher of the messaging system can determine if it gets recommended to the searcher. The social network graph can be a data structure that identifies relationships between searchers of the messaging service and the strength of the relationships.
A relationship can get created when a searcher:
- (i) Agrees to follow another searcher
- (ii) Comments on another searcher’s post
- (iii) From the messaging service becomes identified in another data set stored for the searcher. A data set such as an address book for the searcher that the messaging service can access or that the searcher provides to the messaging service
- (iv) Gets depicted in a photograph
- (v) Becomes considered geographically near each other at a particular time. These could be mobile telephones of each searcher that got located together at many different times)
- (vi) Emails or chats with each other frequently
- (vi) Interacts on third-party websites
The distance between two searchers gets based on the number of individuals necessary to connect the two searchers and the strength of each relationship in a chain of the connecting relationships.
Weighing the Author Scores of Posts
The distance between the two searchers can weigh the score of the post. The distance can weigh individual signals used in generating the score. Such as weighting a “number of following searchers” signal based on how related the following searchers concern the searcher. We learn that the distance can also calculate the thresholds necessary to recommend the post.
For example, the more distant the two searchers, the lower a post score by one of the searchers and/or a higher threshold level at which post scores by one of the searchers must surpass to be in the other searcher’s stream.
A post’s score can work with the reputational score of the post’s author. The reputational score can get calculated based on several criteria> For example, the number of searchers that follow the author and the quantity and quality of comments that the author receives on his posts.
The reputational score can work using a similarly computed reputational score of each searcher that follows the author. In other words, if authors with high reputational scores agree to subscribe to posts by a particular author, the particular author’s reputational score can be higher than if the following authors were not highly ranked.
Authors with High Reputation Scores
Some authors maliciously generate high-scoring posts. They may do this so that the posts will go to searchers that do not follow the malicious author. They may do this because they have limited success in increasing their score. After all, authors with high reputational scores may not be willing to subscribe to the malicious author and receive posts from malicious authors.
The malicious author may set up dummy accounts that provide favorable feedback on the malicious author’s posts and frequently comment on the malicious author’s posts. Still, instead, the dummy accounts are not likely to have high reputational scores. Thus, scoring posts based on an author’s reputation can be a particularly beneficial manner to prevent the messaging system from recommending posts from malicious searchers.
These author scores sound like they would work well with an earlier social network from Google, such as Google+. We may see future social networks again from Google. They have reentered their data sharing agreement with Twitter and have worked Twitter results into SERPs.
It’s difficult to tell if they have any plans to integrate other social sites into Google SERPs. It has been a while, so they may. When AgentRank, a reputation score, which reappeared in this patent, first came out, Google+ still had a few years before it would appear.
How the Author Scores Patent Works
A server system receives from many computing devices indications that a searcher of each computing device provided searcher input requesting posts that first searcher authors receive.
The server system receives from a first computing device a post that includes text, and that got authored by the first searcher of the first computing device.
The post can go from the server system to many computing devices.
A score for the post can meet the criteria for transmission to a second searcher who has not requested to receive posts authored by the first searcher.
The determination uses a distance of the second searcher to the first searcher in a social network graph.
In response to determining that the post score satisfies criteria for transmission to the second searcher, the post goes from the server system to a second computing device associated with the second searcher.
Personalized Author Scores for Posts
A search engine receives a query from many computers and requests to subscribe to posts authored by a first searcher. These authors get a personalized score for the post. The score is specific to a second searcher who has not requested posts that the first searcher authors.
The personalized score is from distances in a social network graph between the second searcher and the social network that the first searcher authored. The personalized score may exceed a threshold. This post goes from the server system to a second computing device associated with the second searcher.
Searcher input starts at a first computer that identifies many authors to which a first searcher subscribes. Indications of the many authors to which the first searcher is subscribing go from the first computing device to a server system. Many posts start at the first computing device and from the server system. The plurality includes:
- (i) Subscribed posts created by authors that the first searcher has subscribed to
- (ii) Recommended posts that the server system determined to meet criteria for transmission to the first searcher
The determination uses the distance of the first searcher to one or more other searchers in a social network graph. The plurality of posts is an integral stream of posts on a display of the first computing device.
The system includes a posting computerized device. A posting searcher transmitted a post from the posting computerized device to a server system. The system includes a first plurality of computerized devices.
The first plurality of searchers that have logged into the first plurality of computerized devices has requested to receive posts authored by the posting searcher.
The system includes a second plurality of computerized devices. The second plurality of searchers that have logged into the second number of computers has not requested to receive posts authored by the posting searcher.
The system includes a means to identify the second plurality as computerized devices to receive the post. The second number is devices that meet the criteria for receiving the post based on a score of the post and a distance of the second searchers to the posting searcher in a social network graph.
The system includes a re-transmission mechanism at the server system to receive the post from the posting computerized devices to send the post to the first plurality of computers to the second plurality of computers.
More Features of the Author Scores Patent
These and other implementations can optionally include one or more of the following features. The server system may not provide the second searcher posts that
- (i) Authored by the first searcher
- (ii) Associated with scores that do not meet the criteria
In response to receiving the requests, the server system may send to the number of computing devices all posts that the first searcher subsequently writes. The intended recipients of the post may not identify posts, the plurality of computing devices, or the searchers of the plurality of computing devices. The determination may use the distance of the second searcher to the first searcher in the social network to change the criteria.
The determination may use the distance of the second searcher to the first searcher in the social network to change the score. The score for the post may determine the number of comments that searchers have submitted in association with the post and comparing the number of comments to a historical quantity of comments that posts authored by the first searcher have received.
The social network graph may be a data structure that identifies, for several searchers that can transmit and receive posts, an acquaintance relationship of the searchers in the plurality to each other.
How Author Scores Recommendations Work within a Social Network Graph
The social network graph may identify, for each acquaintance relationship, a strength of the acquaintance relationship. The distance may work on:
- (i) The least number of acquaintance relationships to connect the first searcher and the second searcher
- (ii) The strength of the connecting relationships. The first post may include an identification of a posting location
The posting location may be within a threshold distance of the location of the second computing device.
Determining A Collection of Common Words Between Instances of Content
Transmitting the post to the second computing device may depend on determining that the criteria and determining that the posting location is within the threshold distance—a collection of common words between instances of content that the second searcher has generated or viewed.
Determining the collection of words may include not including in the collection w are in a pre-determined set of words; frequently used in a particular language. A determination may be that the post includes one or more words from the collection.
Transmitting the post to the second computing device may depend upon determining that the post includes one or more words from the collection.
Determining the collection of words may include identifying, as a word to include in the collection, a word from a query that the second searcher submitted to a search engine. Determining the collection of words may include identification, a word within a selected search engine result doc as a word to include in the collection.
The selected search engine result document may be a document that the searcher selected to view in response to a list of search results responsive to a search query that the searcher submitted. Generating the personalized score may work on distances in the social network graph between the second searcher and searchers of the social network that commented on the post that was from the first searcher.
The first searcher may not have subscribed to the authors of the recommended posts. The integral stream of posts may include every post of each author to which the first searcher has subscribed. The recommended posts may have been from authors to which the first searcher has not subscribed.
In general, one aspect of the subject matter described in this specification can be in methods, systems, and program products. A score for each of the number of authors of posts submitted to a server system gets made. The score for each author in the plurality is from a score of one or more authors in the plurality that have requested to subscribe to a stream of posts that the individual author submits to the server system.
A particular post submitted by a particular author in the plurality goes to the server system and a computing device. A score goes to the particular post based on the score of the particular author. The particular post is from the server system to computing devices associated with authors who have requested to subscribe to posts by the particular author.
Another aspect of the subject matter described in this specification gets embodied in a system. The system includes a computer-readable repository that stores scores for each of a plurality of authors of posts.
The system includes a transmission mechanism to receive a submission of a post from a particular author and to broadcast the post to authors who subscribe to posts submitted by the particular author. The system includes a means to determine a score for each author of the plurality of authors based on a score of one or more authors who subscribe to a stream of posts by the individual author.
Followed and Following Authors In a Social Network
In yet another aspect, the subject matter described in this specification works in a method. Data representing a plurality of authors comes from a server system. At least some of the authors are either, or both followed and following authors. Each of the following authors got subscribed to one or more of the followed authors, so about receive posts that get submitted to the one or more followed authors.
A score for each followed author gets made at the server system based on scores of the following authors who subscribe to the followed author. A particular post submitted by a particular author from the plurality goes through the server system. A determination that the past score meets the criteria for submission to recommended authors who do not subscribe to the particular author gets made.
The post goes from the server system to computing devices associated with:
- (i) Authors who subscribe to the particular author
- (ii) The recommended authors
These and other implementations can optionally include one or more of the following features.
The score for each author may be further based on many authors in the plurality who have requested to subscribe to the stream of posts that the individual author submits to the server system. The score for each author may be further based on many comments that reply to posts that the individual author submits to the server system.
Each comment is from a recipient of a distinct post to the server system for dissemination to other recipients of the distinct post. The score for each author may be further based on the quality of the comments. The quality of each comment may get based on the substantive nature of the text in the comment.
The score for each author may further get based on many selections by other authors of an interface element that accompanies a display of posts by the individual author and as viewed by the other authors.
The selection of the interface element indicates a favorable opinion of the post. At least one individual author has requested to subscribe to authors connected in a chain of subscribing authors back to at least one individual author. A score for the particular post that satisfies a criterion for transmission to a recipient that has not requested to subscribe to a stream of posts submitted by the particular ais gets determined.
The determining may use a distance of the particular author to the recipient author in a social network graph. The particular post and other posts go to a ranked author based on the scores of the posts. The particular post and the other posts from the server system may get received. The particular post and the other posts may show a computing device in a ranked order. Determining the score for each author of the plurality of authors may include weighting an impact of the score of the one or more authors based on a level of interaction of each of the one or more authors with the individual author.
The system may include a ranking unit to determine, for the particular author, a ranking of posts submitted by authors to whom the particular author subscribes, the ranking based on scores for the authors. The system may include an author scoring unit to determine a score for each of the plurality of authors based on the number of comments that each author receives on posts by the individual author.
The comments may be text postings submitted:
- (i) By other authors who receive posts by the individual author
- (ii) Responsive communications
The comments for each post get provided to a server system for dissemination to all authors who received the individual post. The system may include a plurality of computing devices that are each associated with an author of posts. Each computing device may include a display. Each display may present a ranked list of posts that are each associated with an author. Each list may get ranked based on the scores of the associated authors.
The following author may subscribe to a followed author by providing searcher input that identifies that the following author would like to receive each post submitted by the followed author to the server system as part of a micro-blogging service. The score for each followed author may be further based on many comments that go through the server system in association with posts that the followed offer submits to the server system.
Generating the score for each followed author may weigh an impact of scores of the following authors to the followed author based on the number of times that each of the following authors commented on posts that the followed author submitted.
Advantages of the Author Scores Patent
Particular embodiments get used, in certain instances, to realize one or more of the following advantages. Messaging services may recommend posts targeted to specific searchers of the messaging service. The recommended posts may be likely relevant to a searcher but maybe from authors that the searcher has not heard of or agreed to follow.
The recommended posts may be seamlessly integrated into a stream of posts for a display to the searcher, providing the searcher a single interface for viewing subscribed posts and recommended posts.
However, the recommended post may include a badge that indicates that the posts got recommended and were not submitted by an author that the searcher agreed to follow. A sign of a primary signal used to identify the post for recommendation may get displayed along with the post. The identification of the primary signal may include selectable interface elements that, upon selection, signal to the messaging service that the searcher should view additional or fewer posts from the primary signal. Displaying a reason for recommending the posts can build trust in the recommendations and the messaging service.
The addition of recommended posts allows posts that are particularly interesting to break into the stream of posts, even if the searcher wasn’t subscribed to an author of the recommended posts. The addition of recommended posts also enables searchers that follow few authors to remain engaged with the messaging service as their post streams may not dry up (i.e., appear empty).
A social network graph determining whether or not a post should appear as recommended allows the recommended posts to be more relevant than posts by individuals distant in the social network graph. Weighting the strength of relationships in the social network graph based on searcher interaction enables an effective mathematical “clustering” of individuals who interact frequently propagate on highly ranked posts to other searchers within this cluster.
Author Scores May Be Based in Part on the Scores of Authors Who Follow or Comment on the Followed Author
Scores for posts may be, in part, from reputational scores for the authors of the posts. The score for an author can be, in part, on the score of authors who follow or comment on the followed author. Thus, the “opinion” of authors associated with a high score is more valuable in determining author scores than the opinion of authors who are not highly ranked. The impact of a following author’s score on a followed author can depend on the interaction between the searchers.
Thus, “spam” authors may be less likely to bias the author recommendation system. Even if a spammer created dozens of searcher accounts and had all the accounts follow a particular author, the dozens of accounts are likely to have a low score and unlikely to impact the score of the followed author.
Additionally, the spammer is not as likely to log into each of the dozens of accounts and interact with the followed author’s posts. The authors’ reputational scores can be further based on a general level of interest (e.g., comments or likes) on posts submitted by the author. The general level of interest may not be specific to a single post but can be from activity over a series of posts over a period of time. Thus, the use of time-dependent statistical analysis can happen.
Passing forward reputational scores of authors can be particularly relevant because most micro-blogging service searchers are content generators and content viewers. Thus, authors (and thus the author’s posts) may get scored based on the activities of searchers that view the posts.
The details of one or more embodiments are outlined in the accompanying drawings and the description below. Other features, objects, and advantages will be apparent from the description and drawings, and claims.
Scoring authors of posts
Inventors: Todd Jackson, Andrew A. Bunner, Matthew S. Steiner, John Pongsajapan, Annie Tsung-I Chen, Keith J. Coleman, Edward S. Ho, Sean E. McBride, and Jessica Shih-Lan Cheng
Assignee: Google LLC
US Patent: 10,949,429
Granted: March 16, 2021
Filed: December 18, 2017
Abstract
In general, the subject matter described in this specification can be in methods, systems, and program products. A score for each of a plurality of authors of posts gets submitted to a server system. The score for each author in the plurality works on a score of one or more authors in the plurality that have requested to subscribe to a stream of posts that the individual author submits to the server system. A particular post submitted by a particular author in the plurality goes to the server system and a computing device. A score goes to the particular post based on the score of the particular author. The particular post goes from the server system to computing devices associated with authors who have requested to subscribe to posts by the particular author.
This Author Scores Approach Is About Recommending Authors
This document describes ways for recommending posts in a messaging service to search which does not subscribe to an author of the post for scoring authors. In general, a searcher of a computing device may submit short textual or multimedia posts to a server system that is hosting a micro-blogging service. The server system may disseminate the posts to computing devices of other people that use the micro-blogging service.
In particular, some people may “follow” or subscribe to the searcher so that when the server system receives a post from the searcher, the server system distributes the post to these other people. The post that comes from the searcher may not include information identifying these other people. The post may only include identifying an author of the post, which the server system may use to identify from a database the subscribing searchers.
The searcher may never send communication that identifies the subscribing searchers. The server system may only receive subscribing searchers’ identification in communication is from the subscribing searchers.
The other people that subscribe to the searcher may view the searcher’s post by logging into a website that displays, for each other people, a stream of posts that the micro-blogging service pushes to the person (i.e., a computing device that has gotten associated with the searcher). Each stream of posts may include posts authored by other searchers that the other person “follows” or “subscribes.” Also, the stream of posts can include posts that the micro-blogging service recommends for the other person, even though the other person has not affirmatively agreed to “follow” an author of the recommended posts.
One aspect of the messaging service relates to providing recommended posts to a searcher of a messaging service, where the searcher has not agreed to follow or otherwise subscribe to an author of the recommended posts. As an illustration, Bill (a searcher of a micro-blogging service) visits a website hosted by the micro-blogging service, creates a searcher account, and logs into the micro-blogging service using his new searcher account. The micro-blogging service for displaying a stacked list of textual posts target is unique to Bill’s searcher account. For example, Bill can use an account search feature to locate the searcher name and select a button that says “subscribe” or “follow.”
Subscribed Authors
In response, an electronic communication that identifies the friend as a subscribed author gets transmitted from Bill’s computing device to a server system that hosts the micro-blogging service. In this manner, Bill can subscribe to many searchers of the micro-blogging service. The server system may store identifications of the subscribed searchers so that Bill’s posts need not identify the recipients of the posts. The server can identify the recipients and distribute the posts accordingly.
After subscribing to the searchers, Bill returns to an inbox page of the micro-blogging service website. The inbox page may be empty because Bill just recently subscribed to searchers, so Bill decides to run out and grab groceries from the store. After Bill returns home from the store, he notes that the inbox includes several posts authored by searchers to whom Bill has subscribed. In particular, 43 minutes ago, Frank posted, “I love these tacos!, (Taco Warehouse),” and 12 minutes ago, Fabio posted, “If anyone wants to buy a car, let me know. I just crashed my sports car into a tree:–(, (Miami City Hospital).”
The inbox also includes a post that Fran posted 5 days ago. But, Carl (a searcher who received Fran’s post but is not a friend of Bill) commented on the post within the last 10 minutes, thus invoking a subsequent round of post distribution, this time with the comment included. Fran’s post states, “I love this restaurant, (Pizza Emporium)” and Carl’s recent comment states, “You are so right!!!, (Pizza Emporium).”
Should Recommenations be made Bases on Author Scores?
In addition to Frank, Fabio, and Fran (searchers that Bill explicitly agreed to follow), Bill’s inbox includes a single post by Ron. Bill does not follow Ron, and the micro-blogging service transmitted Ron’s post to Bill for display as a “recommended” post. Recommended posts may be posts determined to be of potential interest to Bill and accompanied by a badge or other graphical interface element that provides Bill a visual indication that the posts are not authored by a searcher that Bill subscribes to.
Each recommended post badge may accompany text that describes why the micro-blogging service recommended the post to Bill. For example, Ron’s post may accompany text stating, “Ron is a top poster in San Francisco.” Ron may often post from within San Francisco municipal boundaries, and Bill may have identified San Francisco as a home.
As Bill continues to use the micro-blogging service over the next few weeks, several dozen of the hundreds of posts in his inbox may be “recommended” posts. The micro-blogging service website may tell Bill why the posts got recommended to him, but Bill may otherwise not have any part in selecting the posts as recommended posts. Behind the scenes, however, a recommendation service can flag posts as recommended for Bill based on several criteria.
The Global Score Can Be From a Multitude of Signals
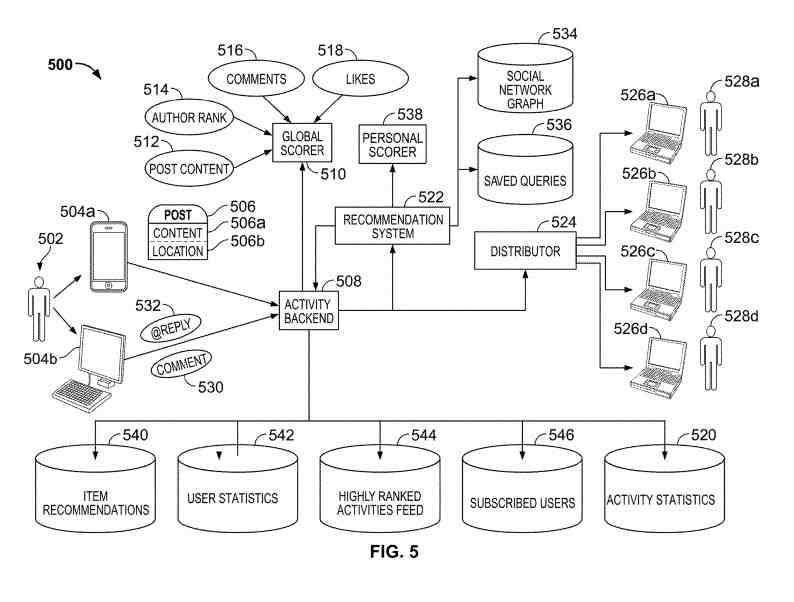
In some examples, every post submitted to the micro-blogging service got assigned a global score. The global score can be from a multitude of signals, for example, the number of comments that the post receives, several “likes” that searchers have selected for the post after viewing the post, and the reputation of the author of the post. The score for each post may get weighed against the position of the post’s author in a social graph to determine if the post should get provided to Bill as a recommended post.
A social graph can identify a distance of relatedness between two searchers of the micro-blogging service. For example, if Bill does not follow Ron, but Bill follows Frank, who follows Ron, Ron may be a “friend of a friend” of Bill, a “once removed friend” of Bill, or a friend with one degree of separation. The distance can be a minimum number of individuals connecting any two searchers of the micro-blogging service. For example, a distance of 1 can indicate the relationship between Bill and Ron (friend of friends), where a distance of 0 can indicate a relationship between Bill and Frank (direct friends).
Strenghts Between Relationships
In some examples, each relationship can have strength. For example, Bill and Frank may not interact much (e.g., by commenting on each other’s posts or sending a private message back and forth), so the strength of their relationship may be 0.3. Frank and Ron, however, may interact daily so that the strength of their relationship is 0.8. The strength of the relationships may modify the distance score or generate the distance score.
For example, the distance between Bill and Frank maybe 0.7 (0.3+0.8/2). The 0.8 strength may get divided by 2 to weigh the relationships that are farther away from Bill less than relationships that are closer to Bill. For example, each level of abstraction from Bill may decrease a weight applied to the strength of the relationship.
The social distance between Bill and other searchers can connect with a post’s global score to determine if a particular post should get provided as a recommended post for Bill. In some examples, a particular post’s global score (e.g., a post score that works on several factors and that may be for all searchers or a set of searchers) can get multiplied by, divided by, or summed with a distance between Bill and an author of the particular post to generate a modified score.
In some examples, the modified score may need to exceed a threshold value (e.g., 50) for the associated post to get recommended. In some examples, a post may need to have a modified score that is the highest-ranking over a given period of time (e.g., 30 minutes) to get identified as a recommended post.
Using both social distance and post scoring in recommending posts may increase the likelihood that recommended posts are interesting to the searcher. The posts may likely be interesting because of each post’s high score also because the post got submitted by some is close to the searcher in the social graph.
A close social graph distance between searchers can be useful in identifying the content of interest because searchers in social networks with similar interests may cluster together, subscribing to content feeds from searchers with similar interests. For example, Bill may be more interested in what his friends’ friends are saying than what a random searcher in Russia is talking about (even though the Russian searcher may be submitting posts scored higher than posts by Bill’s friends of friends).
A Personal Score May Use Any of Many Statistical Criteria Associated With the Post
In some examples, a personal score for each of Ron’s posts got created for Bill. The personal score may use any of many statistical criteria associated with the post. Still, instead of weighting an overall score based on a social network distance between Bill and Ron, the personal score may get made by weighting individual signals or factors that are subsequently combined to generate the score. For example, one of the dozens of signals that may generate a personal score for Ron’s posts may be the number of comments that the particular post has received.
This portion of the personal score may use a social network graph on a per comment basis. For example, if five comments for the particular post are from friends of Ron, this quantity of five comments may have a greater positive impact on the personal score for Ron’s post than if the five comments were from friends of friends of friends of friends of Bill.
Thus, instead of modifying a global score with a social distance, the “comments” portion of the score is itself calculated based on where in the social graph the searchers that supplied the comments are from concerning Bill. Similar signal-specific weighting can occur for other signals (e.g., many followers of Ron, number of likes that Ron receives, and whether the content in a post is similar to content by closely related friends of Bill).
Determining Author Scores
Another aspect of the messaging service includes determining an author’s score, which may be one of many factors in determining a score for a post and if the post should get recommended. The reputation of an author can be from several factors.
Example factors include:
- (i) Many comments that the author has received on his posts
- (ii) Several likes that the author has received on his posts
- (iii) Some followers that an author has
- (iv) A length of the comments made on the author’s posts
- (v) A length of the author’s posts
- (vi) Many unique commenters to the author’s posts
- (vii) Content of the author’s posts
- (viii) The Content of the comments to the author’s posts
- (ix) Score of pages affiliated with the author’s searcher account
- (x) Statistical information about whether the author gets associated with spam activity
Some of the factors from a history of the account, for a recent time period, or for an average of several recent time periods (e.g., an average count of comments received during a history of an account, during a past month, or an average of the amount received during each of the last 5 months).
An Author’s Score May Get Based On the Score of Authors Who Have Agreed to “Follow” the Author
An author’s score may get based, in part, on the score of authors who have agreed to “follow” the author so that the followed author’s posts get received in the following authors’ activity feeds. As an illustration, suppose that over a period of several months, Bill finds a niche submitting posts about odd happenings at his workplace, and several highly scored searchers agree to follow Bill (e.g., Britney Spears and Moby agree to follow Bill).
Assuming that Britney Spears and Moby are highly scored authors, Bill’s reputational score can get increased based on the high score of Britney and Moby. For example, Bill’s score may increase more than if two of his buddies from work were following him. This mechanism for weighting scores based on the scores of authors can utilize mechanisms from or similar to the well-known PAGERANK algorithm.
Weighting authors’ scores based on the scores of the following authors may combine PageRank concepts with distinctive and particularly relevant characteristics from a micro-blogging context. PageRank algorithms may base a document’s quality on the quality of documents that include a hypertext link to the document. As described in this patent, the authors’ scoring weights a reputational score of an author based on a score of the following authors.
An agreement to follow an author, however, may be more significant than a link between pages. When a searcher follows an author, that searcher may receive–in his activity feed–posts generated by the followed author. If unwelcome, posts from a followed author may be intrusive, and the searcher may choose to cancel his subscription to the author.
PageRank Scores v. Author Scores
On the contrary, placing a hypertext link on a web page may require little effort and may occupy only a few characters on a page designed to display to others (and thus may not impact the page author in the same manner). A quality of a webpage based on the PageRank mechanism may score the pages based on the opinions of other content generators (i.e., the authors of the webpages). In contrast, in a micro-blogging context, following searchers who are also individuals may be consumers of the content to which they subscribe.
Thus, a subscription may be a more valuable mechanism for transmitting scores than an unobtrusive link between pages. A subscription may be an active indication that one author enjoys the subscribed author’s content or is at least willing to have the content from the subscribed searcher forced into the subscribing searcher’s activity feed.
Additionally, the interaction between the following author and a followed author’s posts may get observed and used, connecting the following author and the followed author. If the following author “ignores” or filters from display the followed author’s posts, the connection may get weighed less. On the other hand, if the following author comments, likes, or clicks to expand or separately view posts of a followed author, the connection provided a greater weight. The weighting may also be from the number of posts that the followed author submits for dissemination to the following author.
Thus, if the following author posts dozens of times a day and the following author remains subscribed to the following searcher, the connection may get a greater weight if the followed author is posted every few months. The weights can determine how significantly a following author’s score impacts the followed author’s score.
Thus, not only do author’s scores propagate through a social network of micro-blogging authors based on an explicit agreement to view content generated by other authors, but the scores may originate based on feedback from other searchers (e.g., many comments on the following author’s own posts). A subscription may be a threshold for propagating an author’s score forward.
Still, an impact of the propagation can depend on the interaction between the following and followed searcher (e.g., the following author commenting on, liking, or viewing in non-summarized form the followed author’s posts).
An Example Web-Based Messaging System Interface
A searcher of the micro-blogging system after logging into the searcher’s account. The interface can enable the searcher to submit posts and receive posts from other people. In this illustration, Bill Johnson has logged into the messaging interface and is viewing a post from John Young in the content region of the interface. Tabs allow Bill to view differently filtered lists of posts. Bill can submit a post using the input area.
More specifically, Bill can visit the messaging interface with an internet browser by typing a URL associated with the portal into the address bar. Bill may enter his searcher name and password before he may use the interface. Upon having logged in, the searcher account that Bill is in may show in the interface window.
The searcher-selectable interface elements allow Bill to toggle the presentation of content in the content region of the interface. If Bill selects the “Mail” link, a list of received email messages may display in the content region. Selection of “Compose Mail” may invoke the presence of an interface for sending emails (e.g., by typing an address of a searcher, typing a subject, typing textual content, and clicking a submit button). Selection of the “Posts” link may invoke the micro-blogging service interface displayed in the content region.
The micro-blogging interface can display the name and picture of the searcher associated with the account. In this illustration, the name “Bill Johnson” gets associated with the searcher account “Bill” for the micro-blogging service domain “email.com.”
The input area of the micro-blogging interface may allow Bill to submit content for dissemination to other searchers of the micro-blogging service. For example, Bill may move a mouse cursor over the input area and click in the input area. Upon selecting the area, Bill may type a textual string of characters “I just had the best day ever, and want everyone to know it!” The characters may appear for display in the input area.
Adding Multimedia Content to a Post
The searcher selection of the input area may invoke a display of controls for adding multimedia content to the input area or for inclusion in the post. For example, graphical searcher interface elements may appear after Bill clicks in the input area. The graphical searcher interface elements may enable Bill to add a picture to a post or a video to the post, either by selecting a source file on his computer or identifying a source file from a location on the internet.
If Bill types or pastes a Uniform Resource Locator (URL) in the input area, a server system hosting the messaging interface (or code operating locally at Bill’s client device) may identify the string of characters as a URL and fetch content from the URL for inclusion in the post. For example, the messaging service may present a list of pictures drawn from a source document associated with the URL.
Bill can select a subset of the displayed pictures to include in the post that he is composing. Thus, a summary of the content drawn from a URL may display in the searcher interface. Bill may then select portions of the content to include in the post (e.g., individual pictures or text).
When Bill gets satisfied with the post that he has generated in the input area, Bill may select a “Post” graphical interface element. In this example, the “Post” interface element is not displayed in a screenshot and is provided for display upon a searcher selection of the input area. After selecting the “Post” interface element, Bill’s post may get transmitted by his client computing device to a server system that hosts the micro-blogging messaging service. The server system may identify searchers who have agreed to receive Bill’s posts and transmit an instance of Bill’s post to each searcher.
In some examples, the “post” may include only the textual and multimedia content visible to Bill or the textual and multimedia content. Thus, a person’s description of all post content may be from a person if the person can display a screenshot of either Bill’s display or a recipient searcher’s display. In other examples, the “post” includes additional information necessary to transmit the post and for the server system to handle the received post.
For example, the additional information may include an identifying number for Bill, a source uniform resource identifier (URI) for multimedia content, etc. The additional information may not be visible to Bill or recipient searchers. In some examples, a post does not identify searchers or searcher accounts to whom the post should go or get disseminated.
The Micro-Blogging Interface Also Displays Posts From Other Searchers
The micro-blogging interface also displays posts from other searchers. Such as a single post from the searcher John Young. John’s post may be the most recent post or most highly ranked post of several posts viewed by scrolling down in the interface using the scroll bar. John’s post can also be an “activity” because the post, while originating with content from John, may get expanded with content from other searchers of the micro-blogging service.
For example, in this illustration, John’s post included the title “My New House!” and a picture of his house. John’s post did not include any additional content and got submitted on the date of August 20.
John’s post got received by the micro-blogging service’s server system and disseminated to the other searchers of the micro-blogging service that had selected John as an individual they would like to follow. For example, Bill may have selected the “Contacts” link and entered into an input box John’s email address and name.
The micro-blogging service may have identified that John’s email address got associated with a micro-blogging account, and Bill may have requested to subscribe to John’s posts. In some examples, John got prompted to confirm that Bill may receive his posts before John’s posts get disseminated to Bill.
John’s post also shows that three people (Shawn, Mary, and Marty) “Liked” John’s post. A “Like” is any sign that the recipient has a favorable opinion of the post. A like may get invoked by a single-input searcher selection of a graphical interface element (e.g., the “Like” button).
John’s post also shows that on August 22, a searcher tagged or otherwise indicated that John Young was in the picture of the house. In this illustration, a searcher that tagged John is not identified. However, visual identification of a tagging searcher may show in some examples.
John’s post includes a display of a comment, “It is so Beautiful” by Elisa Locke at a time of 4:50 today. Elisa Locke may have received a display of John’s post in a micro-blogging interface like the one depicted. Elisa may have selected a comment button and entered the text “It is so Beautiful” into a comment input box. Upon sending the comment, John’s post may update to include Elisa’s comment (as illustrated in the post), and the updated post may be re-disseminated to all post recipients.
John’s post also includes an interface element that enables Bill to expand a display of John’s post to show comments from other searchers collapsed in the present view.
A Messaging Service May Provide Ways For Interaction Between Authors
The messaging interface includes mechanisms for Bill to interact with John’s post. For example, Bill may select the comment interface element. In response, searcher interface elements and controls may appear that enable Bill to generate and submit textual or multimedia content for inclusion in the post. The comment got distributed to all searchers that received the post so that when these other searchers view the post, they see Bill’s comment. The post may get updated for all searchers, whether the searchers have viewed the post previously or not.
Bill can also select a “Like” interface element to show his favorable opinion of the post. Selection of the “Like” interface element can impact the scoring of the post (potentially increasing the likelihood that the post will get displayed to other searchers as a recommended post), alert other searchers that Bill thought that the post was interesting, and would get used to developing a personalized model of posts that Bill likes (to aid in providing relevant content as recommended posts for Bill’s account).
Bill may add other people to the post. For example, Bill may select the “@ Reply” interface element. In response, graphical interface elements and controls may display that enable Bill to identify other searchers of the micro-blogging service. Other searchers may also get added to the post without Bill providing explicit searcher input to add them.
For example, Bill may tag “Bob” in a photo in the post, and Bob may get added to the post. Upon receiving identifications of these other searchers from Bill’s client device, the micro-blogging service may add the other searchers to a list of post recipients. Thus, John’s post may appear in the @replied searchers’ post streams. The new, @replied searchers may get enrolled as subscribed to the specific potters get informed or view all new activity on the post (e.g., comments, likes, content added by John, etc.) The new searchers may subscribe to the particular post but may not get subscribed to the post author.
In some examples, when an @replied searcher receives a post, the received post may indicate the searcher that shared the post with the @replied searcher. For example, the post may state, “Susan reshared this post with you.” A post can also display a history of sharing. For example, the post may state, “Susan reshared this post from Jill, who had reshared the post from Bob.”
As another option, Bill may email the post by selecting the email interface element and entering an individual’s email address. In response, the post content may get emailed to the individual’s email account. The recipient of the post content may not get subscribed to the post (as with an @reply where updates on the post content get viewed with the received email message). However, that may include a link or other mechanism that enables the searcher to subscribe to the particular post.
The Expand Op[tion So All ASsociated Content Is Seen
The “Expand” option may enable Bill to expand John’s post so that all content associated with the post (e.g., all content that he submitted, all comments, etc.) may get viewed at a single time in an expanded form. The post may increase in size within the interface or may appear as a separate “pop-up” box that is overlaid on the interface. In some examples, the post displays all searchers that get subscribed to the post, and whether the searchers subscribed to the individual post, follow the post author, were recommend to the post, or were @replied to the post.
In some examples, searchers can select additional features through the drop-down interface element. Example features can include an ability to delete the post from the searcher’s stream, ignore additional activity on the post so that the post does not jump to the top of the searcher’s stream with every comment, subscribe to the author of the stream, and unsubscribe the author of the stream.
As illustrated, John’s post may not be static text or multimedia content submitted by John for dissemination to other searchers. The searchers that received the post may be able to comment on the post, add content, tag people in pictures or videos, and add other searchers to the post. Thus, the post may also get referred to as an “activity” that originates with John as the author but may grow in content as other searchers contribute content to the activity.
The messaging system interface includes several Tabs for switching “views.” Each view may include a different set of posts. For example, each view may apply a different filter to the overall set of posts that Bill has received. The “All Posts” tab 108a may display all posts that the micro-blogging service has provided to Bill’s account (e.g., because he subscribed to the author or subscribed to the post or the post got recommended for display to Bill).
The “Subscribed searcher Posts” tab may display posts for authors that Bill has subscribed to but may not include a display of posts that became recommended for Bill. The “Recommended Posts” tab may include a display of posts that the micro-blogging system recommended for Bill but may not include posts for authors that Bill subscribed to. The “Posts Near Me” tab may include a list of posts submitted by searchers near Bill, either searchers that Bill subscribes to or all searchers.
For example, Bill may identify a home location or zip code in the settings of the messaging system, or Bill’s location may become identified through a Global Positioning System or another location-identification service that got associated with a mobile device upon which Bill is viewing the messaging interface. If a post (e.g., John’s post) is near Bill’s location, John’s post may appear in the “Posts Near Me” tab. The “Posts Near Me” tab may also get weighed by time so that only recent posts get displayed (e.g., so that the stream illustrates recent activity around Bill’s location). The “Posts Near Me” tab may identify locations of the recent posts as graphical interface elements overlaid on a map.
A Micro-Blogging Application Invoked for Display on a Mobile Telephone
The interface can include a picture of the searcher logged into the account and an input box for submitting posts associated with the searcher account. A present location of the mobile computing device may get displayed in the interface. The present location may get identified by location-identification services (e.g., GPS, cellular identification, or Wi-Fi identification). The present location may be coordinates, an address, or a venue (e.g., a commercial business or public place).
In some examples, the searcher can select his venue from a list of venues determined by a server system near an estimated geographical location of the mobile computing device.
The venues of interest box can display a list of venues near the mobile device’s estimated geographical location. Selection of the expansion interface element may invoke a display of detailed information for the venues of interest, or a display that enables selection of any of the venues of interest and subsequent display of detailed information (e.g., an address, map, hours of operation, website link).
The interface may include a display of several posts. Each post can include a picture of the poster, the name of the poster, the date of the post, a place of posting, and post content. The post content may include a summary of original post content. Additional post content by the author, comments by other searchers, and other post content may get displayed in response to a post-selection. Such as by tapping on the post.
In some examples, selection of the place of posting invokes a display of the location of the place of posting. Such as on a map. The interface for the application program may not get integrated with an email application (e.g., unlike interface).
A Part of a Post and an Associated Recommendation Indicator
The “Normal” View
The “Normal” view illustrates a post from Sergey that discusses Sergey’s trip to Alaska and includes a link to a webpage where the pictures may get viewed. A privilege interface element indicates that the post is “Public” and may become viewed by all searchers of the micro-blogging service. The post also includes a “Recommended” interface element that indicates a particular recipient of the post, not from an author to which the recipient subscribes.
The “Hover” View
The “Hover” view illustrates that the “Recommended” interface element includes underlined text upon a hovering of a mouse cursor over the text (e.g., to indicate to the recipient of the post that the text may get selected). In addition, the explanatory text “Why?” also appears.
The “Click” View
The “Click” view illustrates that, upon searching for the underlined “Recommended” interface element, a graphical dialog box expands and includes explanatory text. In this illustration, the explanatory text states that the post gets recommended “because . . . . This is popular with people you follow.” Other examples of explanatory text. The dialog box in the “Click” view also includes a link that, upon selection, allows the recipient searcher to indicate that he is not interested in viewing the particular post or viewing posts that got recommended based on the identified reason.
The “Dismissed” View
The “Dismissed” view illustrates explanatory text that may appear upon searcher selection of the “Not Interested” link.
The micro-blogging service may, in response to a searcher selection of the link, modify criteria so that
- (i) Posts similar to the displayed post are less likely to appear
- (ii) The recommendation criteria that got used to suggest the displayed post. so that the criteria described by explanatory text may not get used to recommend posts to the same particular searcher in the future
Different Explanatory Recommendation Dialog Boxes
Each dialog box illustrates explanatory text indicating a searcher why a particular post got recommended to the searcher and includes a “Not Interested” link. The text to the left side of each dialog box illustrates criteria that may get used to recommend a post that becomes associated with the dialog box to the right side of the text. In some examples, a post gets selected as a recommended post based on a high score. In response to the selection of the post, an analysis can get performed for the post (or the post’s score) to identify the primary criteria that resulted in the high score.
“Popular” Recommendation Dialog Boxes
The “Popular” recommendation dialog boxes may appear with posts that get recommended based on a high amount of post activity. For example, most of the recommended dialog boxes get displayed to a post recipient when the post becomes associated with a significant number of likes, comments, and @replies. The post may be “popular” with people in general or popular specific to a particular type of additional criteria. The additional criteria may be that the activity gets provided by subscribed searchers.
The additional criteria may be that the activity was popular with people having a similar interest (as with the dialog box). A similar interest may get identified based on standing queries, which get discussed below in this document.
The secondary criteria can also be people that share a location. A location can get identified as shared if an author of the post and the recipient of the post have gotten associated with the same location. A location can get identified if a:
- (i) Mobile computing device that has gotten used to read or transmit micro-blogging posts has supplied a particular location as a place of posting or a current place
- (ii) Searcher of the micro-blogging application has identified a particular place in micro-blogging service searcher settings as a home address or work address.
How to Get “Top Poster” Recommendation Dialog Boxes
The “Top Poster” recommendation dialog boxes may appear when an author of a post gets determined to be a top poster based on many likes, comments, and @replies that the author’s posts have received and based on the quantity and quality of followers of the author. In addition, the recommended post may get recommended because it is a particularly high-scoring post of the “Top Poster.”
As with the “Popular” recommendation dialog boxes, a “Top Poster” dialog box may be specific to when a top poster shares an interest with the recipient or when the top poster shares a location with the recipient.
In addition, a top poster may get recommended based on additional criteria, such as when the top poster is in the same public group as the recipient or when the top poster gets identified as associated with the same organization as the recipient. Additionally, within each top poster dialog, a link allows a searcher to select to follow the author of the associated post.
How To Get “Past Importance” Dialog Boxes
The “Past Importance” dialog boxes may appear when a recommendation gets based on historical comments, likes, and @replies that the recipient searcher has provided. For example, when a searcher likes, comments on, or @replies to particular posts, the post’s content may get analyzed (e.g., to create standing queries), and a source of the posts may become identified.
Thus, a future post recommends including content about a topic identified as relevant to the searcher or from a source that the recipient has previously commented, liked, or @replied. Both the same topic and the same source may get used in a recommendation (as with the dialog box).
Suggesting Other Authors to Follow
In some examples, an author of posts may suggest that another searcher follow the author or recommend that another searcher receive a particular post from the author. If the recommended post or author is highly ranked, the post may appear as a recommended post for the other searcher (as with the dialog box). The recommendation dialog box may appear with posts that are @replied to a particular searcher.
In some examples, the micro-blogging system determines that a particular post should get recommended to a searcher (e.g., because the post becomes associated with a high score). Still cannot identify a particular reason for recommending the post (e.g., because many factors are evenly weighted). In examples where a reason for recommending a post cannot get determined, the micro-blogging system may admit to the searcher that the post is being recommended for various reasons.
Reasons for Recommending a Post
Reasons for recommending a post may get determined based on which component of a recommendation engine provided a recommendation or based upon a weight of a signal in an overall score that got recommended. For example, a “same topic” recommendation may get based upon recommendations provided by a saved query recommendation engine. A post may be “Popular” if a threshold percentage (e.g., 40%) of a post’s score gets based on likes, comments, and @replies by other searchers, while a post may be of “Past Importance” if a threshold percentage (e.g., 40%) of a post’s score gets based on previous likes, comments, and @replies by the recipient of the post.
A Messaging System
The system may get used to recommend posts to non-subscribing searchers and to score authors of posts. A person author may use a computing device to submit a post to an activity backend server system. The activity backend server system requests that a global scorer generate a global score for the post and identifies searchers that subscribe to the author from a subscribed searchers repository.
A recommendation system gets queried to identify more searchers who receive the post associated with respective searchers. Any of the searchers may comment on the post, whereupon the post may get rescored and redistributed to the searchers and the author.
In more detail, the computing devices get illustrated as an application telephone and a desktop computer. Other example computing devices can include an in-dash car navigational system, a laptop computer, a netbook computer, a smart telephone, a personal digital assistant, a server, and a desktop telephone. The author types a post using one of the computing devices, for example, by typing on a physical keyboard or tapping keys of a virtual keyboard on a touchscreen display device.
Submitting Posts to Micro-Blogging Service
The author can submit the post to the micro-blogging service, for example, by pressing a “submit” button. The post may get transmitted over a network to the activity backend server system. The network may be a wired network (e.g., the Internet) or a wireless network (e.g., a mobile telephone communication network).
For example, the post may include content, for example, textual characters that the author entered with a keyboard and multimedia content that the author selected using the keyboard. The post may also include a location. The location may be data that identifies an estimated geographical location at which the post got submitted (e.g., geographical coordinates or a street address determined using GPS technologies) or a searcher-selected or confirmed venue that the post got submitted (e.g., a restaurant, mall, or city park).
The activity backend server system may receive the post and request that the global scorer server system determines a score for the post. The score for the post may get determined based upon several different signals (e.g., statistical data from different sources). Statistical data can get stored in a searcher statistics repository and an activity statistics repository.
Example signals include a post content signal, an author rank signal, a comments signal, and a like signal. Any combination of the signals may get used to determine a score for a particular post, and a combination may assign varying weights to the signals.
The Role of Comments in Author Scores
A “Comments” signal may get determined based on multiple different combinations of identified statistical information that relates to comments (or may represent several separate “comments” signals). For example, many comments that the post has received may get identified. The post may not have received any comments if the post is being broadcast for the first time by the author, but the post may have associated comments if rebroadcast after receiving comments or likes.
Several unique commenters may get identified. Thus, subsequent comments by the same commenter may become disregarded in scoring or provided less weight than an initial comment by a commenter.
The length of the comments may get identified, and the content of the comments may get analyzed. For example, comments that include 150 characters and multimedia content may count for more than a short comment that says “Awesome!” without any multimedia comment. Comments that become identified as spam or link to spam sites may get discounted. Comments may get analyzed against a historical amount of comments submitted by a particular searcher.
Hence, a relatively quiet search becomes weighted more heavily than comments by a searcher that comments on almost all posts that he receives. Comments for the post may get normalized against an average amount of comments that the searcher receives (either an absolute number or at a similar age of the post). Thus, even though a searcher may receive comments on a particular post, the post may not get associated with a score because the searcher may be particularly popular and typically receive several thousand comments.
How A Likes Signal Works in Author Scores
A “Likes” signal may get determined based on multiple different combinations of identified statistical information that relates to likes (or may represent several separate “Likes” signals). Statistical information specific to likes, but is otherwise similar to the statistical information described above for comments, may get used.
However, because a like may be a binary signal (e.g., either selected or not selected), the content of likes may not get analyzed as with comments. An activity statistics repository may include the described statistical information on comments and likes for the post.
Post Content and Author Scores
A “Post Content” signal may get determined based on multiple different combinations of identified statistical information that relates to post content (or may represent several separate “Post Content” signals). The length of the post may become identified, and post content may get identified. For example, a post that includes 120 characters of text and includes a link to www.cnn.com may get assigned a higher score than a post that includes 35 characters of text and a link to www.johnspersonalwebpage.com.
Thus, a website ranking by a search engine may get used to boost the score of a post (assuming in this illustration that www.cnn.com is more favorably ranked than www.johnspersonalwebpage.com). The inclusion of multimedia content (e.g., videos, pictures, or widgets) may increase the post’s score.
AuthorRank Returns
An “AuthorRank” signal may get determined based on multiple different combinations of identified statistical information that relates to an author’s reputation (or may represent several “AuthorRank” signals). AuthorRank gets discussed in more detail.
The activity backend may query the subscribed searchers repository to identify a list of searchers that have subscribed to the author or the post. The activity backend may subsequently request that the recommendation system identify searches that are not subscribed to the author or post and receive the post as a recommended post (such searchers get referred to herein as recommended searchers).
Author Scores as a Recommendation System
In some examples, the recommendation system identifies recommended searchers using statistical information. This can mean the global score or any combination of the signals, combined with a social network graph to determine particularly recommended searchers.
In general, the recommendation system may weigh a global post score, individual signals, or a threshold for a recommendation based on a distance between an author of a post and a potential recommended searcher. If a score for the post exceeds a threshold (either of which may get modified based on the social network graph distance), the post may get provided to the recommended searcher.
A Social Network Graph and Social Distance
An example social network graph and an explanation of a social network “distance” gets discussed. This illustrates a schematic illustration of an example social network. Each node identifies a member of the social network and each edge between the nodes represents a relationship between the members. Each relationship may get accompanied by a number that identifies the strength of the relationship.
As an illustration, node (“Mary” gets identified as directly related to nodes (“Susan”) and (“Frank”). Thus, Susan and Fraareget identified as friends or acquaintances of Mary, and the edged represent acquaintance relationships. An acquaintance relationship could become formed:
- (i) Either of the searchers requested to subscribe to another searcher of a micro-blogging service
- (ii) The other searcher acknowledged the request
- (iii) A searcher has commented on a post by another searcher of the micro-blogging service
- (iv) One of the searchers is in an address book stored for the other searcher. For example, Mary’s messaging system may have an address book that is independent of Mary’s subscriptions but identifies individuals that Mary has emailed or has stored as contacts of interest
Thus, several mechanisms may exist for generating an acquaintance relationship between searchers.
The Strenght Of Acquaintance Relationships
The strength of an acquaintance relationship may depend on the mechanism for generating the acquaintance relationship or a subsequent frequency and type of contact between the searchers. For example, a relationship where both searchers subscribed to each other may be stronger than a relationship where only one of the searchers subscribes to the other searcher.
A relationship where one of the searchers subscribes to the other searcher may be stronger than a relationship where the one searcher includes the other searcher in an address book of contacts but does not subscribe to the other searcher. A relationship where a searcher includes an address of the searcher in a contact book may be stronger than a relationship where a searcher once emailed another searcher but did not add that other searcher to his address book.
A relationship where a searcher commented a single time on a post of another searcher but did not subscribe to the other searcher may be stronger than a relationship where the searcher emailed the other searcher a single time.
The strength of the acquaintance relationship may depend on the frequency of contact between the searchers. For example, the frequency of contact can depend on how often a searcher emails another searcher, comments on the other searcher’s posts, like the other searcher’s posts, or @replies to the other searcher’s posts. The relationship may be stronger if both searchers interact with each other than if the interaction is only in one direction.
The strength of contact may depend on how recent the contact was. For example, Bill commenting on Frank’s posts 52 times three months ago may provide less of an impact on the strength of Bill and Frank’s relationship than Bill commenting on Frank’s posts 22 times in the last month. In social graph 600, the relationship between Mary and Susan has a strength of 27, and the relationship between Frank and Mary has a strength of 89.
A Distance Between Searchers
A distance between two searchers may not depend only on whether the searchers are acquaintances and the strength of the relationship. The distance can depend on how many edges it takes to reach the other searcher. For example, Susan and Frank may become considered “first-order” acquaintances of Mary.
“Second-order” acquaintances can include all acquaintances of the first-order acquaintances. For example, because Bill, Thomas, and Lindsey are acquaintances of Susan, and because Pizza Store, Lindsey, and Thomas are acquaintances of Frank, these individuals may be Mary’s second-order acquaintances. Third-order acquaintances may get determined similarly (as well as any n-th order acquaintances).
A distance may be a simple determination of the order of the acquaintance. For example, a first-order acquaintance may have a distance of 1, a second-order acquaintance may have a distance of 3, and a third-order acquaintance may have a distance of 9. Conversely, the distance may decrease value as the distance increases (e.g., 1, 0.33, and 0.11).
The Distance Value Between Two Searchers May Account For A Strength Of The Relationship
In some implementations, the distance value between two searchers may account for a strength of the relationship and to man relationships connecting the searchers. As an illustration, the distance between Mary and Thomas and Mary and the Pizza Store may get computed. Although numerous mechanisms for weighting distance become contemplation, the example strength number and a representation of the number of relationships are simply multiple in this illustration.
A distance between Mary and Thomas gets calculated as 1 (a numerical representation of the first-order relationship)*27 (the first-order strength)+0.33 (a numerical representation of the second-order relationship)*328 (the second-order strength)=166.
A distance between Mary and the Pizza store gets calculated as 1 (the numerical representation of the first-order relationship)*89 (the first-order strength)+0.33 (the numerical representation of the second-order relationship)*4 (the second-order strength)=90. In this illustration, even though Frank becomes identified as having a stronger relationship with Mary than Susan, Thomas has a stronger relationship with Mary than the Pizza Store because Susan and Thomas’ relationship is significantly stronger than Frank’s relationship with the Pizza Store.
Susan and Thomas may get married and frequently communicate, while Frank may have not communicated with the Pizza store and may only have the Pizza Store’s phone number in his address book.
In some examples, the distance becomes calculated based on the shortest number of relationships between two searchers. In some examples, two paths include the same number of relationships. For example, Lindsey is a second-order relationship of Mary through both Susan and Frank. Lindsey may get treated as though she is closer in the social network graph (e.g., associated with a higher distance value) than if she were only a second-order relationship through only Susan. For example, the distance through Frank may get multiplied by 2/3 and summed with 2/3rds the distance through Susan.
The Graph As A Social Network
While the social graph gets illustrated schematically, a computer may store the graph as a data structure. (The data structure that represents a social graph.) In this example table, each searcher gets associated with a row of the table. For example, Mary’s row 654 illustrates that she is an acquaintance of Susan with a strength of 27 and an acquaintance of Frank with 89.
As mentioned earlier, the calculated distance between an author and a searcher may get used to determine that the searcher should receive a post as recommended, even though the searcher does not subscribe to the author. For example, Mary may subscribe to Frank but may get related to Susan (also a searcher of the micro-blogging service) only through Mary’s address book. Also, Mary may not subscribe to any individuals depicted in the graph other than those illustrated as having a first-order relationship with Mary. Thus, the distance to the non-subscribed searchers may get used to determine if Mary should receive a post that the non-subscribed searchers author.
A Score For A Post
A score for a post, such as a global score for it. This scored can identify a personal score for an individual based on a distance between the individual searcher and the author of the post. For example, if Mary authored a post with a score of 24, the score may get personalized for Thomas and the Pizza Store based on the determined distance as discussed above. For example, the personal score of Mary’s post for the Pizza Store maybe 24 (post score)*90 (distance between Pizza Store and Mary)=2,160.
The personal score of Mary’s post for Thomas may be 24 (post score)*166 (distance between Thomas and Mary)=3,984. If the personal score exceeds a threshold value (e.g., 1,000), the post may get recommended to the searcher.
In some examples, the threshold is a fixed threshold or a fixed percentile of the total number of posts. For example, the top one percent of scores for posts may get recommended. In some examples, the threshold may differ depending upon the order of the relationship. For example, a first-order relationship may have a threshold of 1,000, and a second-order relationship may have a threshold of 3,000. Thus, Mary’s post may get recommended to Thomas (e.g., because his personal score of 3,984 exceeded the second-order threshold of 3,000) but may not become recommended to the Pizza Store.
Individual Signals That Calculate A Personal Score
In some implementations, individual signals that calculate a personal score for a post can get modified based on a distance between the individual searcher and the author of the post. As a simplified example, a personal score for Mary’s post may get determined based on many comments that the post has received (in a complex example, signals other than comments also get used.
In an illustration where the signals are not weighted based on a social graph, the comments score may become based solely on an absolute number of comments that the post has received divided by an average number of comments a post by the author typically receives. For example, if the post has received five comments and an average post by the same author receives two comments votes, the comment portion of the personal score may get assigned a value of 2.5.
Comments as An Example Of Social Author Scores
In a social graph illustration, author scores may get calculated based on scores for each comment. Each comment can become scored based on a distance between the commenter and the individual for whom the personal score is generated. For example, if Susan and Doug commented on Mary’s post, a personal score that gets generated for Thomas may be lower than if Susan and Lindsey commented on Mary’s post (e.g., because Susan and Lindsey are both first-order acquaintances of Thomas, where Doug is a fourth-order acquaintance of Thomas).
Each comment score calculation may get determined based on a score of the comment (e.g., quality of the comment, or a normalized value of the comment based on how many comments the commenter normally submits) in a mathematical combination with a social network distance between the searcher to whom the personal score is being calculated and the commenter.
In some implementations, a threshold value that gets used to determine whether a post is to become recommended to a searcher gets varied based on a social network distance between an author of the post and the searcher for whom the recommendation determination is being made. For example, a post may get associated with a global score of 90.
If the score for the post exceeds a threshold that gets calculated for a particular searcher, the post may become recommended to that particular searcher. As an example calculation of the threshold, a standing threshold may get divided by 2.3 (an example distance between two searchers) to provide 87. Because the global score of 90 exceeds the threshold of 87 (that gets calculated for the individual searcher), the post becomes recommended to the searcher. If the post’s score did not exceed the threshold, the post might not get recommended to the searcher.
A Personal Scorer Can Be A Server System or Set of Algorithms
A personal scorer can be a server system or set of algorithms that:
- (i) Modifies a global score generated for a post based on personal attributes. It can be a distance between the post author and an individual for whom the personal score is being created)
- (ii) Generates a personal score based on component scores that are each individually scored in combination with the use of a social network graph, as discussed in more detail above
In some implementations, posts get generated for a particular searcher based on one or more queries saved for the particular searcher in a saved queries repository. Each query can be a set of words or alpha-numeric characters that become identified as topically relevant to the content that the particular searcher has previously generated or viewed.
In some examples, the queries get generated based on searcher-selected options. For example, upon a particular searcher (e.g., Bill) opening his account or going into a settings page for his account, Bill may become presented with a survey or series of topical categories that Bill may identify as categories of interest. A word associated with each category may get added to a saved query for the searcher. For example, Bill may select a “Cars” option on a settings page and, in response, get presented with a list of various types of cars. Bill may select “Ford” as a sub-option. In response, the saved query for Bill may include the word “Ford.”
Micro-Blogging Service Analyzing The Content of Posts
In some examples, the queries get generated based on searcher-generated content or searcher-viewed content. For example, the micro-blogging service may analyze the content of posts submitted by Bill, posts that Bill reads, posts that Bill comments on, the content of Bill’s comments, or posts that Bill “likes.” Because the searcher account for the micro-blogging service may get shared among multiple different services that become provided by a single information provider, additional information may be available for use in a determination of a searcher query. For example, content emails that Bill receives, composes, or replies to may get analyzed.
In another example, search engine web queries that Bill submits may get analyzed. Also, landing pages associated with responsive search results may be analyzed. This is either for highly ranked search results or for search results that Bill selects. For example, Bill may navigate to a general-purpose search engine and type into an input box the query “Ford trucks longevity,”
In response, he may receive a list of search results that identify portions of content from landing pages that get determined to be responsive to the query. Landing pages may respond to the query if the landing pages include words included in the query or synonyms of the word included in the query.
Bill may select one of the search results, and Bill’s web browser may navigate to a landing page associated with the search result so that the landing page becomes displayed on Bill’s computing device.
Analyzation By Identification Of A Set of Common Words to Multiple Different Sources of Content
The content may get analyzed by identifying a set of common words to multiple different sources of content. These could be multiple different queries, landing pages, emails, posts, or a combination of these. Words from a repository of truncated words may get removed from the set of words. These could include the words “the,” “a,” and “there” may get removed as the truncated words. The repository of truncated words may include words commonly used in a language or dialect (e.g., the repository may include 500 most commonly used words in a particular language).
The repository of truncated words may also include words that were not determined to be of interest to searchers. For example, if the word “box” is not commonly used, but posts that become recommended based on the use of the word “box” are rarely “liked,” @replied, viewed in an expanded format, or commented on, the word box may get added to the truncated repository.
In some examples, the content of websites that Bill has generated may get analyzed. For example, Bill may become identified as the author of several different websites about “Jogging.” The websites may include text that describes jogging and links to other jogging websites. Saved queries may also get generated, in part, by analyzing the content of the websites that Bill can get identified as having generated.
A saved query for a particular searcher may get used in a query of posts submitted by searchers of the social network. In some examples, the query gets to run against posts within a pre-determined social network distance of a searcher. For example, the query may become performed against all authors of posts within a distance of 180 or are a third-order searcher or closer to a particular searcher. A post may be responsive to the query if the post includes the query terms.
A post may get scored based on the query terms using mechanisms similar to mechanisms employed for scoring landing pages in response to search engine queries. Posts may become selected by the micro-blogging service to recommend if the post gets identified as responsive to the query and within the particular social network distance. In some examples, posts may also need to have a query score above a threshold value. For example, if a long post includes a single reference to a query term, a query score for the post may not satisfy the threshold.
Searchers Recommended in a Subscribed Searchers Repository
The searchers recommended for a particular post may become added to the subscribed searchers repository as subscribed to the particular post. Thus, when the activity backend receives new activity for a particular post (e.g., comments on the post), the activity backend can identify all searchers to which the new activity should get provided. In this manner, all searchers who subscribe to the post author, all searchers that got recommended the post, and all searchers that were @replied to the post may receive updates on a post. When a post gets updated, it may jump to the top of a searcher’s post feed.
In some examples, searchers may submit an @reply and comment to the searcher’s own post. In some examples, the recipient searchers get treated as searchers when submitting a comment or @reply. In other words, the operations may be re-performed upon receiving a comment or like from searchers. The post (now with the comment) may get restored, and new recipient searchers may become recommendations. A highly ranked activities feed repository may include a list of posts associated with the highest global in some implementation scores.
Searchers of the micro-blogging service may subscribe to the highly ranked activities feed to view content that is globally identified as the most interesting.
The post may get submitted through a search engine query input box, for example, by typing “z. Hello World.” The “z.” character sequence may signify to a search engine frontend server system that the trailing text should get routed to a micro-blogging service server system for dissemination to other searchers.
A post may get routed from a different messaging service. For example, a searcher of the micro-blogging service may link his micro-blogging account to the TWITTER messaging service so that posts that he submits on his TWITTER account are also routed to the described micro-blogging service. Similarly, posts that the searcher receives from searchers on TWITTER may get routed into a feed for the micro-blogging service.
In some implementations, a server system includes all components that are not searcher devices (e.g., all components that are not devices.
In examples where postings from multiple of a searcher’s sources may get disseminated by the micro-blogging service (e.g., messages that post on the micro-blogging service and messages that the searcher posts to the TWITTER messaging service), individuals that follow the searcher may select a subset of the sources to follow for the searcher.
For example, if John subscribes to Bill, John may get presented a list of sources to which Bill’s account gets linked so that John may indicate which of the linked sources he would like to receive content from. Thus, John may indicate that he would like to view all content generated by Bill, except for content that Bill posts to TWITTER (e.g., because John may also separately follow Bill on TWITTER).
Determining the AuthorRank signal
The author reputation score determining engine can identify an AuthorRank signal the may get used as one of several factors for determining a score for a particular post. The AuthorRank signal may generally identify the trustworthiness of the author. The AuthorRank signal can get based on two broad categories of statistical information:
- (i) Other searcher’s interaction with the author’s posts and content that the author generates. Such as signals provided by the comment quality determination unit and signals
- (ii) Scores of searchers that have agreed to subscribe to the author (e.g., “Scores of Following searcher.”
The first category of signals (e.g., searchers’ interaction with the author’s posts and content that the author generates)bell get discussed first. The number of likes that an author’s posts receive may get used to identifying a reputational score for the author. For example, a total number of likes, an average number of likes per post, or an average number of likes over a particular time period (e.g., a week) may get used as an input to the author reputation score determining engine.
A similar analysis for the number of likes provided by unique searchers may get used (e.g., many individual people like an author’s posts over a time period, regardless of how many times a particular individual liked different posts). A similar analysis for a normalized number of likes may become used (e.g., a deviation from a historical trend of a particular individual).
The described statistical information may get analyzed for a life of a searcher account or particular time periods (e.g., the last 15 days). Similar forms of statistical analysis for several comments may calculate a reputational score for the author.
Many followers (i.e., many individuals that have agreed to subscribe to posts authored by the author) may get used in a determination of an author’s reputational score. Several “ignore” by searchers may decrease an author’s reputation. An “ignore” may be an identification that a searcher indicated that he does not wish to subscribe to the particular post or particular author anymore. Also, a spammer identification signal may get used in the determination of an author’s reputation score.
A spammer identification signal may indicate a likelihood that a particular searcher is a spammer. For example, the spammer signal may indicate if a searcher account gets associated with an IP address that has gotten identified as a source of spam if the account gets associated with an undue level of posting or activity, if the searcher’s posts or comments include words that have become identified as likely spam (e.g., “get rich quick”), or if the searcher’s posts or comments include links to web documents that have gotten identified as sources of spam.
Sources That Followers Subscribe to The Author to Determine The Author’s Reputational Score
In some examples, the amount of sources that each of the numbers of followers subscribes to the author gets used to determine the author’s reputational score. For example, some searchers may only subscribe to content that the author generates using the micro-blogging search. However, some of the searchers may subscribe to all content that the author generates (e.g., content that the author generates using the TWITTER messaging service). Thus, the more content that the followers subscribe may indicate a greater interest in the author and positively impact the author’s score.
Some examples of the searcher’s posts that get shared with other searchers (e.g., by @replying the searcher’s posts) influence searcher’s rankings. If a post that has already gotten shared with a searcher gets reshared (e.g., the individual that receives the @replied post decides to @reply the post to another individual), the post may be more heavily scored and may more favorably impact an author’s score than a post that was @replied a single time.
The comment quality determination unit may analyze the content of comments received on an author’s posts and provide statistical information to determine a reputational score for the author. For example, the comment quality determination unit may analyze the length of comments received on posts by an author, searcher-supplied ratings of the comments, and media included in the comments.
As an illustration, if an average comment that an author receives is several hundred characters long, highly rated, and includes pictures, an author’s reputational score may be higher than if the average comment was a short “Happy Birthday!” that was poorly rated and did not include multi-media content.
Statistical data on links that get included in comments that have gotten received on posts by the author may get analyzed to determine if the links are to spam documents (lowering an author’s reputational score) or gets associated with documents that become ranked highly by an internet search engine (increasing an author’s reputational score).
Statistics regarding the number of unique commenters, the number of responses to comments, and the frequency of commenting by each commenter may get analyzed. For example, if a post by an author receives comments from many different commenters (instead of the same commenters repeatedly), receives numerous comments to comments, and the commenters are infrequent posters or commenters, a reputational score of the author may increase. In various examples, a reputational score of an author may increase more if comments on the author’s posts get provided by highly-ranked authors than authors that are not highly ranked.
Numerous variations of the statistical information described herein may get analyzed to rank an author or rank a post associated with an author. For example, the trend analysis may get performed on a signal to identify if the signal is trending upwards or downwards. Time-dependency analysis may also get performed to identify a time of day, week, month, or year that an author receives increased interaction by other searchers with his posts.
Scores of Searchers That Have Agreed to Subscribe to The Author
The second category of signals, which are the scores of searchers that have agreed to subscribe to the author. In this patent, four searchers–Bill, Frank, Lindsey, and Hal –have agreed to follow the author. The reputational score for the author may not only get based on interaction with the searcher’s posts but also may become determined based on a score of authors that follow the author (e.g., scores 42, 17, 29, and 182).
The scores 42, 17, 29, and 182 get referenced by reference numbers, respectively. An understanding is that quality authors are more likely to subscribe to other quality authors and that quality authors may be unlikely to subscribe to low-quality authors or spammers.
Thus, high reputational scores get passed onto high-quality searchers. Author subscriptions may get considered a particularly relevant link to pass forward reputational scores because a searcher of the micro-blogging service may become forced to receive posts from subscribed authors.
The searcher may be unable to flag an author as subscribed and forget about the author. Indeed, the subscribed author’s posts may continue to pop up in the searcher’s feed, thus regularly reminding the searcher to reevaluate his decision to subscribe to the author.
Also, if an author begins to submit low-quality posts, those subscribing searchers that are inattentive (e.g., because they use the micro-blogging service rather infrequently) are unlikely to get associated with high scores that may positively impact a score of the author if passed forward.
Numerous mechanisms get contemplated for weighting an author’s reputational score based on the reputational scores of subscribing searchers. As a simple example, 50% of a searcher’s score may get determined based on any combination and weighting of signals and a signal from the comment quality determination unit (or signals that get fed to the unit), the remaining 50% of the searcher’s reputational score gets determined based on the scores of following authors.
The portion of the reputational score determined by subscribing author’s scores may be an average reputational score of the subscribing authors, a mean reputational score of the subscribing authors, a sum of the reputational scores by the subscribing authors, Anns, an author’s reputational score gets passed forward to authors that the searcher sees in some implementations.
For example, if a searcher with a high reputational score comments on another searcher’s posts (but does not subscribe to that searcher’s posts), the other searcher’s reputational score can increase, even though the searcher with the high reputational score may not subscribe to the other searcher’s posts.
Recommending Posts to Non-Subscribing Searchers
This author scores process may get used. Indications of a plurality of searchers requested to receive posts authored by first searcher authors become received. For example, over a period of time (e.g., several days or months), searchers of a micro-blogging messaging service may use various mechanisms to subscribe to a first searcher.
For example, searchers may search a directory of searchers of the micro-blogging service and select the first searcher as an individual that each subscribing searcher would like to follow.
In particular, the subscribing searchers may agree that all posts authored by the first searcher will get provided into a stream of posts displayed for each subscribing searcher. In response to each request to subscribe to the first searcher, an indication of the subscription request may get transmitted from a computing device to a server system that hosts the micro-blogging service.
The server system may store in a repository (e.g., repository 546) a list of the received subscription indications. The stored subscription indications may get received by the server system from the repository upon a later request to perform statistical analysis.
A post authored by the first searcher gets received. For example, from a computing device, the server system may review a post containing textual content. The first searcher may have used a virtual keyboard on a touchscreen of an application telephone computing device to enter a textual post into an input box and select a “post” graphical interface element. The application telephone may have transmitted the textual post to the server system.
A determination gets made that a score for the post satisfies the criteria for transmitting the post to a second searcher, where the second searcher is a searcher of the micro-blogging service that has not subscribed or otherwise requested to receive posts get authored by the first searcher.
For example, a score for the first post may become calculated, and the score may get transmitted to the second searcher if the score exceeds a threshold value.
The criteria get based on the distance of the first and second searchers in a social network graph. For example, the threshold that the score must exceed may get calculated based on a minimum number of acquaintance relationships that connect the first and second searchers or a distance between the first and second searchers. Example heuristics for determining a distance between two searchers get discussed in greater detail above.
The post score gets based on the distance of the first and second searchers in a social network graph. For example, a global score for the post may become modified to generate a personal score based on a distance between the first and second searchers.
In other examples, the personal score gets generated by weighting various statistics based on a social network distance between the second searcher and a source of the statistic (e.g., a distance between the second searcher and another searcher that commented on the first searcher’s post).
The post gets transmitted to the second searcher. The transmission may become performed in response to determining that the score satisfies the criteria. For example, the server system that hosts the micro-blogging service may transmit the post that it received from the first searcher’s computing device and distribute the post to a computing device that gets associated with the second searcher.
Transmitting to the second searcher means sending it to a computing device at which the second searcher logged into a searcher account that is unique to the second searcher and is for the micro-blogging service.
The server system transmits the post to the plurality of first searchers (i.e., the searchers that subscribe to the first searcher).
A score for post authors gets determined. The author score may get determined based upon two collections of statistical information, a score of searchers that follow each post author and interaction by other searchers with the author’s posts.
A score for an author becomes determined based on a score of searchers that have agreed to follow the author. For example, if the following author gets associated with a high author score, that high score may have a beneficial impact on the followed author. In some examples, the impact of the following author on a score of a followed author depends on the amount of interaction between the authors.
For example, if the following author with a high score follows two authors and communicates with one of the authors more than the other, the followed author that receives frequent communications from the following author can receive a greater boost in his own score than the other author.
Author scores get based on a combination of:
- (i) Many comments that the author’s posts receive
- (ii) The quality of comments that the author’s posts receive
- (iii) A quantity of “likes” that the author’s posts receive
Author scores may increase if the posts:
- Over the last two months have received an average amount of comments that is greater than the average of all searchers
- Have received comments that have a longer average length than the average comment length of all
- Earned a quantity of “likes” from unique searchers greater than an average quantity of likes from unique searchers that get received on posts by searchers of the messaging system
A particular post submitted by a particular author gets received. For example, a server system hosting the micro-blogging service may receive a post from a searcher of the micro-blogging service.
Author scores get assigned to particular posts based on the scores of the authors. Additionally, the score for the particular post can get weighted based on any combination of:
- (i) Content of the post
- (ii) Searcher comments for the post
- (iii) Content of the comments
- (iv) Searcher likes for the post
As an illustration, 60% of the score for a post may get determined based on the combination of (i), (ii), (iii), and (iv), while the remaining 40% of the post’s score may become based on a reputational score of the author of the post. Various mechanisms get contemplated for weighting the described factors and assigning the score to the post.
The particular post gets transmitted to the following authors. For example, the post may become transmitted from the server system to computing devices associated with each of the following searchers. These are computing devices that the following searchers log into.
In some examples, the post is only transmitted if the post score exceeds a predetermined threshold. In some examples, the post score gets transmitted with the post so that the computing device may rank the posts in an order based on their scores or allow the searcher to filter out low-scoring posts.
Various Author Scores Features May Get Implemented
In general, the system permits various searchers to post, review, and comment on various activity streams of information, within a social networking framework. For example, a searcher may make a micro-blogging post about a recent happening in the searcher’s life or about a news article the searcher recently read.
That post may get forwarded to other searchers who have chosen to follow the first searcher (an individual or an organization). Those other searchers may see the post using a stream reader, or the post may get displayed in their email applications (e.g., either in line with their regular email messages or under a separate tab).
Those searchers may choose to comment on the post, and other searchers may also comment on the post or comment on the comments of other searchers. Such comments may become included and shown in the various searchers’ email applications even if they get made after the post was originally connected to the email application.
Thus, the various types of feedback may get made available to each searcher conveniently in one place. Searchers may also see posts related to other searchers my visiting profile pages for those other searchers and may also go to their own profile pages or to their stream pages to see all of the posts and comments for posts to which they become subscribed.
The various posts, and comments on posts, get managed in the system by an activity streams backend, which is in charge of implementing business logic that defines how various submissions to the system will get handled.
The activity streams get characterized by activities, which are the subjects of posts (e.g., micro-blog posts) that searchers submit to the system, and various comments directed toward those activities. For example, a searcher may post an activity regarding a web page they are currently viewing by pasting a URL of the page into a posting page.
Author Scores Patent Conclusion
This patent looks like it ideally would have gotten released when Google was running a social network such as Google+. Nothing says they might not start up a new social network. Ideas like the reputation scores that are Agent Rank may appear again. We have seen references to author scores a few times. When you get logged into a Google account and take actions that may last on the web, such as using a Google Account to search or comment, Google knows who you are.
We have seen references to authors in places such as the quality raters guides to Google Search. Those Guides place a lot of value on authors and author scores. There may not be one single Expertise-Authoritativeness-Trustworthiness score at Google. However, many signals look like they could fit with those, including author scores.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: