Table of Contents
Running a Style Guide
One thing I’ve run across and have recommended in the past has been the use of a style guide. I first heard the concept at a University that I was doing SEO for. The Dean of the School didn’t like one phrase and insisted on another, which was one of our main keywords phrases for the site. It’s good having a place to keep track of preferences like that, and other approaches that may apply to a site. I’ve recommended a style guide for sites recommending things like the future use of all lower case letters in URLs for sites. Go Fish Digital doesn’t have a style guide, but it has a wiki where we include information about specific techniques that we use on our site, and client sites as well.
Related Content:
- Custom Website Development Services
- Custom WordPress Development Services
- Custom Shopify Web Development Services
Anchor Text Indexing Updated at Google
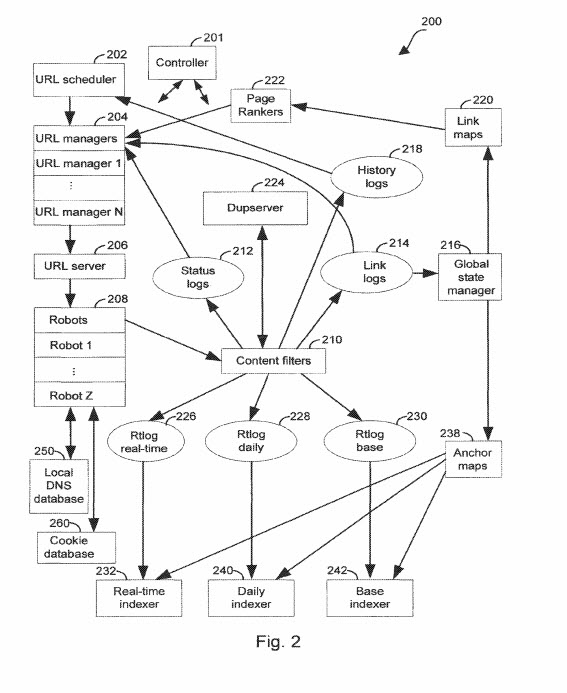
I’ve added a few things to our wiki, and have a couple more things to add to it. The latest addition will be something I saw in a continuation patent which just came out, updating a Google patent which was originally filed in 2003 by the search engine (which I wrote about originally in 2007 when it was granted the first time.) It involves an aspect of SEO which is familiar to most people doing SEO, about the use of anchor text indexing. I have heard rumors that Google was using this new approach in the past, but hadn’t seen anything about it in writing until very recently, in the claims section of this new patent. The patent in question is one that has the head of the Google Brain Team as an inventor, Jeff Dean. He is also one of the inventors behind the Reasonable Surfer Patent, which paid more attention to the probability that someone might click on a link, to use to determine PageRank Weight
The latest version of this updated patent on anchor text indexing can be found here:
Anchor tag indexing in a web crawler system
Inventors: Huican Zhu, Jeffrey Dean, Sanjay Ghemawat, Bwolen Po-Jen Yang, and Anurag Acharya
Assignee: GOOGLE LLC
US Patent: 10,210,256
Granted: February 19, 2019
Filed: April 1, 2016
Abstract
Provided is a method and system for indexing documents in a collection of linked documents. A link log, including one or more pairings of source documents and target documents, is accessed. A sorted anchor map, containing one or more target document to source document pairings, is generated. The pairings in the sorted anchor map are ordered based on target document identifiers.
Annotation Text Near Anchor Text New to this Patent
One of the noticeable things that is new in the claims in this continuation patent is the mention of Annotation text, within a certain distance from anchor text for a link, which could influence what a page that is being linked to maybe about. I’ll include some of these new claims in the newest version of this patent that refer to annotation text:
What is claimed is:
1. A system comprising: at least one processor; an index for searching documents, the index including terms associated with documents; and memory storing instructions that, when executed by the at least one processor, perform operations including obtaining, via a web crawler, a source document, identifying, in the source document, annotation text, the annotation text being text within a predetermined distance of an outbound link to a target document and the annotation text including at least one term, storing in the index an association between the term and the source document, storing in the index, responsive to identifying the annotation text, an association between the term and the target document, identifying, responsive to receiving a query that includes the term, the source document and the target document as associated with the term in the index, responsive to identifying the associations, including the source document and the target document in a list of documents responsive to the query, and returning the list of documents responsive to the query as a search result for the query.
2. The system of claim 1, wherein the target document has not yet been crawled.
3. The system of claim 1, wherein the outbound link is an anchor tag in the source document and the annotation is anchor text associated with the anchor tag.
4. The system of claim 1, further including an anchor map accessed by an indexer, the anchor map including at least one entry that identifies: a respective target document; a plurality of source document identifiers, wherein source document includes an outbound link to the respective target document; and at least one annotation for each source document identifier, the annotation includes a text passage extracted from a respective source document, wherein the text passage is within a predetermined distance of a respective outbound link.
5. The system of claim 4, the anchor map further identifying an attribute of at least one annotation.
6. The system of claim 1, wherein the annotation is a continuous block of text from the source document.
7. The system of claim 1, wherein the annotation includes text outside of an anchor tag in the source document.
8. The system of claim 1, the memory further storing instructions that, when executed by the at least one processor, perform operations including: computing a query-independent relevance metric for the target document, wherein the query-independent relevance metric includes a sum of partial query-independent relevance metric contributions from each source document that includes an outbound link to the target document.
The Oldest Version of this Anchor Text Indexing Patent
I wrote about the earliest version of the anchor text patent back in 2007 in the post Google Patent on Anchor Text and Different Crawling Rates. It was very informative about how Google crawled webpages and indexed them at different rates, and handled redirects of different types.
The newest version of the patent includes an updated process which I didn’t write about in that earlier version, in the post I wrote 12 years ago.
Since I included some of the claims mentioning association text near anchor text, I should show you the claims from the oldest version of the patent, Anchor Text Indexing in a Web Crawler System (Filed July 3, 2003). Here are the first 8 claims from that version of the patent (compare these to the 8 above from the newest version):
What is claimed is:
1. A method of processing information related to documents in a collection of linked documents, the method comprising: accessing a link log, the link log that comprises a plurality of link records, each link record identifying a source document and a list of one or more target documents pointed to by one or more outbound links in the source document; the link record including a source document identifier for the identified source document and one or more target document identifiers for the identified list of target documents; wherein the link records are based, at least in part on information extracted from crawled documents in the collection of linked documents; and outputting a sorted anchor map that corresponds to the link log and that comprises a plurality of anchor records, each anchor record identifying a respective target document and a list of inbound links, the list of inbound links identifying source documents that contain links to the respective target document; the anchor record including a respective target document identifier; wherein the plurality of anchor records are ordered in the sorted anchor map based, at least in part, on their respective target document identifiers; and wherein each respective target document identifier in the plurality of anchor records corresponds to one of the one or more target document identifiers in the link log.
2. The method of claim 1, wherein each anchor record in the sorted anchor map further comprises a respective list of annotations.
3. The method of claim 2, wherein each annotation included in the respective list of annotations for a respective anchor record corresponds to a respective inbound link identifying a respective source document that contains a link to the respective target document.
4. The method of claim 2, wherein at least one entry in the respective list of annotations of an anchor record in the sorted anchor map includes a text passage and a list of attributes of the text passage.
5. The method of claim 4, wherein the text passage is determined from text within a predetermined distance of an anchor tag in a respective source document in the source documents of the anchor record.
6. The method of claim 1, further including repeating the accessing and outputting to produce a layered set of sorted anchor maps.
7. The method of claim 6, further including, when a merge condition has been satisfied, merging a subset of the layered set of sorted anchor maps to produce a merged anchor map; wherein the merged anchor map includes a plurality of merged anchor records, each merged anchor record corresponding to at least one anchor record from the subset of the layered set of sorted anchor maps, wherein the merged anchor records are ordered in the merged anchor map based on their respective target document identifiers.
8. The method of claim 1, further including outputting a sorted link map, the sorted link map comprising a plurality of link map records, each link map record comprising the source document identifier and the list of target document identifiers in an associated link record.
introducing Annotation Text to Anchor Text indexing
Note the mentions of annotation text in the new claims for this patent. Considering that the patent was updated to reflect the process that the patent is intended to protect, and exclude other search engines from using, that makes the idea of adding annotation text near anchor text very interesting to me. The patent doesn’t provide an exact roadmap on how to use annotation text with links but does provide enough information to make it interesting as something worth experimenting with.
And adding to a style guide for content creators to consider using when they create content that contains links to other pages that they may want to have ranked for terms included in that annotation text.
SEO may be evolving towards a more semantic process involving Schema and knowledge panels, but we also are seeing updates to how things originally filed in patents back in 2003 like anchor text usage may be updated as well.
Good linking to you.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: